 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
GerAV: Towards New Heights in German Authorship Verification using Fine-Tuned LLMs on a New Benchmark
Jan 20, 2026Authorship verification (AV) is the task of determining whether two texts were written by the same author and has been studied extensively, predominantly for English data. In contrast, large-scale benchmarks and systematic evaluations for other languages remain scarce. We address this gap by introducing GerAV, a comprehensive benchmark for German AV comprising over 600k labeled text pairs. GerAV is built from Twitter and Reddit data, with the Reddit part further divided into in-domain and cross-domain message-based subsets, as well as a profile-based subset. This design enables controlled analysis of the effects of data source, topical domain, and text length. Using the provided training splits, we conduct a systematic evaluation of strong baselines and state-of-the-art models and find that our best approach, a fine-tuned large language model, outperforms recent baselines by up to 0.09 absolute F1 score and surpasses GPT-5 in a zero-shot setting by 0.08. We further observe a trade-off between specialization and generalization: models trained on specific data types perform best under matching conditions but generalize less well across data regimes, a limitation that can be mitigated by combining training sources. Overall, GerAV provides a challenging and versatile benchmark for advancing research on German and cross-domain AV.
SciLaD: A Large-Scale, Transparent, Reproducible Dataset for Natural Scientific Language Processing
Dec 12, 2025SciLaD is a novel, large-scale dataset of scientific language constructed entirely using open-source frameworks and publicly available data sources. It comprises a curated English split containing over 10 million scientific publications and a multilingual, unfiltered TEI XML split including more than 35 million publications. We also publish the extensible pipeline for generating SciLaD. The dataset construction and processing workflow demonstrates how open-source tools can enable large-scale, scientific data curation while maintaining high data quality. Finally, we pre-train a RoBERTa model on our dataset and evaluate it across a comprehensive set of benchmarks, achieving performance comparable to other scientific language models of similar size, validating the quality and utility of SciLaD. We publish the dataset and evaluation pipeline to promote reproducibility, transparency, and further research in natural scientific language processing and understanding including scholarly document processing.
Randomly Removing 50% of Dimensions in Text Embeddings has Minimal Impact on Retrieval and Classification Tasks
Aug 25, 2025In this paper, we study the surprising impact that truncating text embeddings has on downstream performance. We consistently observe across 6 state-of-the-art text encoders and 26 downstream tasks, that randomly removing up to 50% of embedding dimensions results in only a minor drop in performance, less than 10%, in retrieval and classification tasks. Given the benefits of using smaller-sized embeddings, as well as the potential insights about text encoding, we study this phenomenon and find that, contrary to what is suggested in prior work, this is not the result of an ineffective use of representation space. Instead, we find that a large number of uniformly distributed dimensions actually cause an increase in performance when removed. This would explain why, on average, removing a large number of embedding dimensions results in a marginal drop in performance. We make similar observations when truncating the embeddings used by large language models to make next-token predictions on generative tasks, suggesting that this phenomenon is not isolated to classification or retrieval tasks.
DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Apr 10, 2025Reasoning-enabled large language models (LLMs) have recently demonstrated impressive performance in complex logical and mathematical tasks, yet their effectiveness in evaluating natural language generation remains unexplored. This study systematically compares reasoning-based LLMs (DeepSeek-R1 and OpenAI o3) with their non-reasoning counterparts across machine translation (MT) and text summarization (TS) evaluation tasks. We evaluate eight models across three architectural categories, including state-of-the-art reasoning models, their distilled variants (ranging from 8B to 70B parameters), and equivalent conventional, non-reasoning LLMs. Our experiments on WMT23 and SummEval benchmarks reveal that the benefits of reasoning capabilities are highly model and task-dependent: while OpenAI o3-mini models show consistent performance improvements with increased reasoning intensity, DeepSeek-R1 underperforms compared to its non-reasoning variant, with exception to certain aspects of TS evaluation. Correlation analysis demonstrates that increased reasoning token usage positively correlates with evaluation quality in o3-mini models. Furthermore, our results show that distillation of reasoning capabilities maintains reasonable performance in medium-sized models (32B) but degrades substantially in smaller variants (8B). This work provides the first comprehensive assessment of reasoning LLMs for NLG evaluation and offers insights into their practical use.
