 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You be More Social? Injecting Politeness and Positivity into Task-Oriented Conversational Agents
Dec 29, 2020
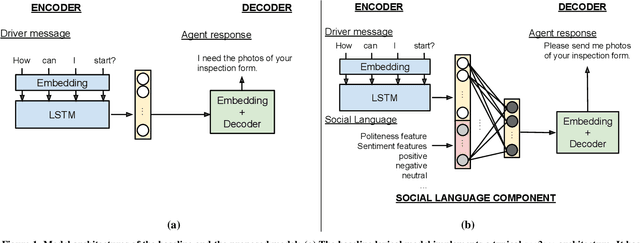


Goal-oriented conversational agents are becoming prevalent in our daily lives. For these systems to engage users and achieve their goals, they need to exhibit appropriate social behavior as well as provide informative replies that guide users through tasks. The first component of the research in this paper applies statistical modeling techniques to understand conversations between users and human agents for customer service. Analyses show that social language used by human agents is associated with greater users' responsiveness and task completion. The second component of the research is the construction of a conversational agent model capable of injecting social language into an agent's responses while still preserving content. The model uses a sequence-to-sequence deep learning architecture, extended with a social language understanding element. Evaluation in terms of content preservation and social language level using both human judgment and automatic linguistic measures shows that the model can generate responses that enable agents to address users' issues in a more socially appropriate way.
Interactive Teaching for Conversational AI
Dec 02, 2020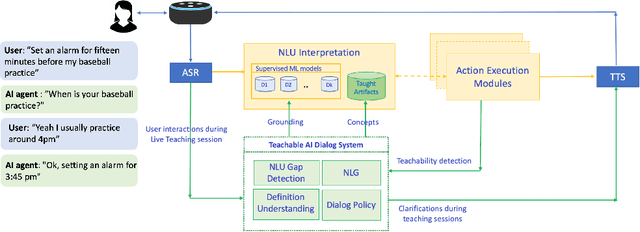
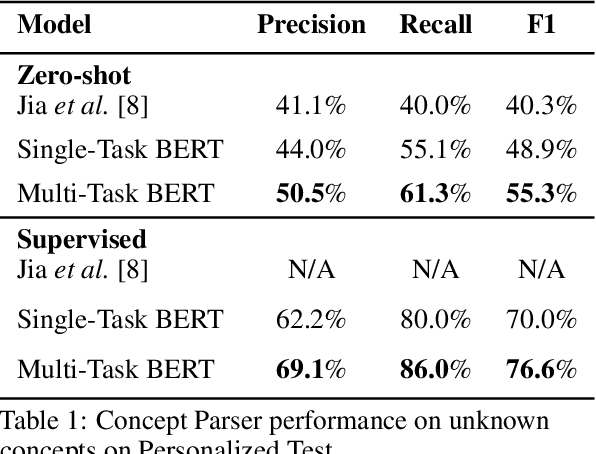
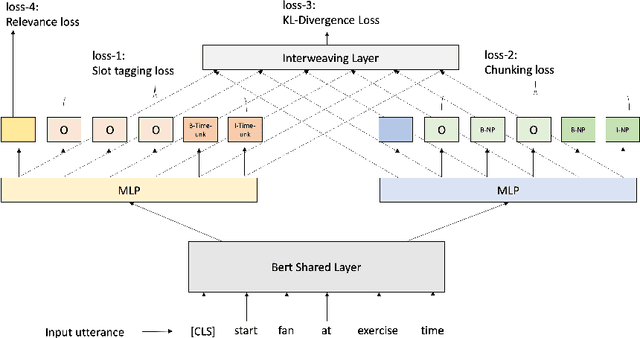
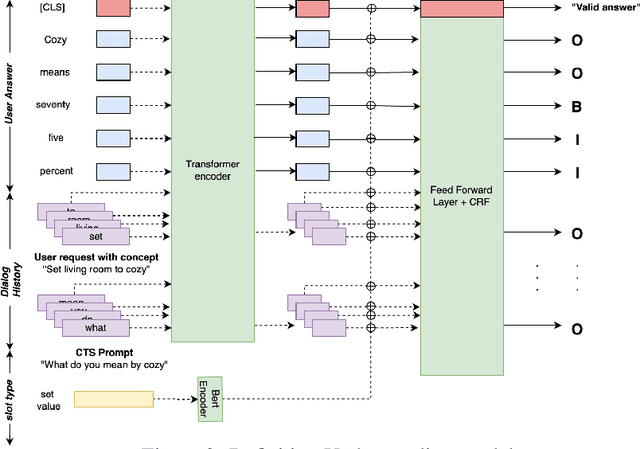
Current conversational AI systems aim to understand a set of pre-designed requests and execute related actions, which limits them to evolve naturally and adapt based on human interactions. Motivated by how children learn their first language interacting with adults, this paper describes a new Teachable AI system that is capable of learning new language nuggets called concepts, directly from end users using live interactive teaching sessions. The proposed setup uses three models to: a) Identify gaps in understanding automatically during live conversational interactions, b) Learn the respective interpretations of such unknown concepts from live interactions with users, and c) Manage a classroom sub-dialogue specifically tailored for interactive teaching sessions. We propose state-of-the-art transformer based neural architectures of models, fine-tuned on top of pre-trained models, and show accuracy improvements on the respective components. We demonstrate that this method is very promising in leading way to build more adaptive and personalized language understanding models.
