 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Social Science Research via Survey Item Linking
Dec 20, 2024Questions within surveys, called survey items, are used in the social sciences to study latent concepts, such as the factors influencing life satisfaction. Instead of using explicit citations, researchers paraphrase the content of the survey items they use in-text. However, this makes it challenging to find survey items of interest when comparing related work. Automatically parsing and linking these implicit mentions to survey items in a knowledge base can provide more fine-grained references. We model this task, called Survey Item Linking (SIL), in two stages: mention detection and entity disambiguation. Due to an imprecise definition of the task, existing datasets used for evaluating the performance for SIL are too small and of low-quality. We argue that latent concepts and survey item mentions should be differentiated. To this end, we create a high-quality and richly annotated dataset consisting of 20,454 English and German sentences. By benchmarking deep learning systems for each of the two stages independently and sequentially, we demonstrate that the task is feasible, but observe that errors propagate from the first stage, leading to a lower overall task performance. Moreover, mentions that require the context of multiple sentences are more challenging to identify for models in the first stage. Modeling the entire context of a document and combining the two stages into an end-to-end system could mitigate these problems in future work, and errors could additionally be reduced by collecting more diverse data and by improving the quality of the knowledge base. The data and code are available at https://github.com/e-tornike/SIL .
VADIS -- a VAriable Detection, Interlinking and Summarization system
Dec 20, 2023The VADIS system addresses the demand of providing enhanced information access in the domain of the social sciences. This is achieved by allowing users to search and use survey variables in context of their underlying research data and scholarly publications which have been interlinked with each other.
Overview of the SV-Ident 2022 Shared Task on Survey Variable Identification in Social Science Publications
Sep 19, 2022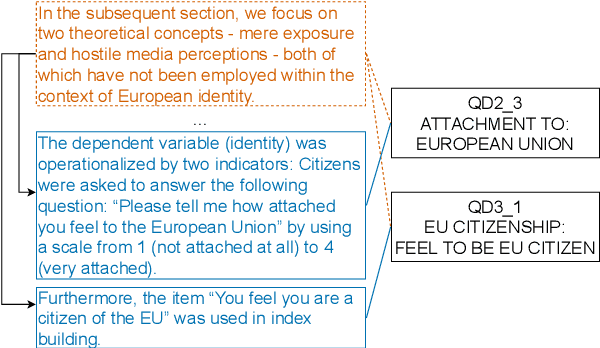
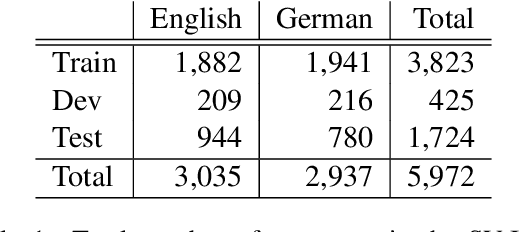

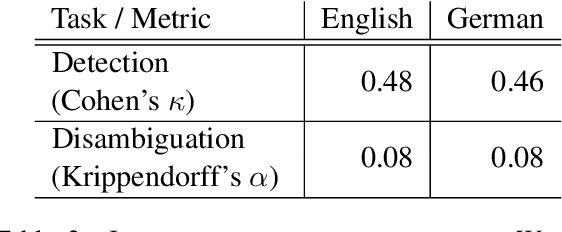
In this paper, we provide an overview of the SV-Ident shared task as part of the 3rd Workshop on Scholarly Document Processing (SDP) at COLING 2022. In the shared task, participants were provided with a sentence and a vocabulary of variables, and asked to identify which variables, if any, are mentioned in individual sentences from scholarly documents in full text. Two teams made a total of 9 submissions to the shared task leaderboard. While none of the teams improve on the baseline systems, we still draw insights from their submissions. Furthermore, we provide a detailed evaluation. Data and baselines for our shared task are freely available at https://github.com/vadis-project/sv-ident
