 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-free inference with an improved cross-entropy estimator
Aug 02, 2018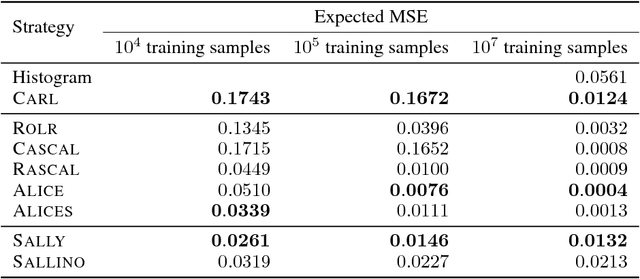
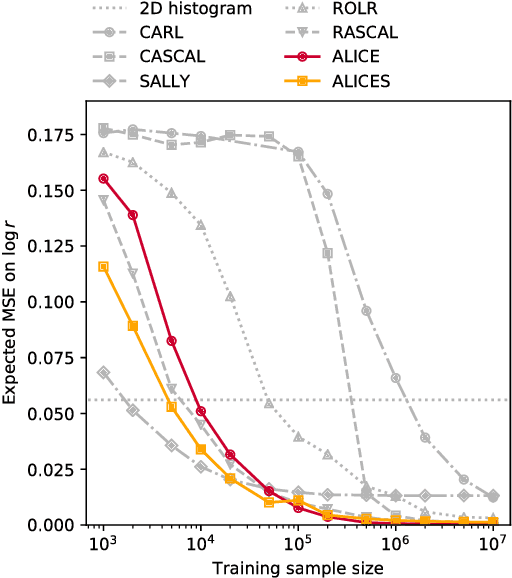
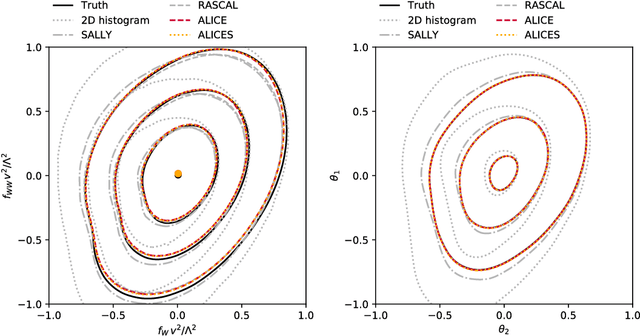
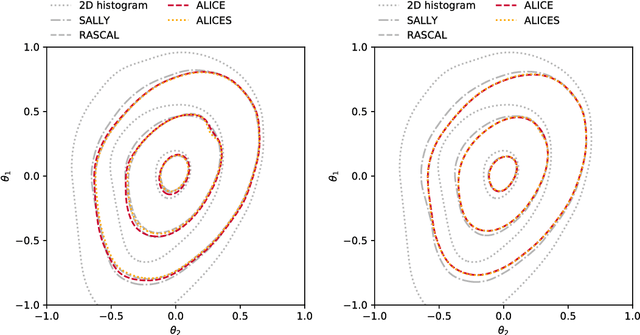
We extend recent work (Brehmer, et. al., 2018) that use neural networks as surrogate models for likelihood-free inference. As in the previous work, we exploit the fact that the joint likelihood ratio and joint score, conditioned on both observed and latent variables, can often be extracted from an implicit generative model or simulator to augment the training data for these surrogate models. We show how this augmented training data can be used to provide a new cross-entropy estimator, which provides improved sample efficiency compared to previous loss functions exploiting this augmented training data.