LRTA: A Transparent Neural-Symbolic Reasoning Framework with Modular Supervision for Visual Question Answering
Nov 21, 2020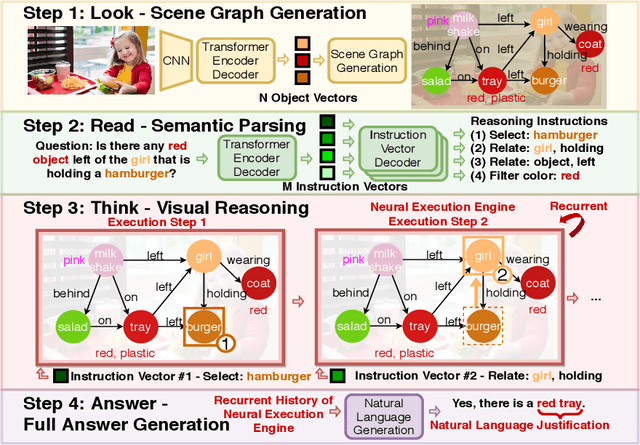
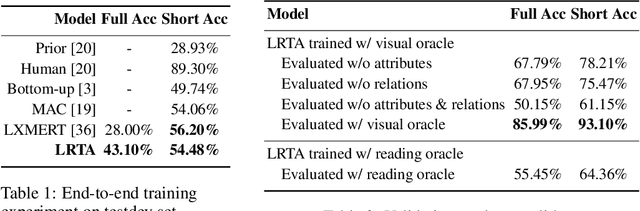
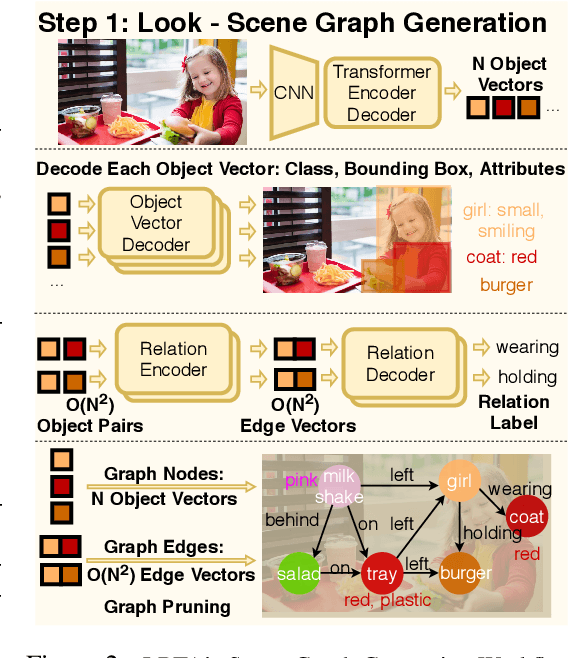
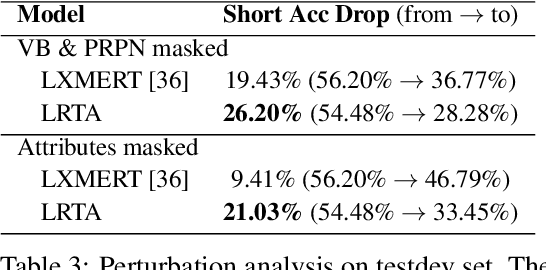
The predominant approach to visual question answering (VQA) relies on encoding the image and question with a "black-box" neural encoder and decoding a single token as the answer like "yes" or "no". Despite this approach's strong quantitative results, it struggles to come up with intuitive, human-readable forms of justification for the prediction process. To address this insufficiency, we reformulate VQA as a full answer generation task, which requires the model to justify its predictions in natural language. We propose LRTA [Look, Read, Think, Answer], a transparent neural-symbolic reasoning framework for visual question answering that solves the problem step-by-step like humans and provides human-readable form of justification at each step. Specifically, LRTA learns to first convert an image into a scene graph and parse a question into multiple reasoning instructions. It then executes the reasoning instructions one at a time by traversing the scene graph using a recurrent neural-symbolic execution module. Finally, it generates a full answer to the given question with natural language justifications. Our experiments on GQA dataset show that LRTA outperforms