 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
Apr 26, 2018

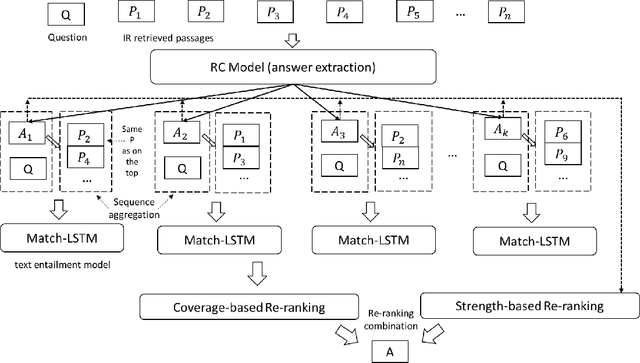
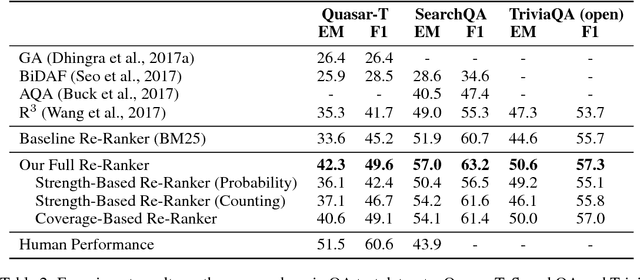
A popular recent approach to answering open-domain questions is to first search for question-related passages and then apply reading comprehension models to extract answers. Existing methods usually extract answers from single passages independently. But some questions require a combination of evidence from across different sources to answer correctly. In this paper, we propose two models which make use of multiple passages to generate their answers. Both use an answer-reranking approach which reorders the answer candidates generated by an existing state-of-the-art QA model. We propose two methods, namely, strength-based re-ranking and coverage-based re-ranking, to make use of the aggregated evidence from different passages to better determine the answer. Our models have achieved state-of-the-art results on three public open-domain QA datasets: Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8 percentage points of improvement over the former two datasets.
Eigenoption Discovery through the Deep Successor Representation
Feb 23, 2018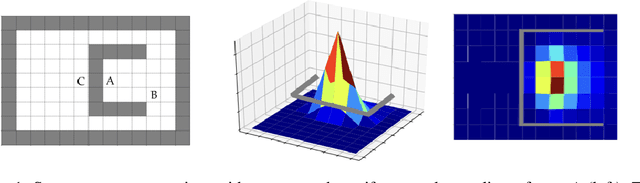
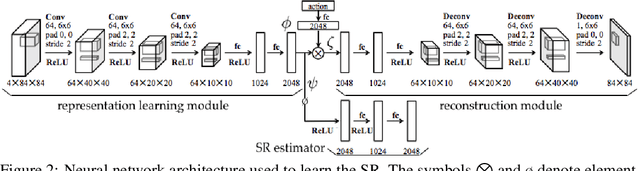
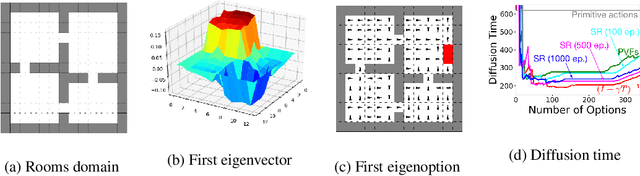
Options in reinforcement learning allow agents to hierarchically decompose a task into subtasks, having the potential to speed up learning and planning. However, autonomously learning effective sets of options is still a major challenge in the field. In this paper we focus on the recently introduced idea of using representation learning methods to guide the option discovery process. Specifically, we look at eigenoptions, options obtained from representations that encode diffusive information flow in the environment. We extend the existing algorithms for eigenoption discovery to settings with stochastic transitions and in which handcrafted features are not available. We propose an algorithm that discovers eigenoptions while learning non-linear state representations from raw pixels. It exploits recent successes in the deep reinforcement learning literature and the equivalence between proto-value functions and the successor representation. We use traditional tabular domains to provide intuition about our approach and Atari 2600 games to demonstrate its potential.
