 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Tubule-Sensitive CNNs for Pulmonary Airway and Artery-Vein Segmentation in CT
Dec 10, 2020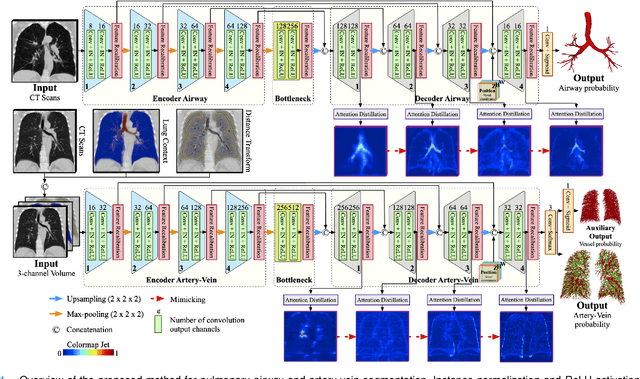
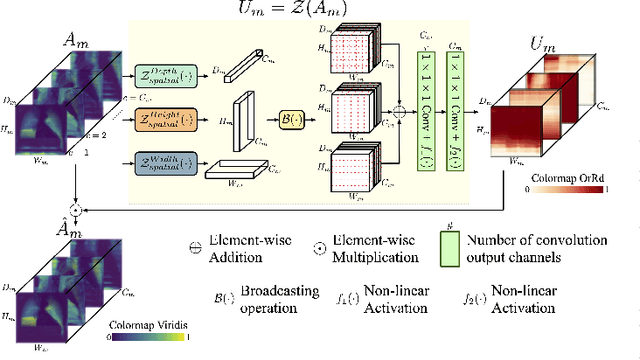

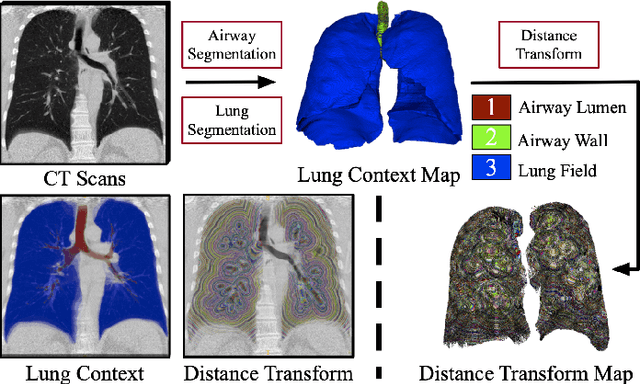
Training convolutional neural networks (CNNs) for segmentation of pulmonary airway, artery, and vein is challenging due to sparse supervisory signals caused by the severe class imbalance between tubular targets and background. We present a CNNs-based method for accurate airway and artery-vein segmentation in non-contrast computed tomography. It enjoys superior sensitivity to tenuous peripheral bronchioles, arterioles, and venules. The method first uses a feature recalibration module to make the best use of features learned from the neural networks. Spatial information of features is properly integrated to retain relative priority of activated regions, which benefits the subsequent channel-wise recalibration. Then, attention distillation module is introduced to reinforce representation learning of tubular objects. Fine-grained details in high-resolution attention maps are passing down from one layer to its previous layer recursively to enrich context. Anatomy prior of lung context map and distance transform map is designed and incorporated for better artery-vein differentiation capacity. Extensive experiments demonstrated considerable performance gains brought by these components. Compared with state-of-the-art methods, our method extracted much more branches while maintaining competitive overall segmentation performance. Codes and models will be available later at http://www.pami.sjtu.edu.cn.
