 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Demographic Factors Improve Text Classification? Revisiting Demographic Adaptation in the Age of Transformers
Oct 13, 2022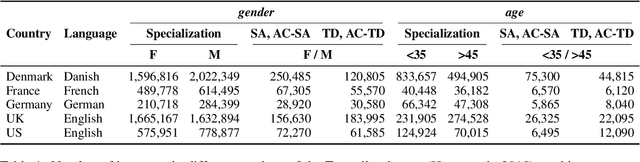

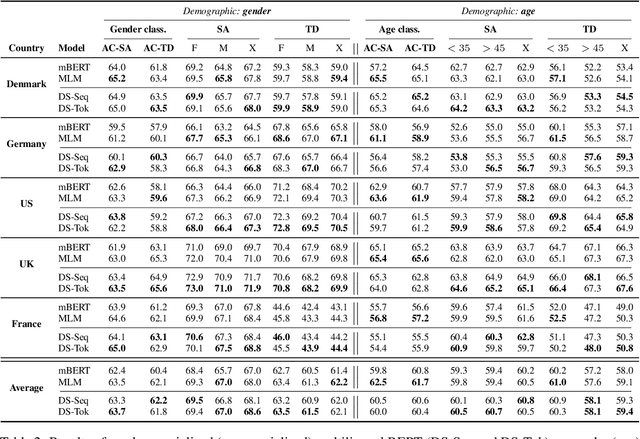
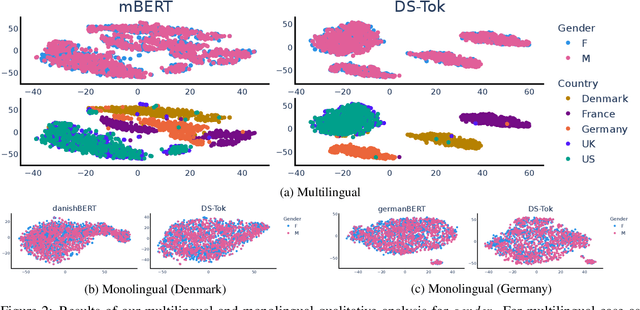
Demographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating demographic factors can consistently improve performance for various NLP tasks with traditional NLP models. In this work, we investigate whether these previous findings still hold with state-of-the-art pretrained Transformer-based language models (PLMs). We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the demographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling objectives with the prediction of demographic classes. Our results when employing a multilingual PLM show substantial performance gains across four languages (English, German, French, and Danish), which is consistent with the results of previous work. However, controlling for confounding factors -- primarily domain and language proficiency of Transformer-based PLMs -- shows that downstream performance gains from our demographic adaptation do not actually stem from demographic knowledge. Our results indicate that demographic specialization of PLMs, while holding promise for positive societal impact, still represents an unsolved problem for (modern) NLP.