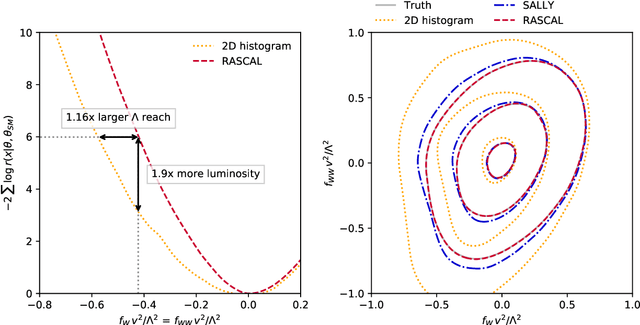
A Guide to Constraining Effective Field Theories with Machine Learning
Jul 26, 2018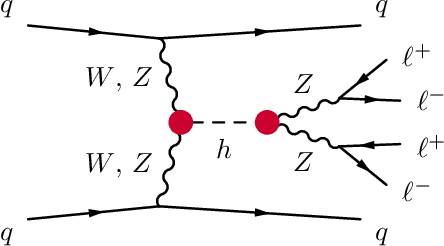
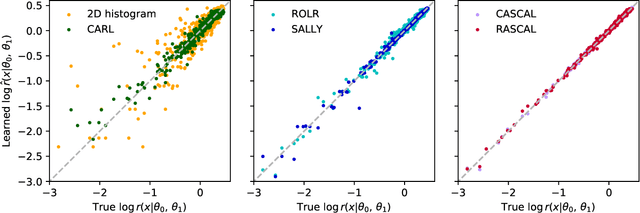
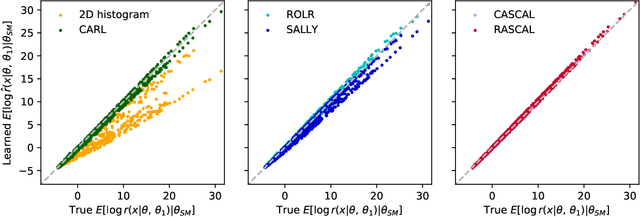
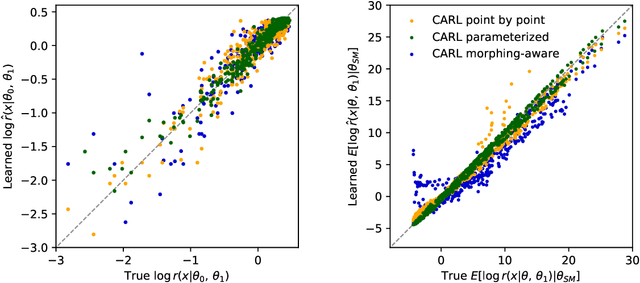
We develop, discuss, and compare several inference techniques to constrain theory parameters in collider experiments. By harnessing the latent-space structure of particle physics processes, we extract extra information from the simulator. This augmented data can be used to train neural networks that precisely estimate the likelihood ratio. The new methods scale well to many observables and high-dimensional parameter spaces, do not require any approximations of the parton shower and detector response, and can be evaluated in microseconds. Using weak-boson-fusion Higgs production as an example process, we compare the performance of several techniques. The best results are found for likelihood ratio estimators trained with extra information about the score, the gradient of the log likelihood function with respect to the theory parameters. The score also provides sufficient statistics that contain all the information needed for inference in the neighborhood of the Standard Model. These methods enable us to put significantly stronger bounds on effective dimension-six operators than the traditional approach based on histograms. They also outperform generic machine learning methods that do not make use of the particle physics structure, demonstrating their potential to substantially improve the new physics reach of the LHC legacy results.
* See also the companion publication "Constraining Effective Field Theories with Machine Learning" at arXiv:1805.00013, a brief introduction presenting the key ideas. The code for these studies is available at https://github.com/johannbrehmer/higgs_inference . v2: Added references. v3: Improved description of algorithms, added references. v4: Clarified text, added references
Constraining Effective Field Theories with Machine Learning
Jul 26, 2018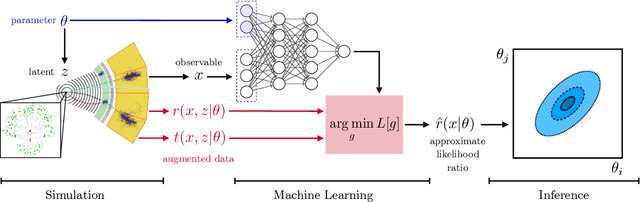
We present powerful new analysis techniques to constrain effective field theories at the LHC. By leveraging the structure of particle physics processes, we extract extra information from Monte-Carlo simulations, which can be used to train neural network models that estimate the likelihood ratio. These methods scale well to processes with many observables and theory parameters, do not require any approximations of the parton shower or detector response, and can be evaluated in microseconds. We show that they allow us to put significantly stronger bounds on dimension-six operators than existing methods, demonstrating their potential to improve the precision of the LHC legacy constraints.