Batch Group Normalization
Dec 09, 2020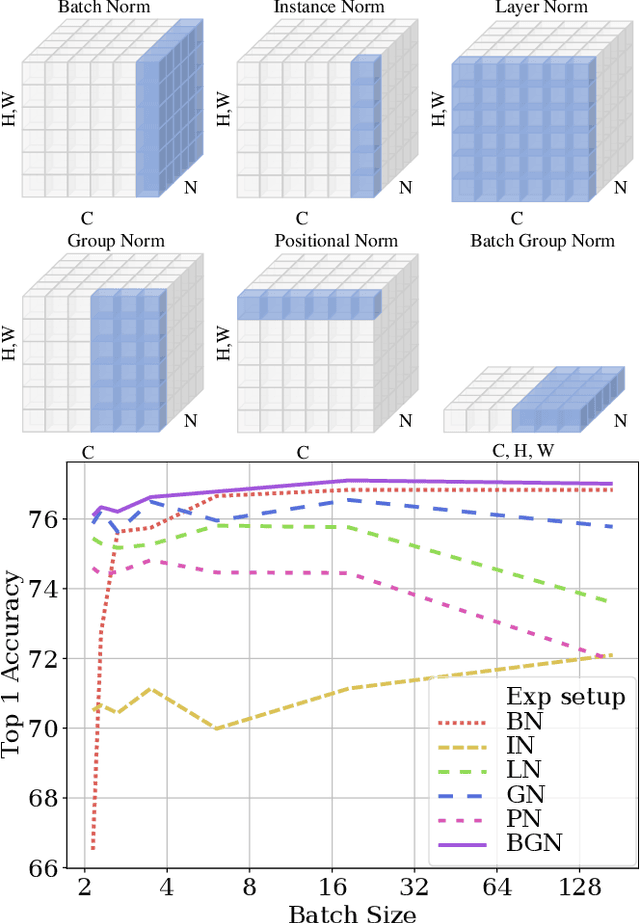

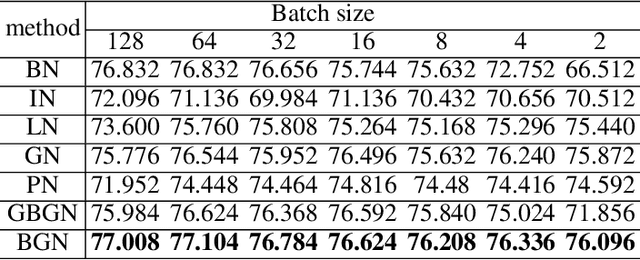
Deep Convolutional Neural Networks (DCNNs) are hard and time-consuming to train. Normalization is one of the effective solutions. Among previous normalization methods, Batch Normalization (BN) performs well at medium and large batch sizes and is with good generalizability to multiple vision tasks, while its performance degrades significantly at small batch sizes. In this paper, we find that BN saturates at extreme large batch sizes, i.e., 128 images per worker, i.e., GPU, as well and propose that the degradation/saturation of BN at small/extreme large batch sizes is caused by noisy/confused statistic calculation. Hence without adding new trainable parameters, using multiple-layer or multi-iteration information, or introducing extra computation, Batch Group Normalization (BGN) is proposed to solve the noisy/confused statistic calculation of BN at small/extreme large batch sizes with introducing the channel, height and width dimension to compensate. The group technique in Group Normalization (GN) is used and a hyper-parameter G is used to control the number of feature instances used for statistic calculation, hence to offer neither noisy nor confused statistic for different batch sizes. We empirically demonstrate that BGN consistently outperforms BN, Instance Normalization (IN), Layer Normalization (LN), GN, and Positional Normalization (PN), across a wide spectrum of vision tasks, including image classification, Neural Architecture Search (NAS), adversarial learning, Few Shot Learning (FSL) and Unsupervised Domain Adaptation (UDA), indicating its good performance, robust stability to batch size and wide generalizability. For example, for training ResNet-50 on ImageNet with a batch size of 2, BN achieves Top1 accuracy of 66.512% while BGN achieves 76.096% with notable improvement.