On the Limitations of Sociodemographic Adaptation with Transformers
Aug 01, 2022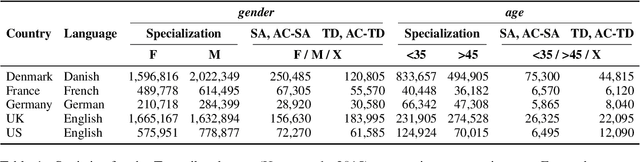
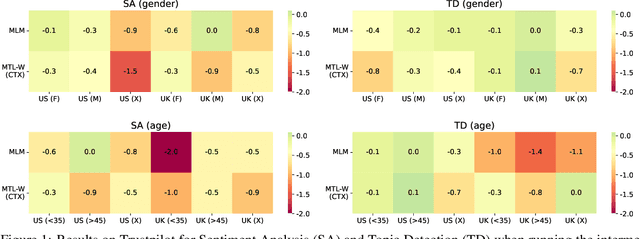
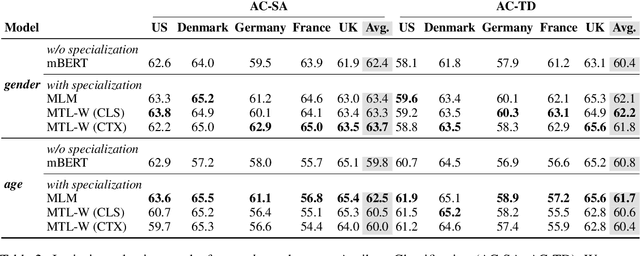
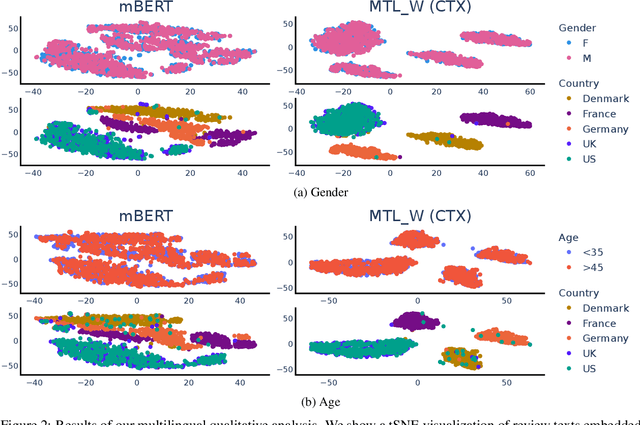
Sociodemographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating specific sociodemographic factors can consistently improve performance for various NLP tasks in traditional NLP models. We investigate whether these previous findings still hold with state-of-the-art pretrained Transformers. We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the sociodemographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling with the prediction of a sociodemographic class. Our results when employing a multilingual model show substantial performance gains across four languages (English, German, French, and Danish). These findings are in line with the results of previous work and hold promise for successful sociodemographic specialization. However, controlling for confounding factors like domain and language shows that, while sociodemographic adaptation does improve downstream performance, the gains do not always solely stem from sociodemographic knowledge. Our results indicate that sociodemographic specialization, while very important, is still an unresolved problem in NLP.
BabelBERT: Massively Multilingual Transformers Meet a Massively Multilingual Lexical Resource
Aug 01, 2022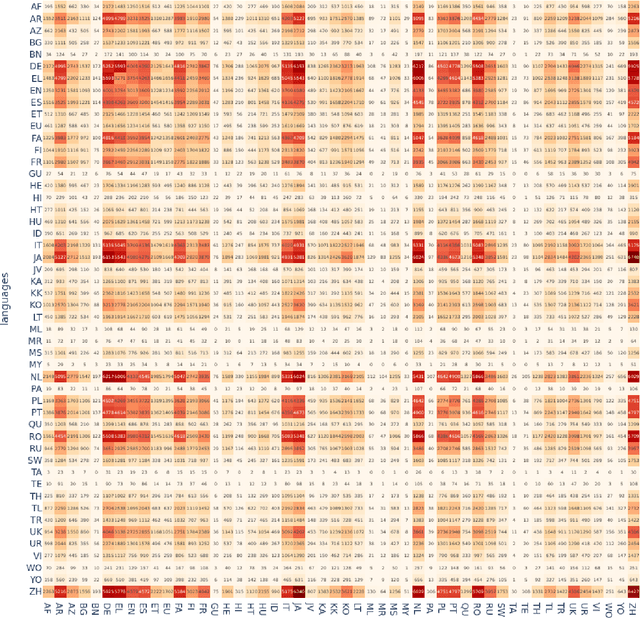
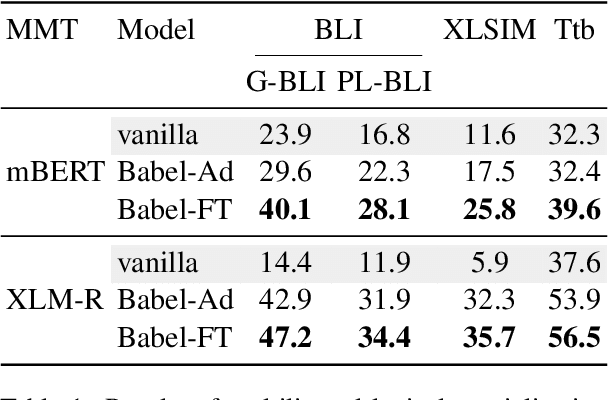
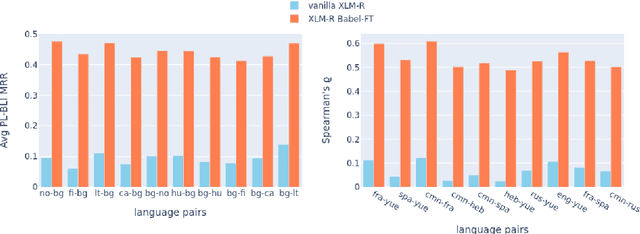
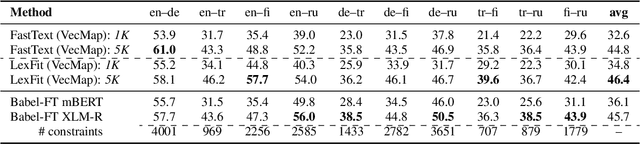
While pretrained language models (PLMs) primarily serve as general purpose text encoders that can be fine-tuned for a wide variety of downstream tasks, recent work has shown that they can also be rewired to produce high-quality word representations (i.e., static word embeddings) and yield good performance in type-level lexical tasks. While existing work primarily focused on lexical specialization of PLMs in monolingual and bilingual settings, in this work we expose massively multilingual transformers (MMTs, e.g., mBERT or XLM-R) to multilingual lexical knowledge at scale, leveraging BabelNet as the readily available rich source of multilingual and cross-lingual type-level lexical knowledge. Concretely, we leverage BabelNet's multilingual synsets to create synonym pairs across $50$ languages and then subject the MMTs (mBERT and XLM-R) to a lexical specialization procedure guided