Towards Automated Survey Variable Search and Summarization in Social Science Publications
Sep 14, 2022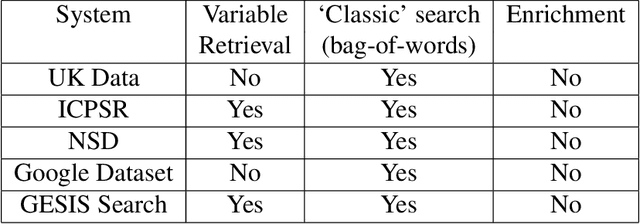
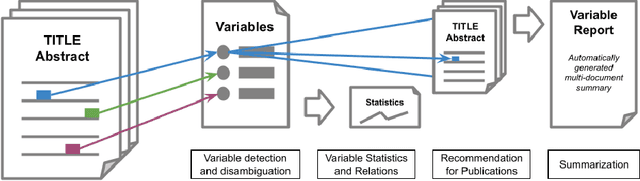
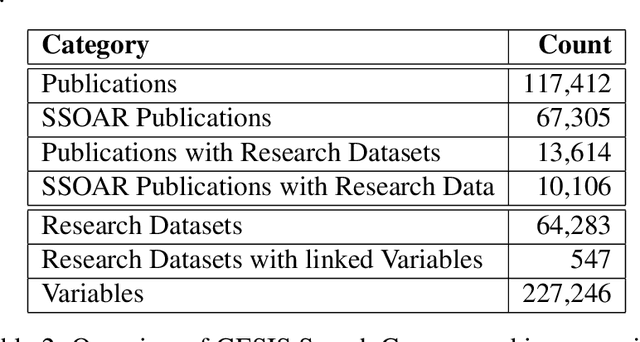
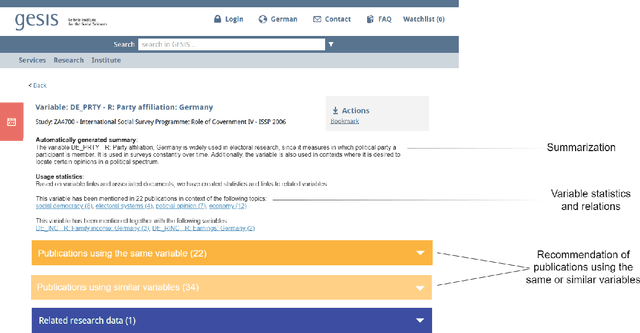
Nowadays there is a growing trend in many scientific disciplines to support researchers by providing enhanced information access through linking of publications and underlying datasets, so as to support research with infrastructure to enhance reproducibility and reusability of research results. In this research note, we present an overview of an ongoing research project, named VADIS (VAriable Detection, Interlinking and Summarization), that aims at developing technology and infrastructure for enhanced information access in the Social Sciences via search and summarization of publications on the basis of automatic identification and indexing of survey variables in text. We provide an overview of the overarching vision underlying our project, its main components, and related challenges, as well as a thorough discussion of how these are meant to address the limitations of current information access systems for publications in the Social Sciences. We show how this goal can be concretely implemented in an end-user system by presenting a search prototype, which is based on user requirements collected from qualitative interviews with empirical Social Science researchers.
ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering System
May 30, 2022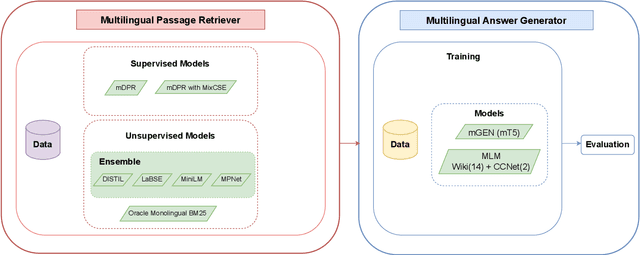



This paper introduces our proposed system for the MIA Shared Task on Cross-lingual Open-retrieval Question Answering (COQA). In this challenging scenario, given an input question the system has to gather evidence documents from a multilingual pool and generate from them an answer in the language of the question. We devised several approaches combining different model variants for three main components: Data Augmentation, Passage Retrieval, and Answer Generation. For passage retrieval, we evaluated the monolingual BM25 ranker against the ensemble of re-rankers based on multilingual pretrained language models (PLMs) and also variants of the shared task baseline, re-training it from scratch using a recently introduced contrastive loss that maintains a strong gradient signal throughout training by means of mixed negative samples. For answer generation, we focused on language- and domain-specialization by means of continued language model (LM) pretraining of existing multilingual encoders. Additionally, for both passage retrieval and answer generation, we augmented the training data provided by the task organizers with automatically generated question-answer pairs created from Wikipedia passages to mitigate the issue of data scarcity, particularly for the low-resource languages for which no training data were provided. Our results show that language- and domain-specialization as well as data augmentation help, especially for low-resource languages.