End-to-End Real-time Catheter Segmentation with Optical Flow-Guided Warping during Endovascular Intervention
Jun 16, 2020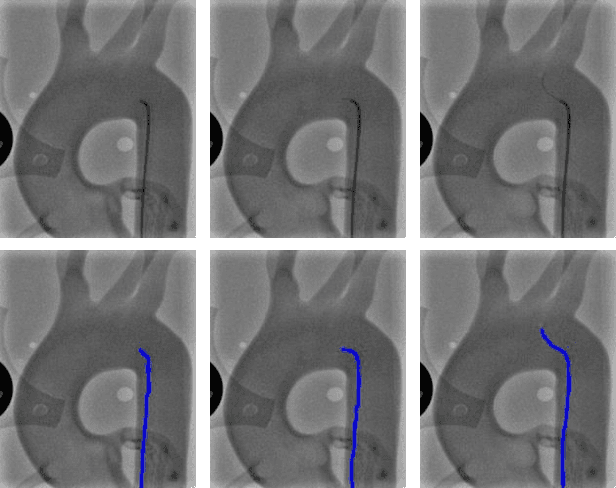

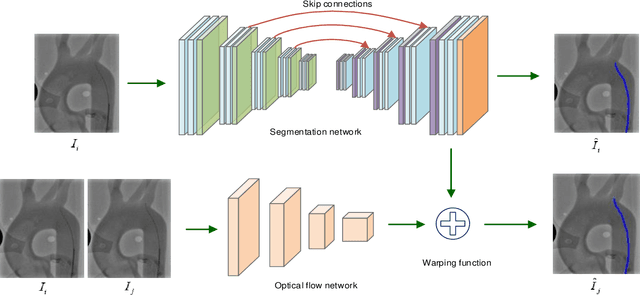
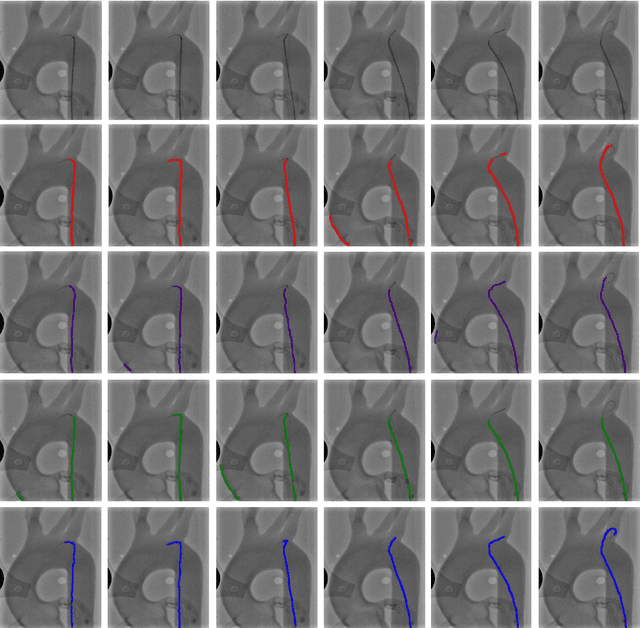
Accurate real-time catheter segmentation is an important pre-requisite for robot-assisted endovascular intervention. Most of the existing learning-based methods for catheter segmentation and tracking are only trained on small-scale datasets or synthetic data due to the difficulties of ground-truth annotation. Furthermore, the temporal continuity in intraoperative imaging sequences is not fully utilised. In this paper, we present FW-Net, an end-to-end and real-time deep learning framework for endovascular intervention. The proposed FW-Net has three modules: a segmentation network with encoder-decoder architecture, a flow network to extract optical flow information, and a novel flow-guided warping function to learn the frame-to-frame temporal continuity. We show that by effectively learning temporal continuity, the network can successfully segment and track the catheters in real-time sequences using only raw ground-truth for training. Detailed validation results confirm that our FW-Net outperforms state-of-the-art techniques while achieving real-time performance.
FBG-Based Triaxial Force Sensor Integrated with an Eccentrically Configured Imaging Probe for Endoluminal Optical Biopsy
Jun 11, 2020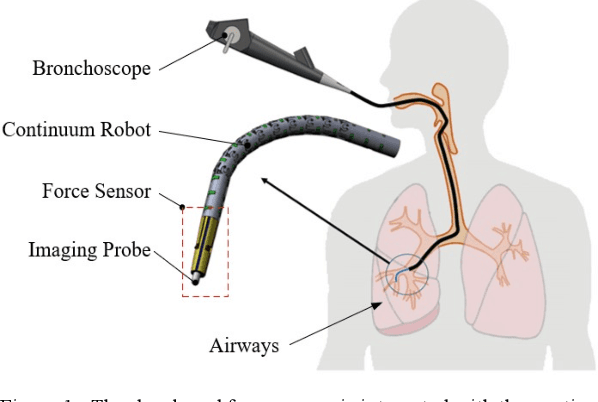
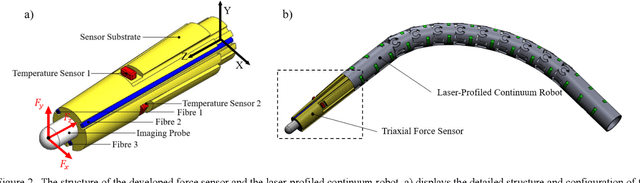
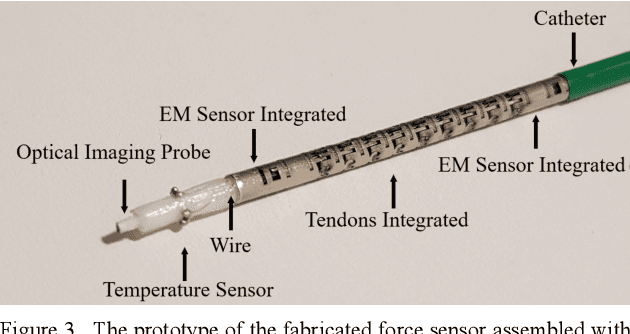

Accurate force sensing is important for endoluminal intervention in terms of both safety and lesion targeting. This paper develops an FBG-based force sensor for robotic bronchoscopy by configuring three FBG sensors at the lateral side of a conical substrate. It allows a large and eccentric inner lumen for the interventional