by a contrastive objective. We show that such massively multilingual lexical specialization brings massive gains in two standard cross-lingual lexical tasks, bilingual lexicon induction and cross-lingual word similarity, as well as in cross-lingual sentence retrieval. Crucially, we observe gains for languages unseen in specialization, indicating that the multilingual lexical specialization enables generalization to languages with no lexical constraints. In a series of subsequent controlled experiments, we demonstrate that the pretraining quality of word representations in the MMT for languages involved in specialization has a much larger effect on performance than the linguistic diversity of the set of constraints. Encouragingly, this suggests that lexical tasks involving low-resource languages benefit the most from lexical knowledge of resource-rich languages, generally much more available.
ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering System
May 30, 2022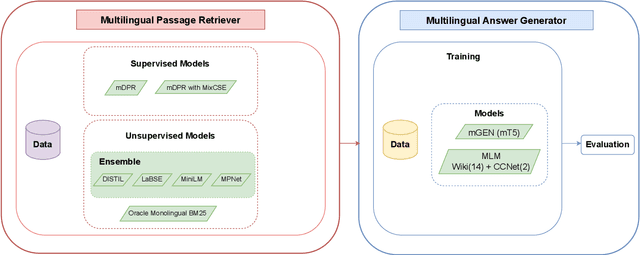



This paper introduces our proposed system for the MIA Shared Task on Cross-lingual Open-retrieval Question Answering (COQA). In this challenging scenario, given an input question the system has to gather evidence documents from a multilingual pool and generate from them an answer in the language of the question. We devised several approaches combining different model variants for three main components: Data Augmentation, Passage Retrieval, and Answer Generation. For passage retrieval, we evaluated the monolingual BM25 ranker against the ensemble of re-rankers based on multilingual pretrained language models (PLMs) and also variants of the shared task baseline, re-training it from scratch using a recently introduced contrastive loss that maintains a strong gradient signal throughout training by means of mixed negative samples. For answer generation, we focused on language- and domain-specialization by means of continued language model (LM) pretraining of existing multilingual encoders. Additionally, for both passage retrieval and answer generation, we augmented the training data provided by the task organizers with automatically generated question-answer pairs created from Wikipedia passages to mitigate the issue of data scarcity, particularly for the low-resource languages for which no training data were provided. Our results show that language- and domain-specialization as well as data augmentation help, especially for low-resource languages.