ROUGE-K: Do Your Summaries Have Keywords?
Mar 08, 2024



Keywords, that is, content-relevant words in summaries play an important role in efficient information conveyance, making it critical to assess if system-generated summaries contain such informative words during evaluation. However, existing evaluation metrics for extreme summarization models do not pay explicit attention to keywords in summaries, leaving developers ignorant of their presence. To address this issue, we present a keyword-oriented evaluation metric, dubbed ROUGE-K, which provides a quantitative answer to the question of -- \textit{How well do summaries include keywords?} Through the lens of this keyword-aware metric, we surprisingly find that a current strong baseline model often misses essential information in their summaries. Our analysis reveals that human annotators indeed find the summaries with more keywords to be more relevant to the source documents. This is an important yet previously overlooked aspect in evaluating summarization systems. Finally, to enhance keyword inclusion, we propose four approaches for incorporating word importance into a transformer-based model and experimentally show that it enables guiding models to include more keywords while keeping the overall quality. Our code is released at https://github.com/sobamchan/rougek.
ACLSum: A New Dataset for Aspect-based Summarization of Scientific Publications
Mar 08, 2024



Extensive efforts in the past have been directed toward the development of summarization datasets. However, a predominant number of these resources have been (semi)-automatically generated, typically through web data crawling, resulting in subpar resources for training and evaluating summarization systems, a quality compromise that is arguably due to the substantial costs associated with generating ground-truth summaries, particularly for diverse languages and specialized domains. To address this issue, we present ACLSum, a novel summarization dataset carefully crafted and evaluated by domain experts. In contrast to previous datasets, ACLSum facilitates multi-aspect summarization of scientific papers, covering challenges, approaches, and outcomes in depth. Through extensive experiments, we evaluate the quality of our resource and the performance of models based on pretrained language models and state-of-the-art large language models (LLMs). Additionally, we explore the effectiveness of extractive versus abstractive summarization within the scholarly domain on the basis of automatically discovered aspects. Our results corroborate previous findings in the general domain and indicate the general superiority of end-to-end aspect-based summarization. Our data is released at https://github.com/sobamchan/aclsum.
VADIS -- a VAriable Detection, Interlinking and Summarization system
Dec 20, 2023The VADIS system addresses the demand of providing enhanced information access in the domain of the social sciences. This is achieved by allowing users to search and use survey variables in context of their underlying research data and scholarly publications which have been interlinked with each other.