instrument, enabling a flexible imaging probe inside to perform optical biopsy. The force sensor is embodied with a laser-profiled continuum robot and thermo drift is fully compensated by three temperature sensors integrated on the circumference surface of the sensor substrate. Different decoupling approaches are investigated, and nonlinear decoupling is adopted based on the cross-validation SVM and a Gaussian kernel function, achieving an accuracy of 10.58 mN, 14.57 mN and 26.32 mN along X, Y and Z axis, respectively. The tissue test is also investigated to further demonstrate the feasibility of the developed triaxial force sensor
Hybrid Data-Driven and Analytical Model for Kinematic Control of a Surgical Robotic Tool
Jun 09, 2020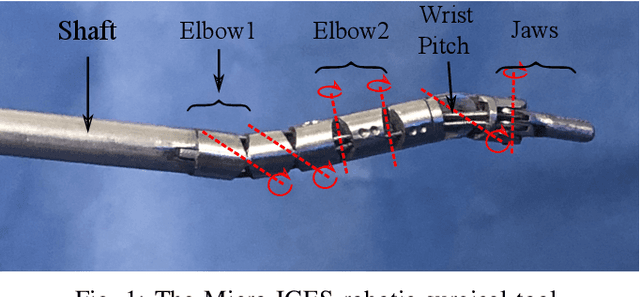
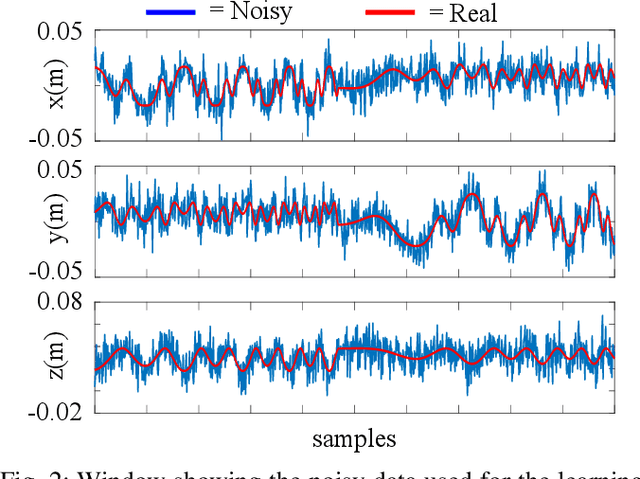
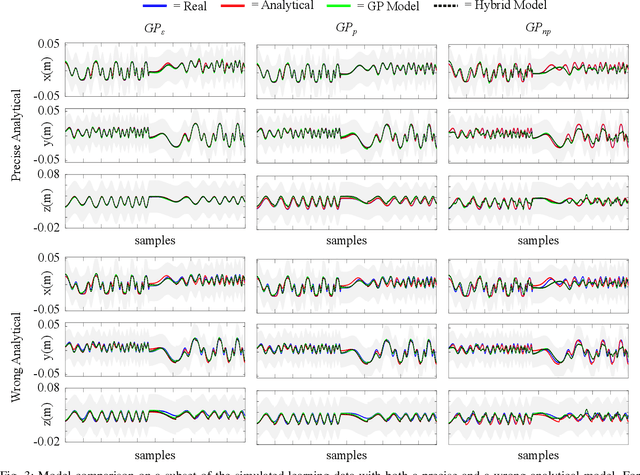

Accurate kinematic models are essential for effective control of surgical robots. For tendon driven robots, which is common for minimally invasive surgery, intrinsic nonlinearities are important to consider. Traditional analytical methods allow to build the kinematic model of the system by making certain assumptions and simplifications on the nonlinearities. Machine learning techniques, instead, allow to recover a more complex model based on the acquired data. However, analytical models are more generalisable, but can be over-simplified; data-driven models, on the other hand, can cater for more complex models, but are less generalisable and the result is highly affected by the training dataset. In this paper, we present a novel approach to combining analytical and data-driven approaches to model the kinematics of nonlinear tendon-driven surgical robots. Gaussian Process Regression (GPR) is used for learning the data-driven model and the proposed method is tested on both simulated data and real experimental data.