* See also the companion publication "A Guide to Constraining Effective Field Theories with Machine Learning" at arXiv:1805.00020, an in-depth analysis of machine learning techniques for LHC measurements. The code for these studies is available at https://github.com/johannbrehmer/higgs_inference . v2: New schematic figure explaining the new algorithms, added references. v3, v4: Added references
QCD-Aware Recursive Neural Networks for Jet Physics
Jul 13, 2018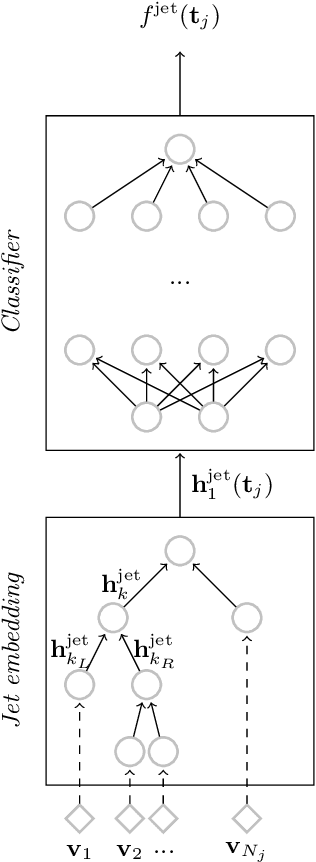
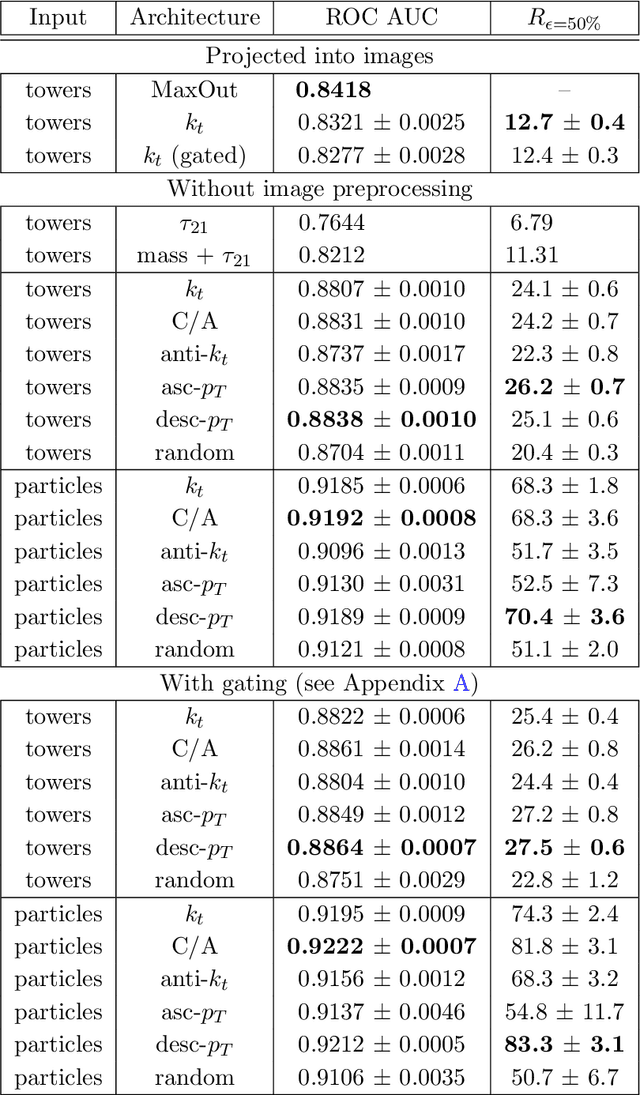
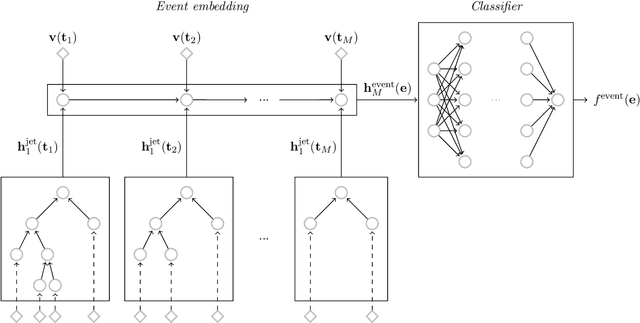
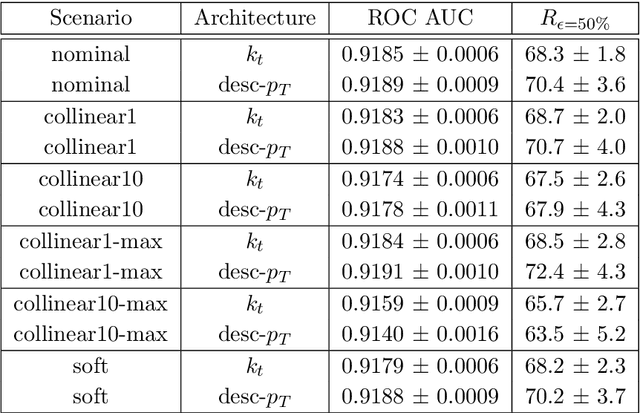
Recent progress in applying machine learning for jet physics has been built upon an analogy between calorimeters and images. In this work, we present a novel class of recursive neural networks built instead upon an analogy between QCD and natural languages. In the analogy, four-momenta are like words and the clustering history of sequential recombination jet algorithms is like the parsing of a sentence. Our approach works directly with the four-momenta of a variable-length set of particles, and the jet-based tree structure varies on an event-by-event basis. Our experiments highlight the