The Eigenoption-Critic Framework
Dec 11, 2017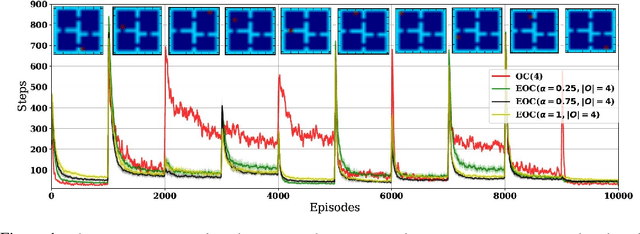
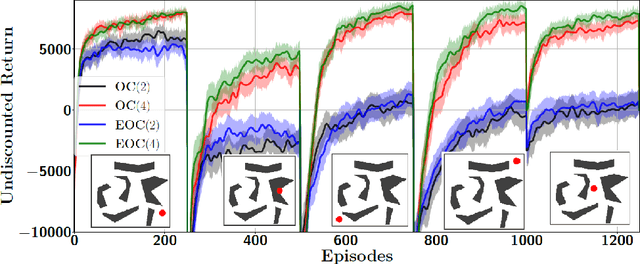
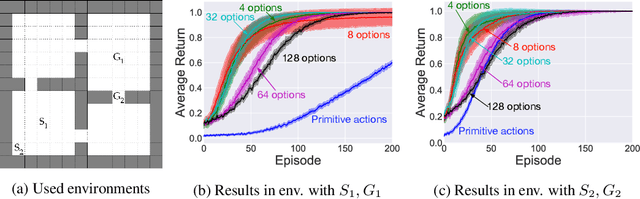
Eigenoptions (EOs) have been recently introduced as a promising idea for generating a diverse set of options through the graph Laplacian, having been shown to allow efficient exploration. Despite its initial promising results, a couple of issues in current algorithms limit its application, namely: (1) EO methods require two separate steps (eigenoption discovery and reward maximization) to learn a control policy, which can incur a significant amount of storage and computation; (2) EOs are only defined for problems with discrete state-spaces and; (3) it is not easy to take the environment's reward function into consideration when discovering EOs. To addresses these issues, we introduce an algorithm termed eigenoption-critic (EOC) based on the Option-critic (OC) framework [Bacon17], a general hierarchical reinforcement learning (RL) algorithm that allows learning the intra-option policies simultaneously with the policy over options. We also propose a generalization of EOC to problems with continuous state-spaces through the Nystr\"om approximation. EOC can also be seen as extending OC to nonstationary settings, where the discovered options are not tailored for a single task.
Multiresolution Recurrent Neural Networks: An Application to Dialogue Response Generation
Jun 14, 2016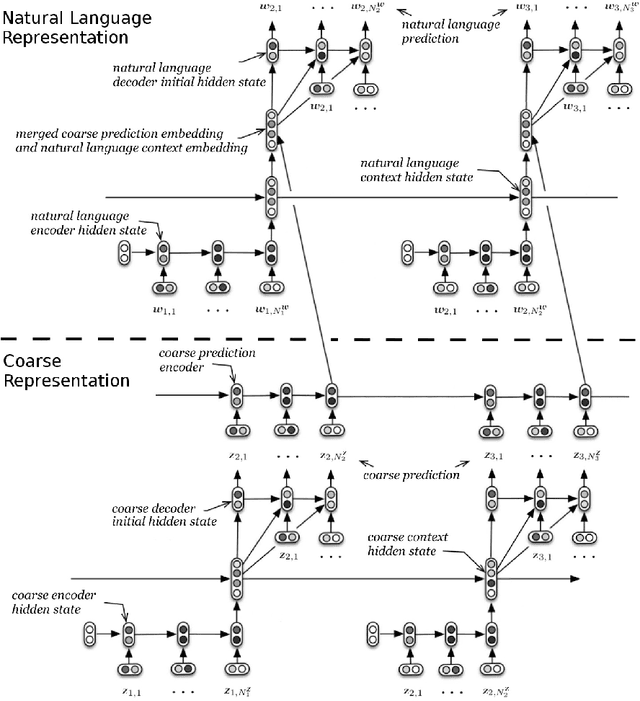
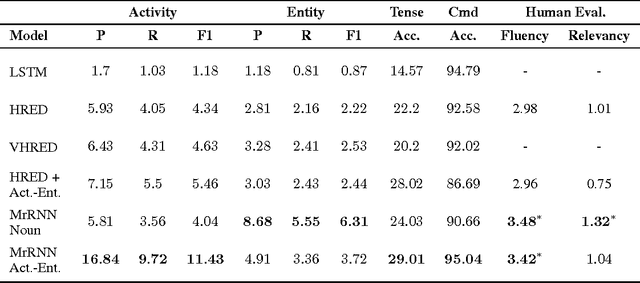

We introduce the multiresolution recurrent neural network, which extends the sequence-to-sequence framework to model natural language generation as two parallel discrete stochastic processes: a sequence of high-level coarse tokens, and a sequence of natural language tokens. There are many ways to estimate or learn the high-level coarse tokens, but we argue that a simple extraction procedure is sufficient to capture a wealth of high-level discourse semantics. Such procedure allows training the multiresolution recurrent neural network by maximizing the exact joint log-likelihood over both sequences. In contrast to the standard log- likelihood objective w.r.t. natural language