Constrained-Space Optimization and Reinforcement Learning for Complex Tasks
Apr 01, 2020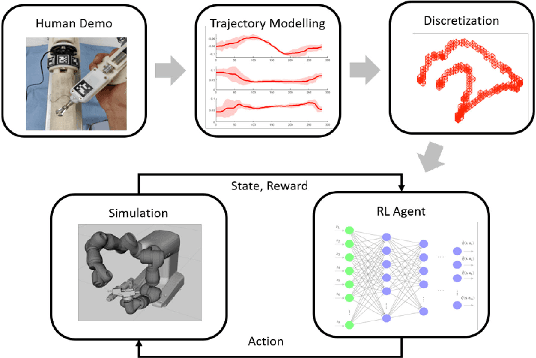

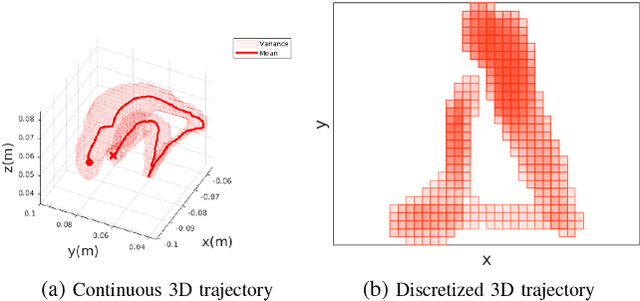
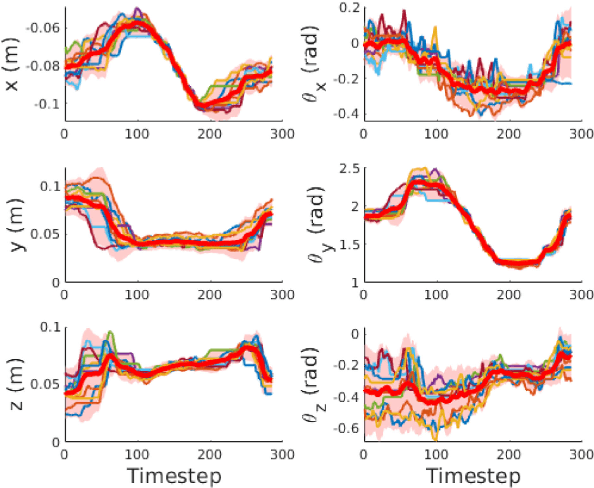
Learning from Demonstration is increasingly used for transferring operator manipulation skills to robots. In practice, it is important to cater for limited data and imperfect human demonstrations, as well as underlying safety constraints. This paper presents a constrained-space optimization and reinforcement learning scheme for managing complex tasks. Through interactions within the constrained space, the reinforcement learning agent is trained to optimize the manipulation skills according to a defined reward function. After learning, the optimal policy is derived from the well-trained reinforcement learning agent, which is then implemented to guide the robot to conduct tasks that are similar to the experts' demonstrations. The effectiveness of the proposed method is verified with a robotic suturing task, demonstrating that the learned policy outperformed the experts' demonstrations in terms of the smoothness of the joint motion and end-effector trajectories, as well as the overall task completion time.