Multi2WOZ: A Robust Multilingual Dataset and Conversational Pretraining for Task-Oriented Dialog
May 20, 2022
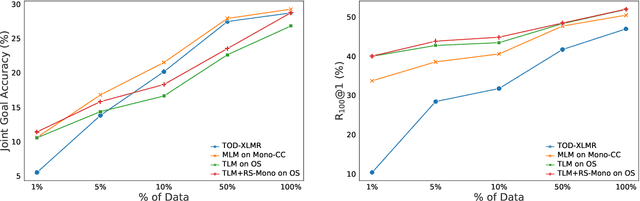

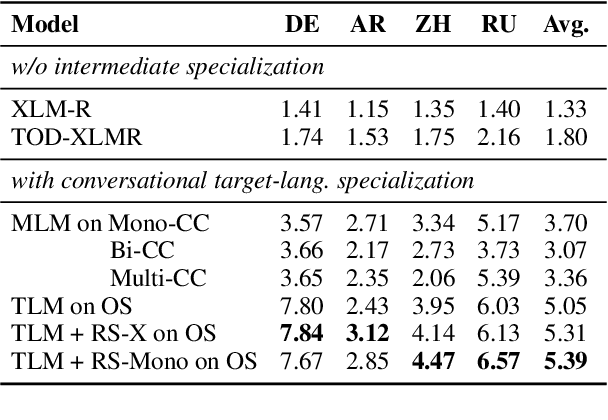
Research on (multi-domain) task-oriented dialog (TOD) has predominantly focused on the English language, primarily due to the shortage of robust TOD datasets in other languages, preventing the systematic investigation of cross-lingual transfer for this crucial NLP application area. In this work, we introduce Multi2WOZ, a new multilingual multi-domain TOD dataset, derived from the well-established English dataset MultiWOZ, that spans four typologically diverse languages: Chinese, German, Arabic, and Russian. In contrast to concurrent efforts, Multi2WOZ contains gold-standard dialogs in target languages that are directly comparable with development and test portions of the English dataset, enabling reliable and comparative estimates of cross-lingual transfer performance for TOD. We then introduce a new framework for multilingual conversational specialization of pretrained language models (PrLMs) that aims to facilitate cross-lingual transfer for arbitrary downstream TOD tasks. Using such conversational PrLMs specialized for concrete target languages, we systematically benchmark a number of zero-shot and few-shot cross-lingual transfer approaches on two standard TOD tasks: Dialog State Tracking and Response Retrieval. Our experiments show that, in most setups, the best performance entails the combination of (I) conversational specialization in the target language and (ii) few-shot transfer for the concrete TOD task. Most importantly, we show that our conversational specialization in the target language allows for an exceptionally sample-efficient few-shot transfer for downstream TOD tasks.