flexibility of our method for building task-specific jet embeddings and show that recursive architectures are significantly more accurate and data efficient than previous image-based networks. We extend the analogy from individual jets (sentences) to full events (paragraphs), and show for the first time an event-level classifier operating on all the stable particles produced in an LHC event.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018
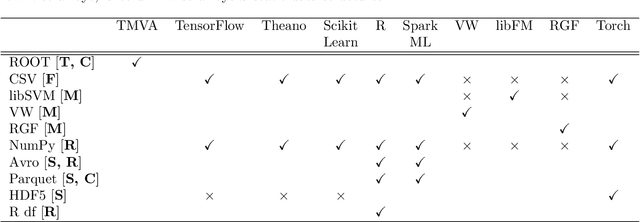

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.
Scikit-learn: Machine Learning in Python
Jun 05, 2018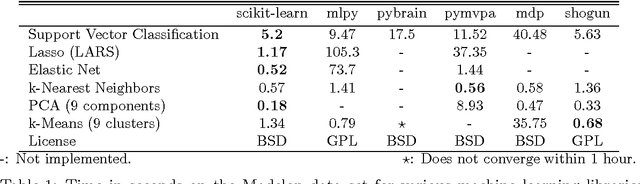
Scikit-learn is a Python module integrating a wide range of state-of-the-art machine learning algorithms for medium-scale supervised and unsupervised problems. This package focuses on bringing machine learning to non-specialists using a general-purpose high-level language. Emphasis is put on ease of use, performance, documentation, and API consistency. It has minimal dependencies and is distributed under the simplified BSD license, encouraging its use in both academic and commercial settings. Source code, binaries, and documentation can be downloaded from http://scikit-learn.org.