* Accepted for publication in RA-Letters and at ICRA 2020
DDU-Nets: Distributed Dense Model for 3D MRI Brain Tumor Segmentation
Mar 03, 2020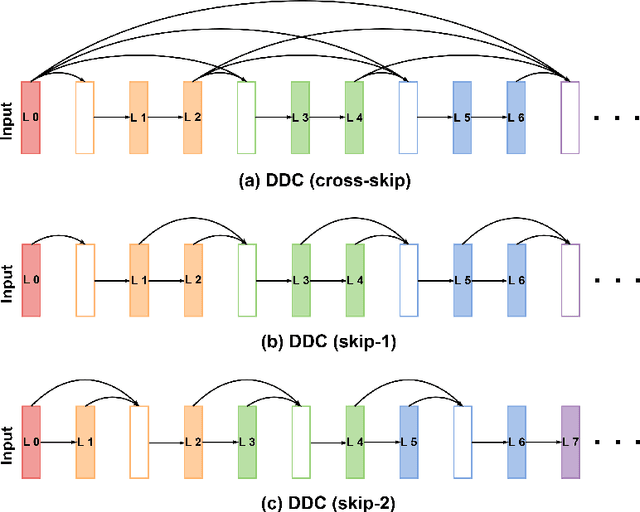
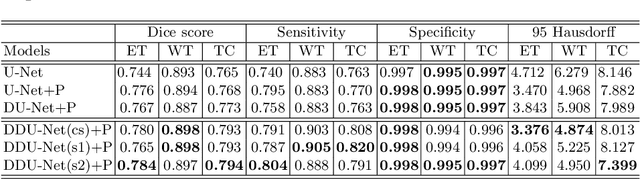
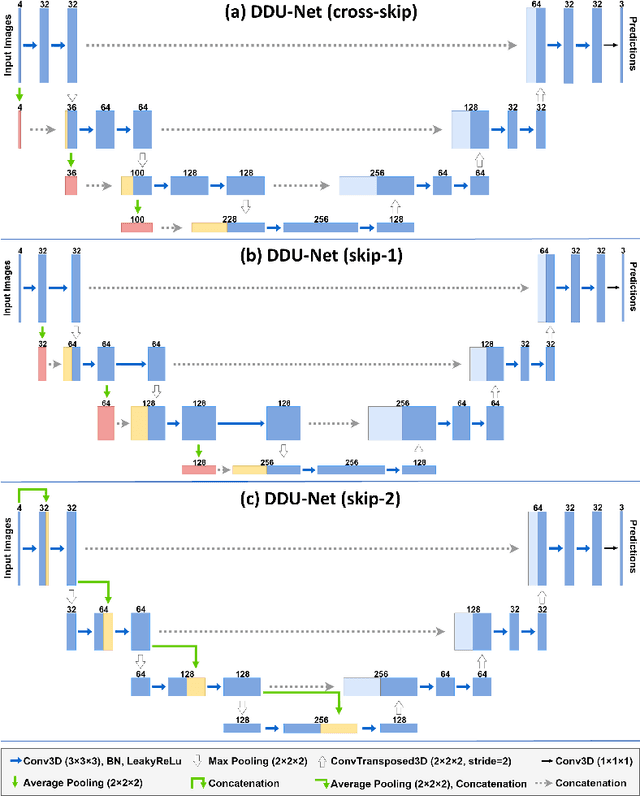

Segmentation of brain tumors and their subregions remains a challenging task due to their weak features and deformable shapes. In this paper, three patterns (cross-skip, skip-1 and skip-2) of distributed dense connections (DDCs) are proposed to enhance feature reuse and propagation of CNNs by constructing tunnels between key layers of the network. For better detecting and segmenting brain tumors from multi-modal 3D MR images, CNN-based models embedded with DDCs (DDU-Nets) are trained efficiently from pixel to pixel with a limited number of parameters. Postprocessing is then applied to refine the segmentation results by reducing the false-positive samples. The proposed method is evaluated on the BraTS 2019 dataset with results demonstrating the effectiveness of the DDU-Nets while requiring less computational cost.