Exposing Cross-Lingual Lexical Knowledge from Multilingual Sentence Encoders
Apr 30, 2022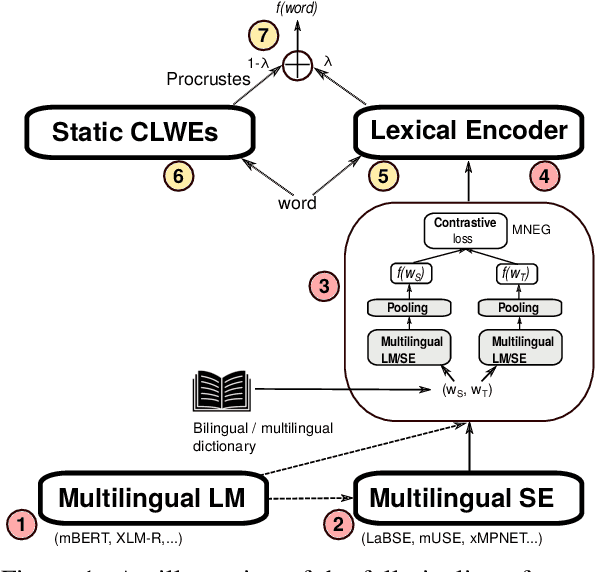
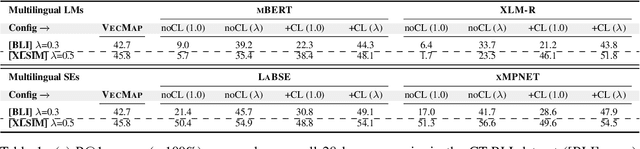
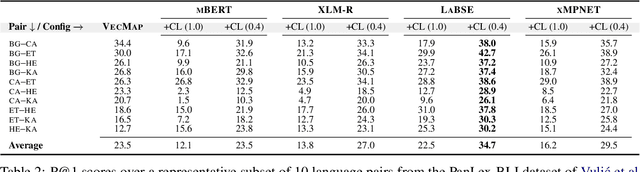

Pretrained multilingual language models (LMs) can be successfully transformed into multilingual sentence encoders (SEs; e.g., LaBSE, xMPNET) via additional fine-tuning or model distillation on parallel data. However, it remains uncertain how to best leverage their knowledge to represent sub-sentence lexical items (i.e., words and phrases) in cross-lingual lexical tasks. In this work, we probe these SEs for the amount of cross-lingual lexical knowledge stored in their parameters, and compare them against the original multilingual LMs. We also devise a novel method to expose this knowledge by additionally fine-tuning multilingual models through inexpensive contrastive learning procedure, requiring only a small amount of word translation pairs. We evaluate our method on bilingual lexical induction (BLI), cross-lingual lexical semantic similarity, and cross-lingual entity linking, and report substantial gains on standard benchmarks (e.g., +10 Precision@1 points in BLI), validating that the SEs such as LaBSE can be 'rewired' into effective cross-lingual lexical encoders. Moreover, we show that resulting representations can be successfully interpolated with static embeddings from cross-lingual word embedding spaces to further boost the performance in lexical tasks. In sum, our approach provides an effective tool for exposing and harnessing multilingual lexical knowledge 'hidden' in multilingual sentence encoders.
Parameter-Efficient Neural Reranking for Cross-Lingual and Multilingual Retrieval
Apr 05, 2022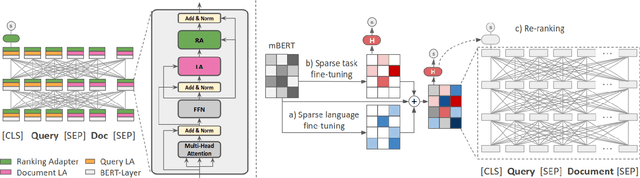
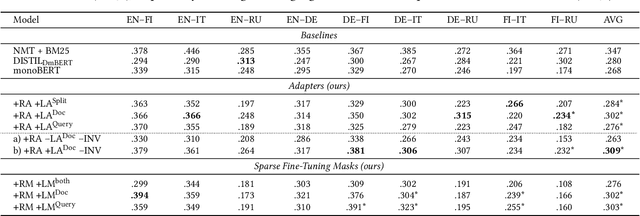

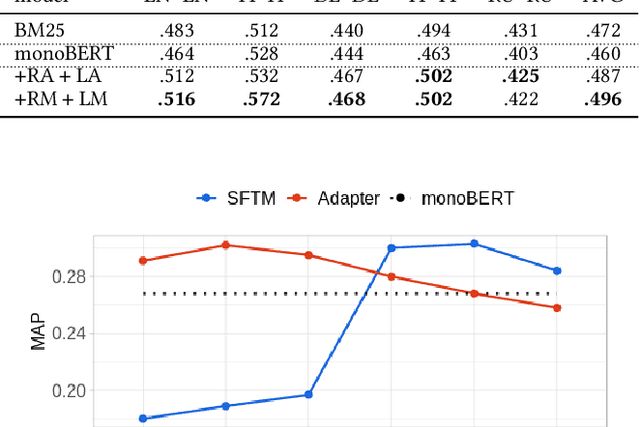
State-of-the-art neural (re)rankers are notoriously data hungry which - given the lack of large-scale training data in languages other than English - makes them rarely used in multilingual and cross-lingual retrieval settings. Current approaches therefore typically transfer rankers trained on English data to other languages and cross-lingual setups by means of multilingual encoders: they fine-tune all the parameters of a pretrained massively multilingual Transformer (MMT, e.g., multilingual BERT) on English relevance judgments and then deploy it in the target language. In this work, we show that two parameter-efficient approaches to cross-lingual transfer, namely Sparse Fine-Tuning Masks (SFTMs) and Adapters, allow for a