* Update authors list and URLs
Gradient Energy Matching for Distributed Asynchronous Gradient Descent
May 22, 2018
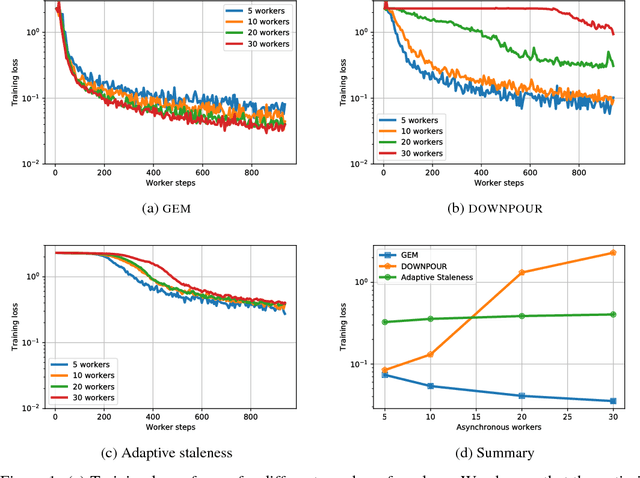
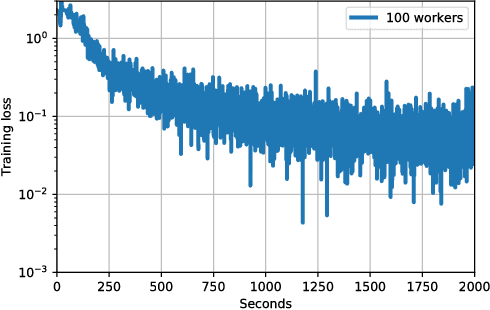
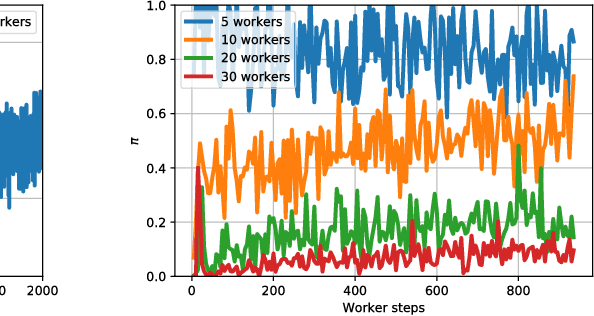
Distributed asynchronous SGD has become widely used for deep learning in large-scale systems, but remains notorious for its instability when increasing the number of workers. In this work, we study the dynamics of distributed asynchronous SGD under the lens of Lagrangian mechanics. Using this description, we introduce the concept of energy to describe the optimization process and derive a sufficient condition ensuring its stability as long as the collective energy induced by the active workers remains below the energy of a target synchronous process. Making use of this criterion, we derive a stable distributed asynchronous optimization procedure, GEM, that estimates and maintains the energy of the asynchronous system below or equal to the energy of sequential SGD with momentum. Experimental results highlight the stability and speedup of GEM compared to existing schemes, even when scaling to one hundred asynchronous workers. Results also indicate better generalization compared to the targeted SGD with momentum.
Improvements to Inference Compilation for Probabilistic Programming in Large-Scale Scientific Simulators
Dec 21, 2017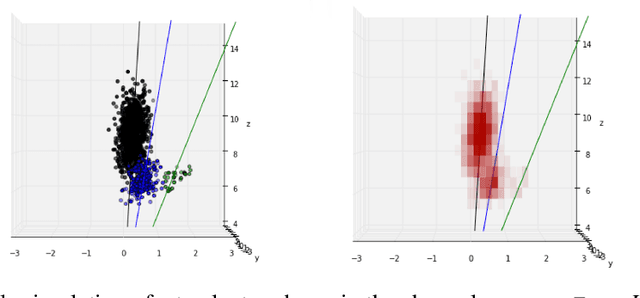
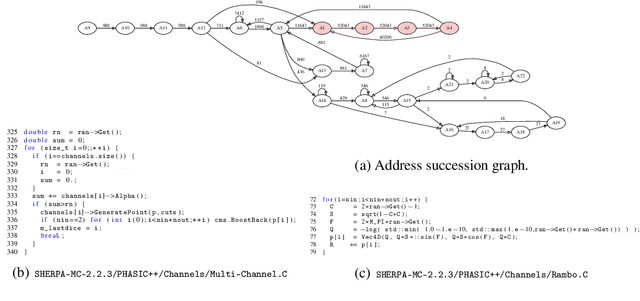
We consider the problem of Bayesian inference in the family of probabilistic models implicitly defined by stochastic generative models of data. In scientific fields ranging from population biology to cosmology, low-level mechanistic components are composed to create complex generative models. These models lead to intractable likelihoods and are typically non-differentiable, which poses challenges for traditional approaches to inference. We extend previous work in "inference compilation", which combines universal probabilistic programming and deep learning methods, to large-scale scientific simulators, and introduce a C++ based probabilistic programming library called CPProb. We successfully use CPProb to interface with SHERPA, a large code-base used in particle physics. Here we describe the technical innovations realized and planned for this library.