the state-of-the-art model by a large margin (43.1% v.s. 28.0%) on the full answer generation task. We also create a perturbed GQA test set by removing linguistic cues (attributes and relations) in the questions for analyzing whether a model is having a smart guess with superficial data correlations. We show that LRTA makes a step towards truly understanding the question while the state-of-the-art model tends to learn superficial correlations from the training data.
Language Model is All You Need: Natural Language Understanding as Question Answering
Nov 05, 2020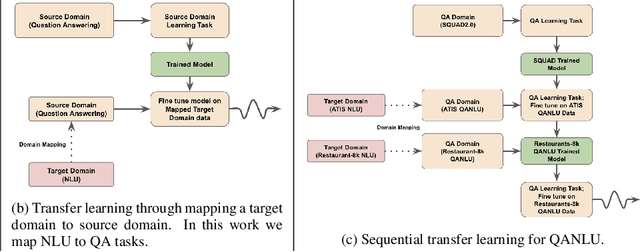
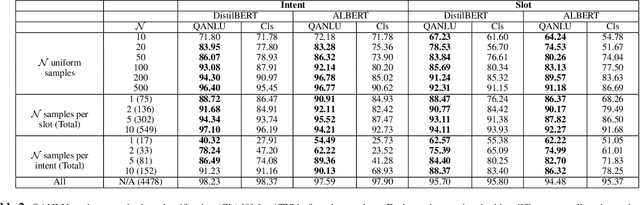
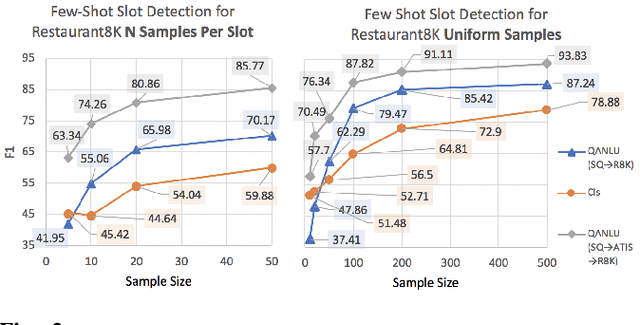
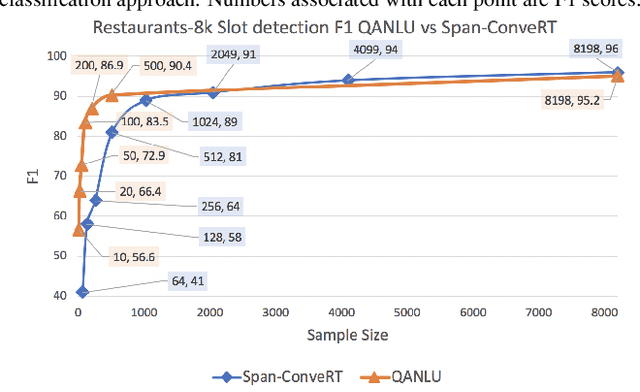
Different flavors of transfer learning have shown tremendous impact in advancing research and applications of machine learning. In this work we study the use of a specific family of transfer learning, where the target domain is mapped to the source domain. Specifically we map Natural Language Understanding (NLU) problems to QuestionAnswering (QA) problems and we show that in low data regimes this approach offers significant improvements compared to other approaches to NLU. Moreover we show that these gains could be increased through sequential transfer learning across NLU problems from different domains. We show that our approach could reduce the amount of required data for the same performance by up to a factor of 10.