more lightweight and more effective zero-shot transfer to multilingual and cross-lingual retrieval tasks. We first train language adapters (or SFTMs) via Masked Language Modelling and then train retrieval (i.e., reranking) adapters (SFTMs) on top while keeping all other parameters fixed. At inference, this modular design allows us to compose the ranker by applying the task adapter (or SFTM) trained with source language data together with the language adapter (or SFTM) of a target language. Besides improved transfer performance, these two approaches offer faster ranker training, with only a fraction of parameters being updated compared to full MMT fine-tuning. We benchmark our models on the CLEF-2003 benchmark, showing that our parameter-efficient methods outperform standard zero-shot transfer with full MMT fine-tuning, while enabling modularity and reducing training times. Further, we show on the example of Swahili and Somali that, for low(er)-resource languages, our parameter-efficient neural re-rankers can improve the ranking of the competitive machine translation-based ranker.
Geographic Adaptation of Pretrained Language Models
Mar 16, 2022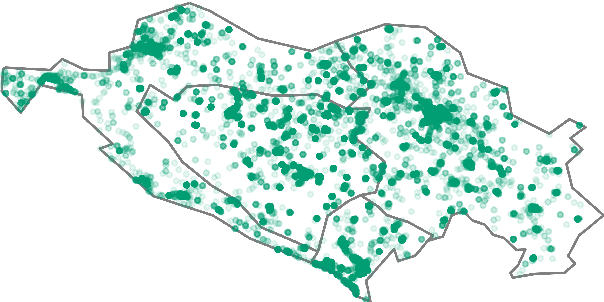


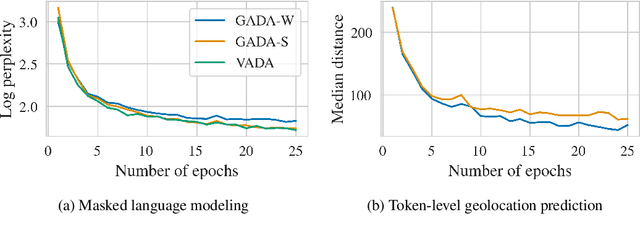
Geographic linguistic features are commonly used to improve the performance of pretrained language models (PLMs) on NLP tasks where geographic knowledge is intuitively beneficial (e.g., geolocation prediction and dialect feature prediction). Existing work, however, leverages such geographic information in task-specific fine-tuning, failing to incorporate it into PLMs' geo-linguistic knowledge, which would make it transferable across different tasks. In this work, we introduce an approach to task-agnostic geoadaptation of PLMs that forces the PLM to learn associations between linguistic phenomena and geographic locations. More specifically, geoadaptation is an intermediate training step that couples masked language modeling and geolocation prediction in a dynamic multitask learning setup. In our experiments, we geoadapt BERTi\'c -- a PLM for Bosnian, Croatian, Montenegrin, and Serbian (BCMS) -- using a corpus of geotagged BCMS tweets. Evaluation on three different tasks, namely unsupervised (zero-shot) and supervised geolocation prediction and (unsupervised) prediction of dialect features, shows that our geoadaptation approach is very effective: e.g., we obtain new state-of-the-art performance in supervised geolocation prediction and report massive gains over geographically uninformed PLMs on zero-shot geolocation prediction.