Random Subspace with Trees for Feature Selection Under Memory Constraints
Sep 06, 2017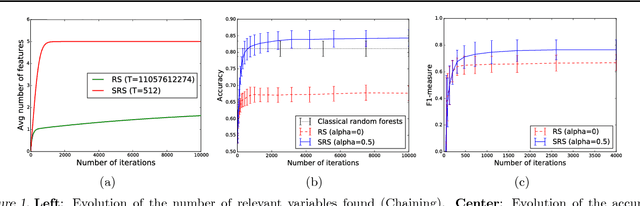
Dealing with datasets of very high dimension is a major challenge in machine learning. In this paper, we consider the problem of feature selection in applications where the memory is not large enough to contain all features. In this setting, we propose a novel tree-based feature selection approach that builds a sequence of randomized trees on small subsamples of variables mixing both variables already identified as relevant by previous models and variables randomly selected among the other variables. As our main contribution, we provide an in-depth theoretical analysis of this method in infinite sample setting. In particular, we study its soundness with respect to common definitions of feature relevance and its convergence speed under various variable dependance scenarios. We also provide some preliminary empirical results highlighting the potential of the approach.
Learning to Pivot with Adversarial Networks
Jun 01, 2017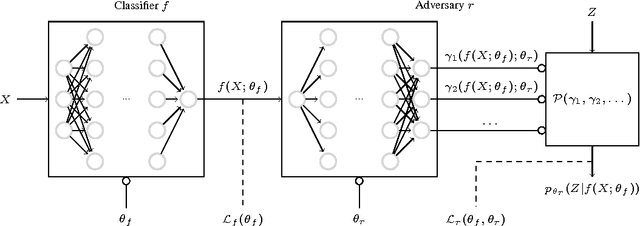
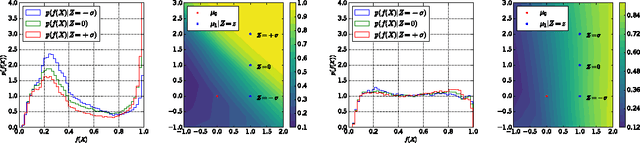
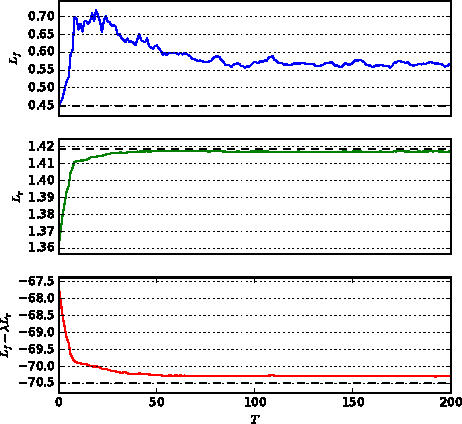
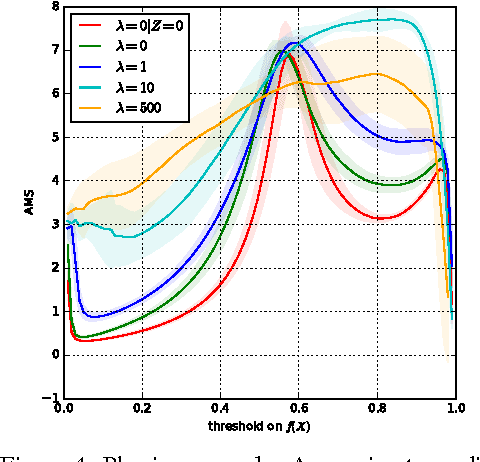
Several techniques for domain adaptation have been proposed to account for differences in the distribution of the data used for training and testing. The majority of this work focuses on a binary domain label. Similar problems occur in a scientific context where there may be a continuous family of plausible data generation processes associated to the presence of systematic uncertainties. Robust inference is possible if it is based on a pivot -- a quantity whose distribution does not depend on the unknown values of the nuisance parameters that parametrize this family of data generation processes. In this work, we introduce and derive theoretical results for a training procedure based on adversarial networks for enforcing the pivotal property (or, equivalently, fairness with respect to continuous attributes) on a predictive model. The method includes a hyperparameter to control the trade-off between accuracy and robustness. We demonstrate the effectiveness of this approach with a toy example and examples from particle physics.