Cross-Lingual Citations in English Papers: A Large-Scale Analysis of Prevalence, Usage, and Impact
Nov 10, 2021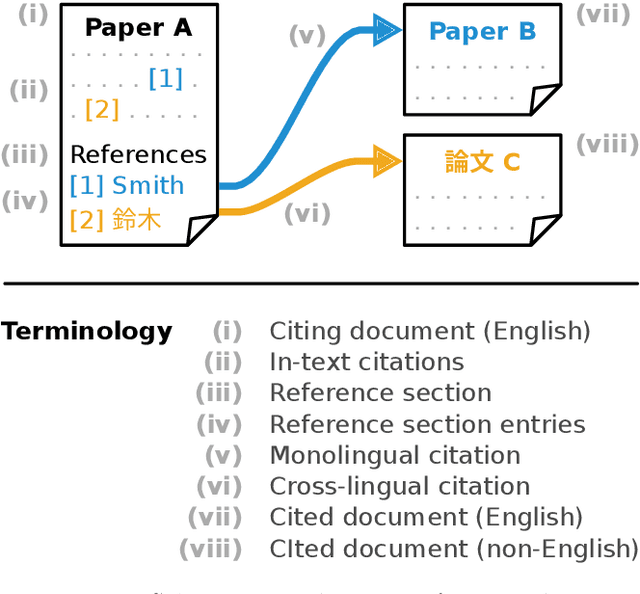

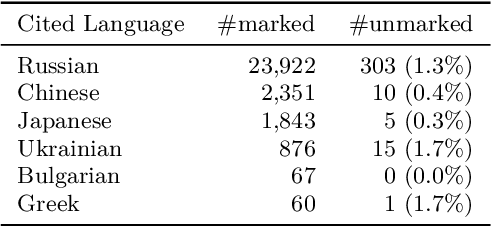
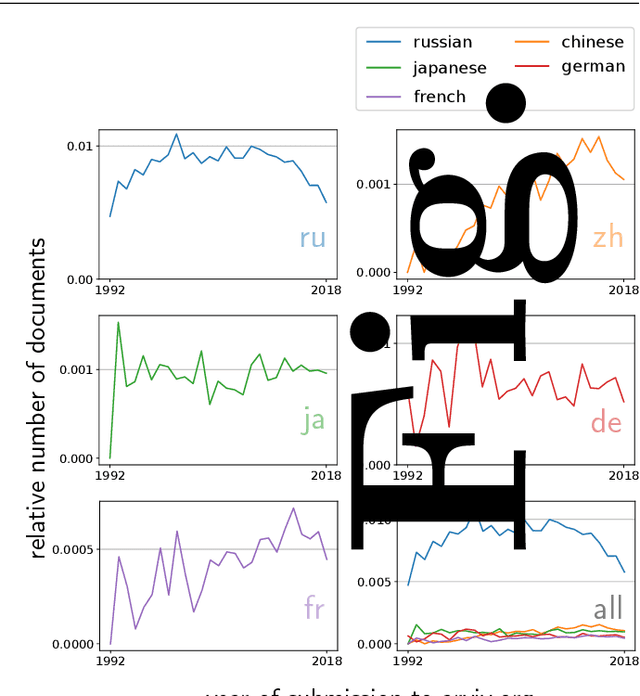
Citation information in scholarly data is an important source of insight into the reception of publications and the scholarly discourse. Outcomes of citation analyses and the applicability of citation based machine learning approaches heavily depend on the completeness of such data. One particular shortcoming of scholarly data nowadays is that non-English publications are often not included in data sets, or that language metadata is not available. Because of this, citations between publications of differing languages (cross-lingual citations) have only been studied to a very limited degree. In this paper, we present an analysis of cross-lingual citations based on over one million English papers, spanning three scientific disciplines and a time span of three decades. Our investigation covers differences between cited languages and disciplines, trends over time, and the usage characteristics as well as impact of cross-lingual citations. Among our findings are an increasing rate of citations to publications written in Chinese, citations being primarily to local non-English languages, and consistency in citation intent between cross- and monolingual citations. To facilitate further research, we make our collected data and source code publicly available.