On Cross-Lingual Retrieval with Multilingual Text Encoders
Dec 21, 2021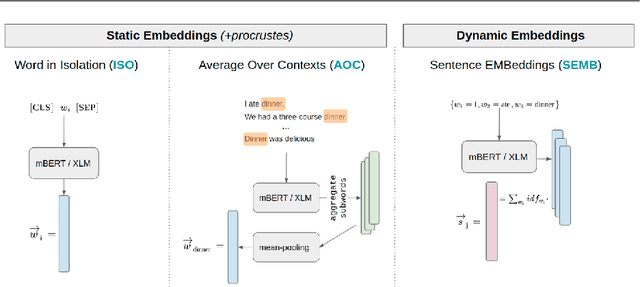
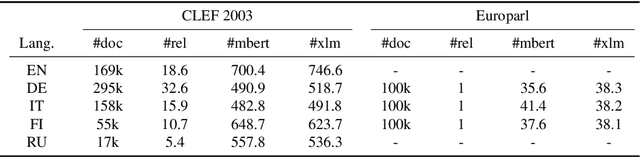
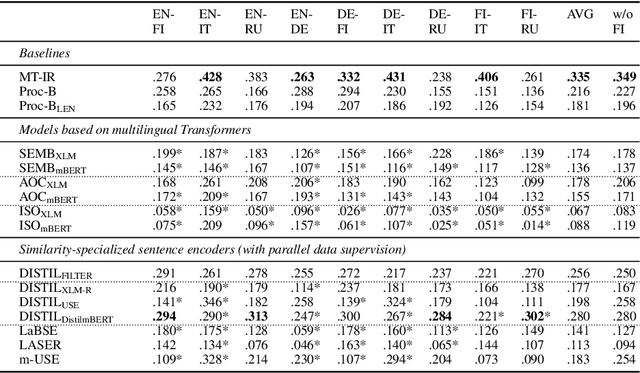
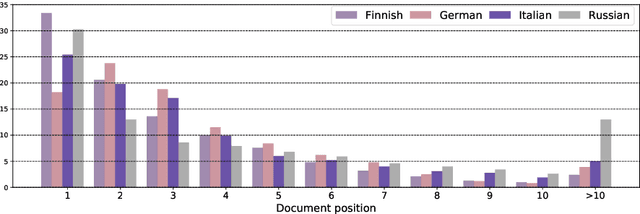
In this work we present a systematic empirical study focused on the suitability of the state-of-the-art multilingual encoders for cross-lingual document and sentence retrieval tasks across a number of diverse language pairs. We first treat these models as multilingual text encoders and benchmark their performance in unsupervised ad-hoc sentence- and document-level CLIR. In contrast to supervised language understanding, our results indicate that for unsupervised document-level CLIR -- a setup with no relevance judgments for IR-specific fine-tuning -- pretrained multilingual encoders on average fail to significantly outperform earlier models based on CLWEs. For sentence-level retrieval, we do obtain state-of-the-art performance: the peak scores, however, are met by multilingual encoders that have been further specialized, in a supervised fashion, for sentence understanding tasks, rather than using their vanilla 'off-the-shelf' variants. Following these results, we introduce localized relevance matching for document-level CLIR, where we independently score a query against document sections. In the second part, we evaluate multilingual encoders fine-tuned in a supervised fashion (i.e., we learn to rank) on English relevance data in a series of zero-shot language and domain transfer CLIR experiments. Our results show that supervised re-ranking rarely improves the performance of multilingual transformers as unsupervised base rankers. Finally, only with in-domain contrastive fine-tuning (i.e., same domain, only language transfer), we manage to improve the ranking quality. We uncover substantial empirical differences between cross-lingual retrieval results and results of (zero-shot) cross-lingual transfer for monolingual retrieval in target languages, which point to "monolingual overfitting" of retrieval models trained on monolingual data.