Warped Language Models for Noise Robust Language Understanding
Nov 03, 2020
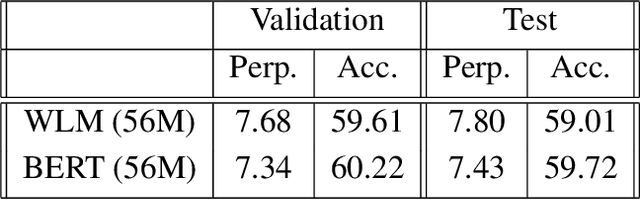
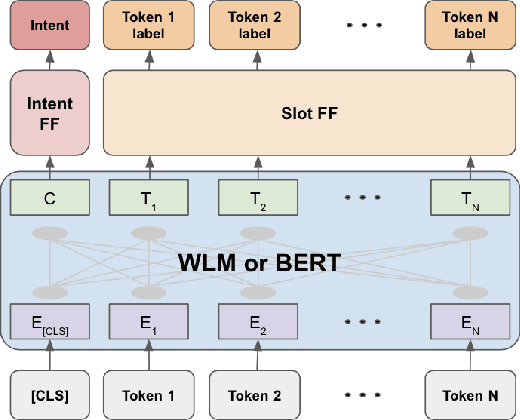
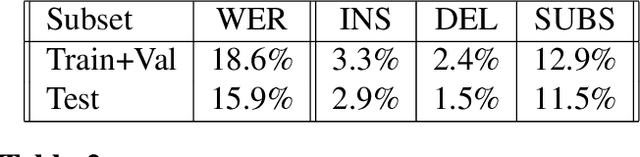
Masked Language Models (MLM) are self-supervised neural networks trained to fill in the blanks in a given sentence with masked tokens. Despite the tremendous success of MLMs for various text based tasks, they are not robust for spoken language understanding, especially for spontaneous conversational speech recognition noise. In this work we introduce Warped Language Models (WLM) in which input sentences at training time go through the same modifications as in MLM, plus two additional modifications, namely inserting and dropping random tokens. These two modifications extend and contract the sentence in addition to the modifications in MLMs, hence the word "warped" in the name. The insertion and drop modification of the input text during training of WLM resemble the types of noise due to Automatic Speech Recognition (ASR) errors, and as a result WLMs are likely to be more robust to ASR noise. Through computational results we show that natural language understanding systems built on top of WLMs perform better compared to those built based on MLMs, especially in the presence of ASR errors.