Deep Learning in Medical Ultrasound Image Segmentation: a Review
Feb 25, 2020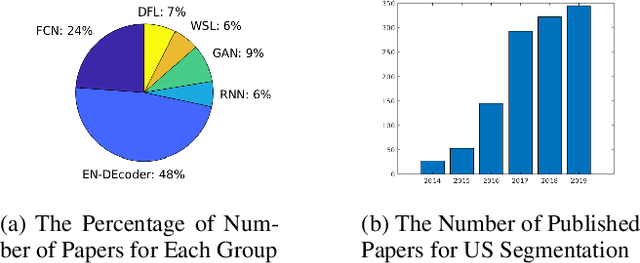
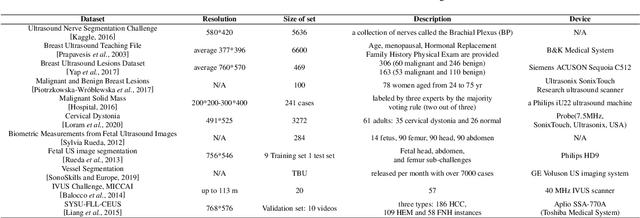
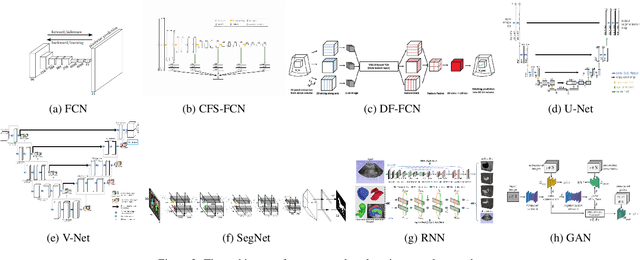
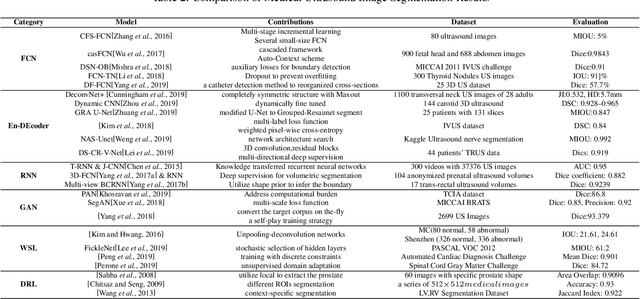
Applying machine learning technologies, especially deep learning, into medical image segmentation is being widely studied because of its state-of-the-art performance and results. It can be a key step to provide a reliable basis for clinical diagnosis, such as 3D reconstruction of human tissues, image-guided interventions, image analyzing and visualization. In this review article, deep-learning-based methods for ultrasound image segmentation are categorized into six main groups according to their architectures and training at first. Secondly, for each group, several current representative algorithms are selected, introduced, analyzed and summarized in detail. In addition, common evaluation methods for image segmentation and ultrasound image segmentation datasets are summarized. Further, the performance of the current methods and their evaluations are reviewed. In the end, the challenges and potential research directions for medical ultrasound image segmentation are discussed.
Nonlinearity Compensation in a Multi-DoF Shoulder Sensing Exosuit for Real-Time Teleoperation
Feb 21, 2020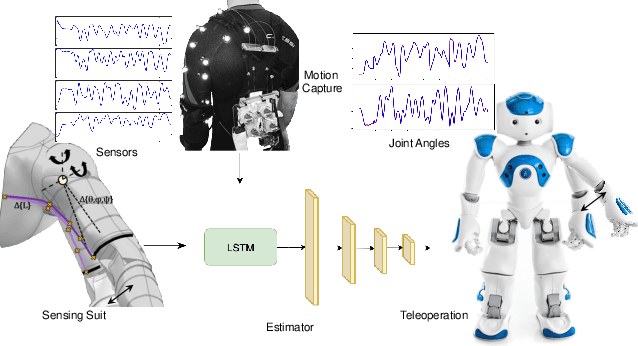
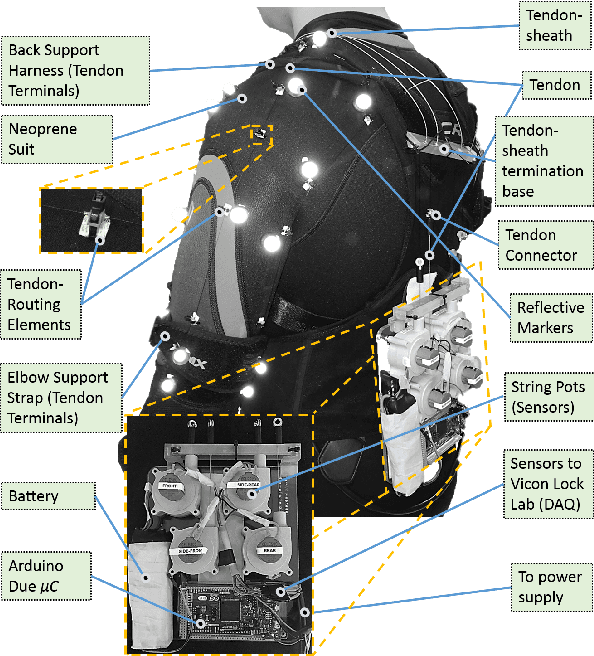

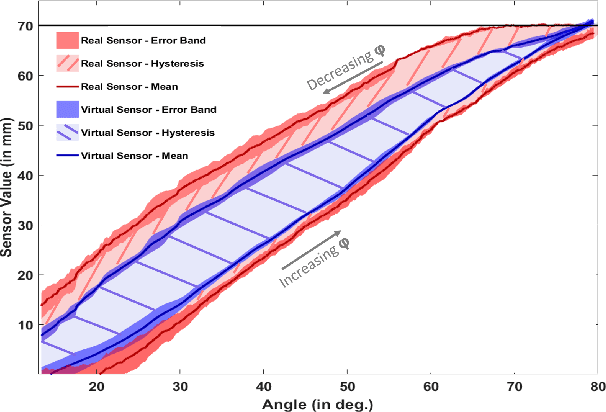
The compliant nature of soft wearable robots makes them ideal for complex multiple degrees of freedom (DoF) joints, but also introduce additional structural nonlinearities. Intuitive control of these wearable robots requires robust sensing to overcome the inherent nonlinearities. This paper presents a joint kinematics estimator for a bio-inspired multi-DoF shoulder exosuit capable of compensating the encountered nonlinearities. To overcome the nonlinearities and hysteresis inherent to the soft and compliant nature of the suit, we developed a deep learning-based method to map the sensor data to the joint space. The experimental results show that the new learning-based framework outperforms recent state-of-the-art methods by a large margin while achieving 12ms inference time using only a GPU-based edge-computing device. The effectiveness of our combined exosuit and learning framework is demonstrated through real-time teleoperation with a simulated NAO humanoid robot.