Towards Automated Survey Variable Search and Summarization in Social Science Publications
Sep 14, 2022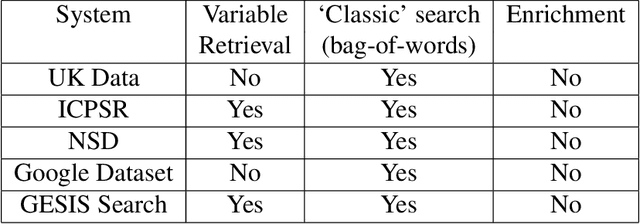
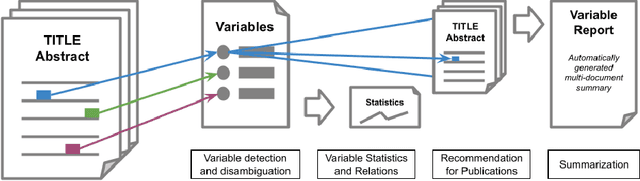
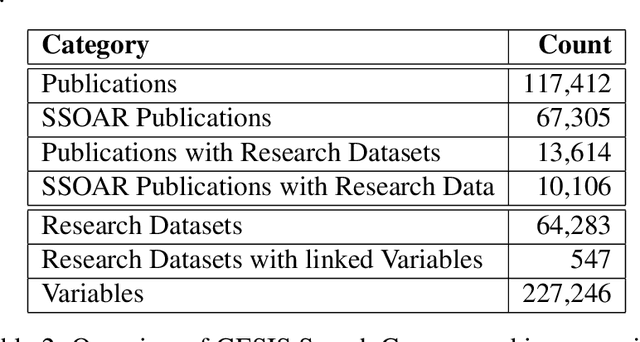
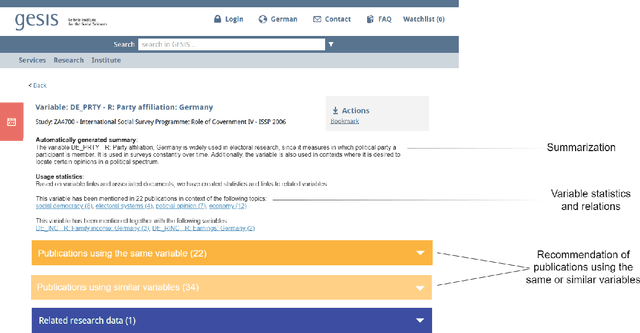
Nowadays there is a growing trend in many scientific disciplines to support researchers by providing enhanced information access through linking of publications and underlying datasets, so as to support research with infrastructure to enhance reproducibility and reusability of research results. In this research note, we present an overview of an ongoing research project, named VADIS (VAriable Detection, Interlinking and Summarization), that aims at developing technology and infrastructure for enhanced information access in the Social Sciences via search and summarization of publications on the basis of automatic identification and indexing of survey variables in text. We provide an overview of the overarching vision underlying our project, its main components, and related challenges, as well as a thorough discussion of how these are meant to address the limitations of current information access systems for publications in the Social Sciences. We show how this goal can be concretely implemented in an end-user system by presenting a search prototype, which is based on user requirements collected from qualitative interviews with empirical Social Science researchers.
X-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents
May 30, 2022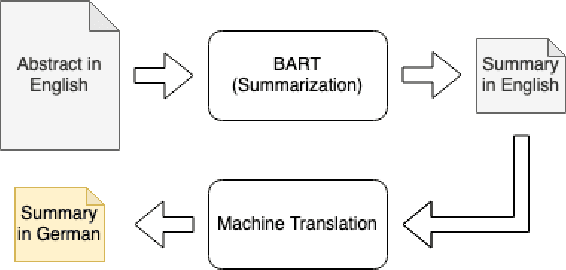

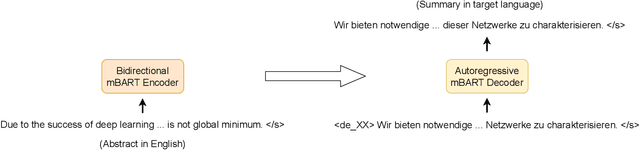

The number of scientific publications nowadays is rapidly increasing, causing information overload for researchers and making it hard for scholars to keep up to date with current trends and lines of work. Consequently, recent work on applying text mining technologies for scholarly publications has investigated the application of automatic text summarization technologies, including extreme summarization, for this domain. However, previous work has concentrated only on monolingual settings, primarily in English. In this paper, we fill this research gap and present an abstractive cross-lingual summarization dataset for four different languages in the scholarly domain, which enables us to train and evaluate models that process English papers and generate summaries in German, Italian, Chinese and Japanese. We present our new X-SCITLDR dataset for multilingual summarization and thoroughly benchmark different models based on a state-of-the-art multilingual pre-trained model, including a two-stage `summarize and translate' approach and a direct cross-lingual model. We additionally explore the benefits of intermediate-stage training using English monolingual summarization and machine translation as intermediate tasks and analyze performance in zero- and few-shot scenarios.