Controllable Text Generation with Focused Variation
Sep 25, 2020
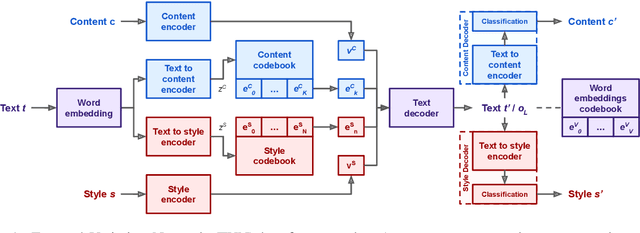
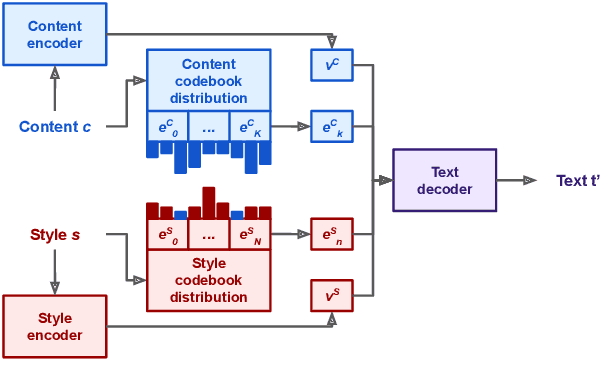
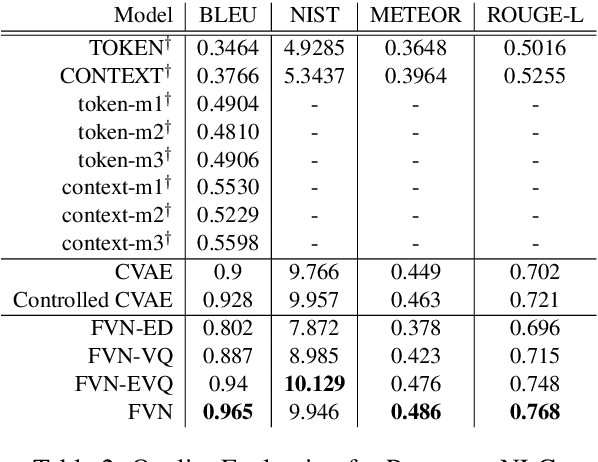
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
Improving Embedding Extraction for Speaker Verification with Ladder Network
Mar 20, 2020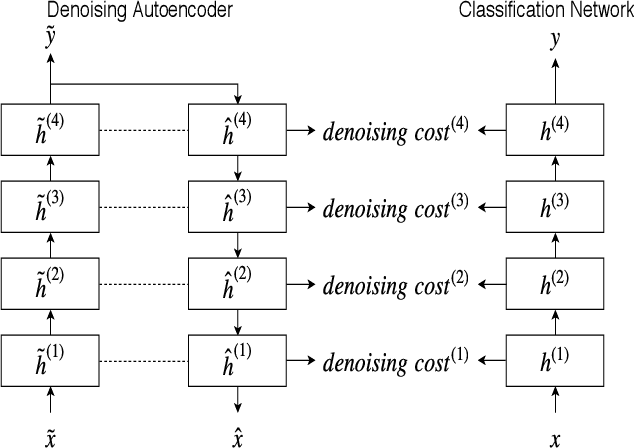
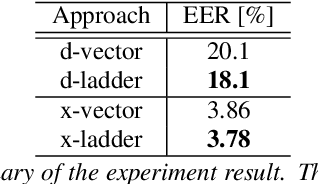
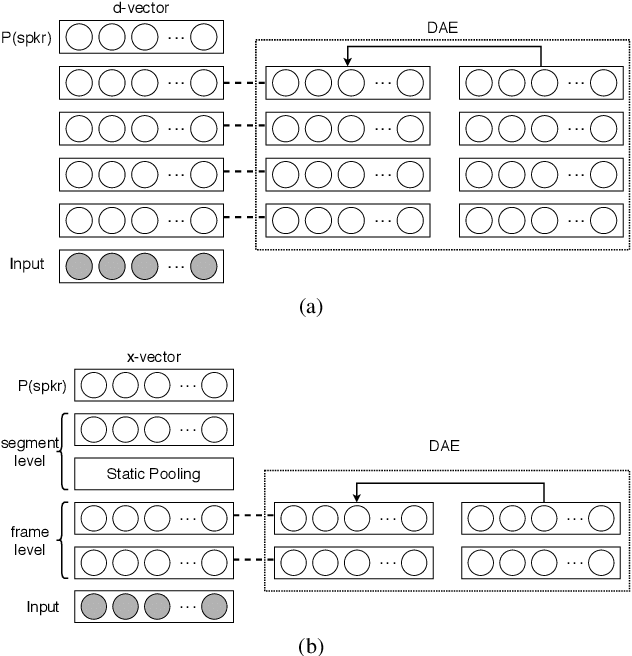
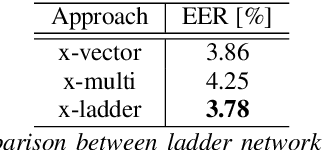
Speaker verification is an established yet challenging task in speech processing and a very vibrant research area. Recent speaker verification (SV) systems rely on deep neural networks to extract high-level embeddings which are able to characterize the users' voices. Most of the studies have investigated on improving the discriminability of the networks to extract better embeddings for performances improvement. However, only few research focus on improving the generalization. In this paper, we propose to apply the ladder network framework in the SV systems, which combines the supervised and unsupervised learning fashions. The ladder network can make the system to have better high-level embedding by balancing the trade-off to keep/discard as much useful/useless information as possible. We evaluated the framework on two state-of-the-art SV systems, d-vector and x-vector, which can be used for different use cases. The experiments showed that the proposed approach relatively improved the performance by 10% at most without adding parameters and augmented data.