Artificial Intelligence in Surgery
Dec 23, 2019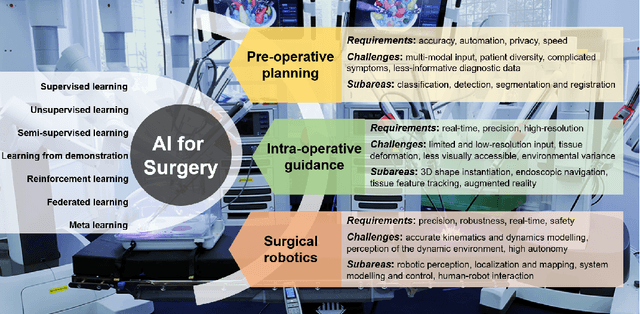
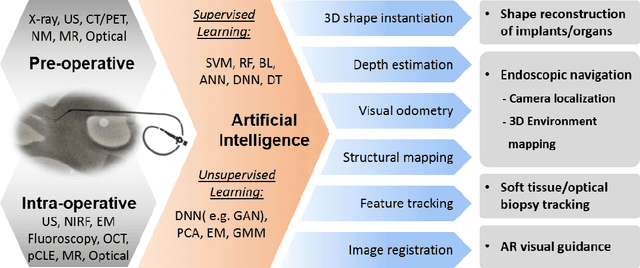
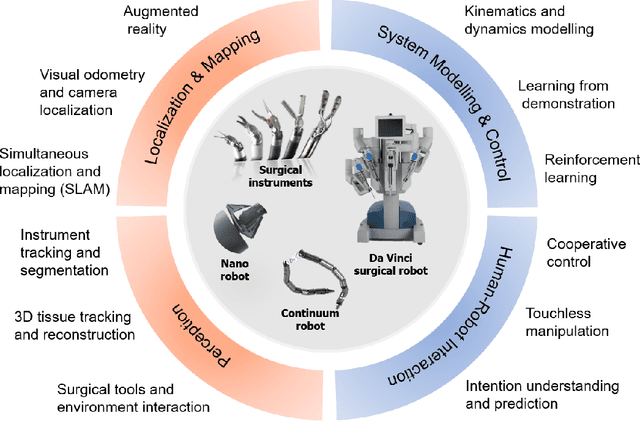
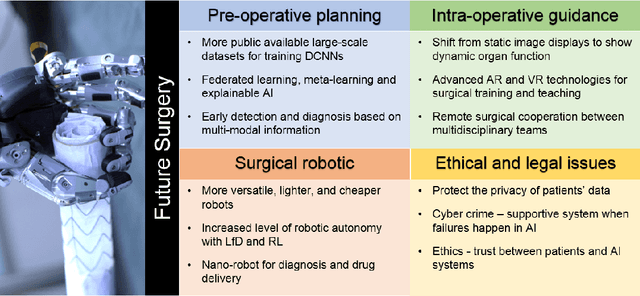
Artificial Intelligence (AI) is gradually changing the practice of surgery with the advanced technological development of imaging, navigation and robotic intervention. In this article, the recent successful and influential applications of AI in surgery are reviewed from pre-operative planning and intra-operative guidance to the integration of surgical robots. We end with summarizing the current state, emerging trends and major challenges in the future development of AI in surgery.