DS-TOD: Efficient Domain Specialization for Task Oriented Dialog
Oct 15, 2021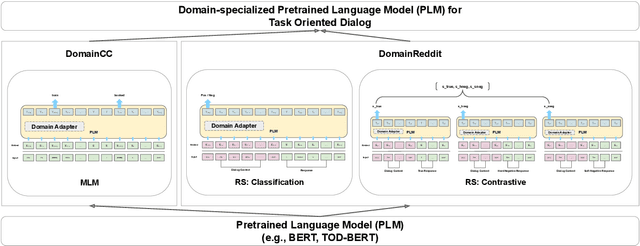
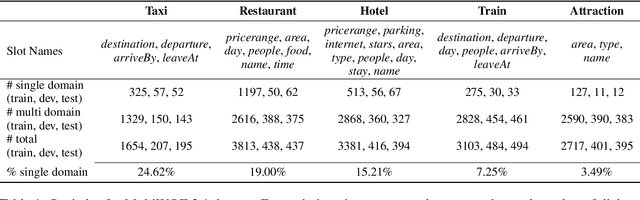
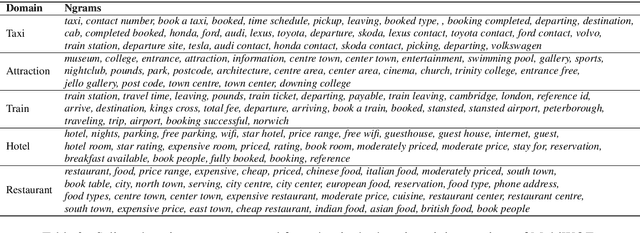
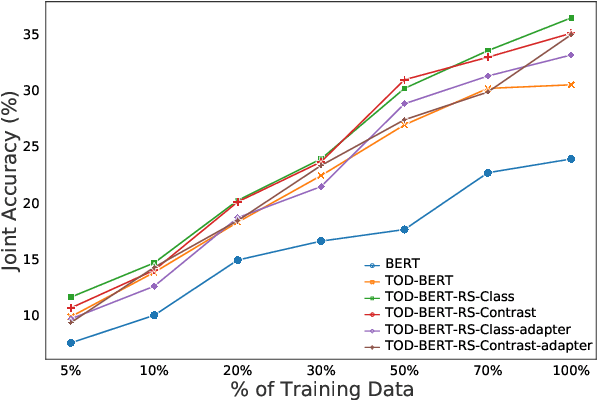
Recent work has shown that self-supervised dialog-specific pretraining on large conversational datasets yields substantial gains over traditional language modeling (LM) pretraining in downstream task-oriented dialog (TOD). These approaches, however, exploit general dialogic corpora (e.g., Reddit) and thus presumably fail to reliably embed domain-specific knowledge useful for concrete downstream TOD domains. In this work, we investigate the effects of domain specialization of pretrained language models (PLMs) for task-oriented dialog. Within our DS-TOD framework, we first automatically extract salient domain-specific terms, and then use them to construct DomainCC and DomainReddit -- resources that we leverage for domain-specific pretraining, based on (i) masked language modeling (MLM) and (ii) response selection (RS) objectives, respectively. We further propose a resource-efficient and modular domain specialization by means of domain adapters -- additional parameter-light layers in which we encode the domain knowledge. Our experiments with two prominent TOD tasks -- dialog state tracking (DST) and response retrieval (RR) -- encompassing five domains from the MultiWOZ TOD benchmark demonstrate the effectiveness of our domain specialization approach. Moreover, we show that the light-weight adapter-based specialization (1) performs comparably to full fine-tuning in single-domain setups and (2) is particularly suitable for multi-domain specialization, in which, besides advantageous computational footprint, it can offer better downstream performance.