Multi-Task Siamese Neural Network for Improving Replay Attack Detection
Feb 16, 2020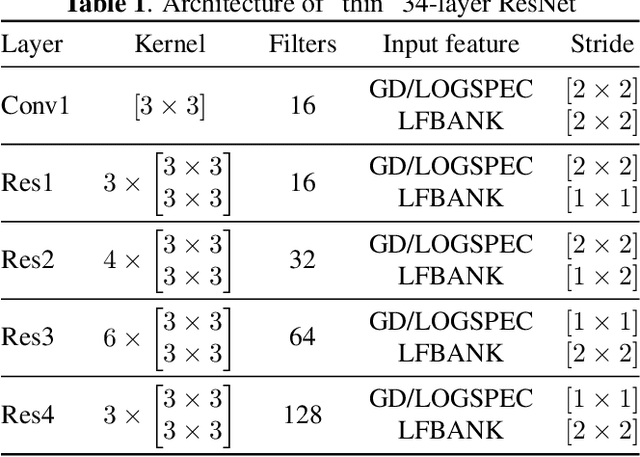
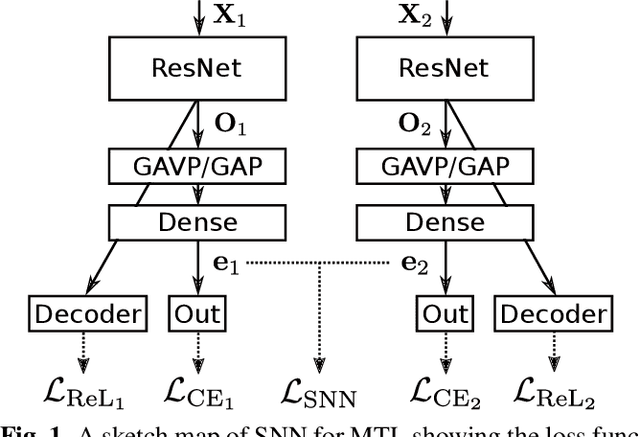
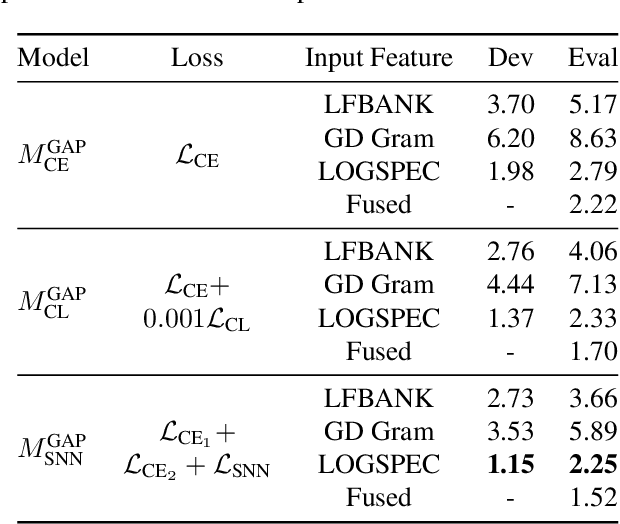
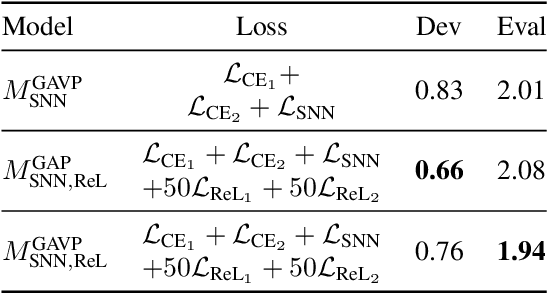
Automatic speaker verification systems are vulnerable to audio replay attacks which bypass security by replaying recordings of authorized speakers. Replay attack detection (RA) detection systems built upon Residual Neural Networks (ResNet)s have yielded astonishing results on the public benchmark ASVspoof 2019 Physical Access challenge. With most teams using fine-tuned feature extraction pipelines and model architectures, the generalizability of such systems remains questionable though. In this work, we analyse the effect of discriminative feature learning in a multi-task learning (MTL) setting can have on the generalizability and discriminability of RA detection systems. We use a popular ResNet architecture optimized by the cross-entropy criterion as our baseline and compare it to the same architecture optimized by MTL using Siamese Neural Networks (SNN). It can be shown that SNN outperform the baseline by relative 26.8 % Equal Error Rate (EER). We further enhance the model's architecture and demonstrate that SNN with additional reconstruction loss yield another significant improvement of relative 13.8 % EER.
Joint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020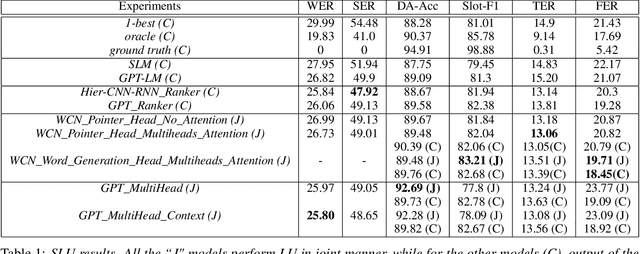
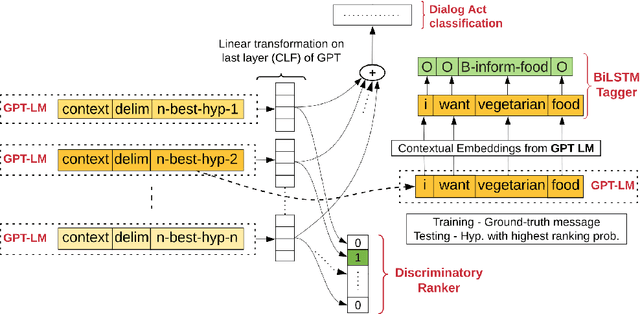
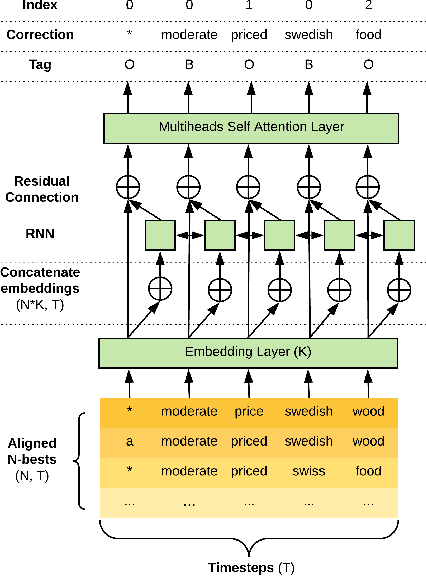
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

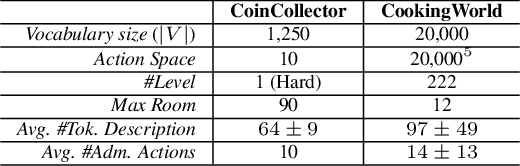
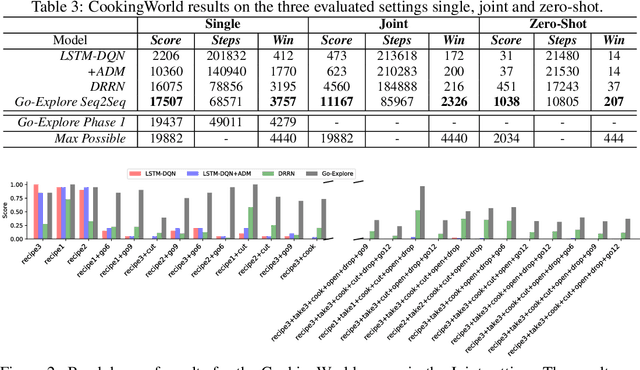
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.