tokens (word perplexity), optimizing the joint log-likelihood biases the model towards modeling high-level abstractions. We apply the proposed model to the task of dialogue response generation in two challenging domains: the Ubuntu technical support domain, and Twitter conversations. On Ubuntu, the model outperforms competing approaches by a substantial margin, achieving state-of-the-art results according to both automatic evaluation metrics and a human evaluation study. On Twitter, the model appears to generate more relevant and on-topic responses according to automatic evaluation metrics. Finally, our experiments demonstrate that the proposed model is more adept at overcoming the sparsity of natural language and is better able to capture long-term structure.
Hierarchical Memory Networks
May 24, 2016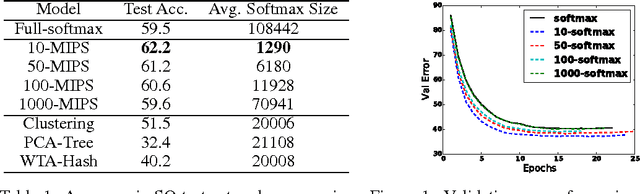
Memory networks are neural networks with an explicit memory component that can be both read and written to by the network. The memory is often addressed in a soft way using a softmax function, making end-to-end training with backpropagation possible. However, this is not computationally scalable for applications which require the network to read from extremely large memories. On the other hand, it is well known that hard attention mechanisms based on reinforcement learning are challenging to train successfully. In this paper, we explore a form of hierarchical memory network, which can be considered as a hybrid between hard and soft attention memory networks. The memory is organized in a hierarchical structure such that reading from it is done with less computation than soft attention over a flat memory, while also being easier to train than hard attention over a flat memory. Specifically, we propose to incorporate Maximum Inner Product Search (MIPS) in the training and inference procedures for our hierarchical memory network. We explore the use of various state-of-the art approximate MIPS techniques and report results on SimpleQuestions, a challenging large scale factoid question answering task.
Selecting Near-Optimal Learners via Incremental Data Allocation
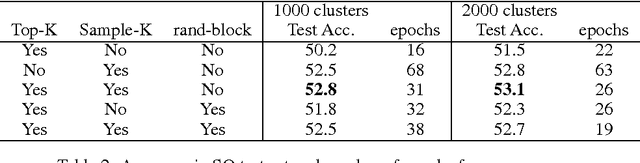
Dec 31, 2015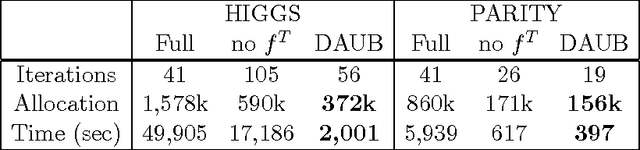
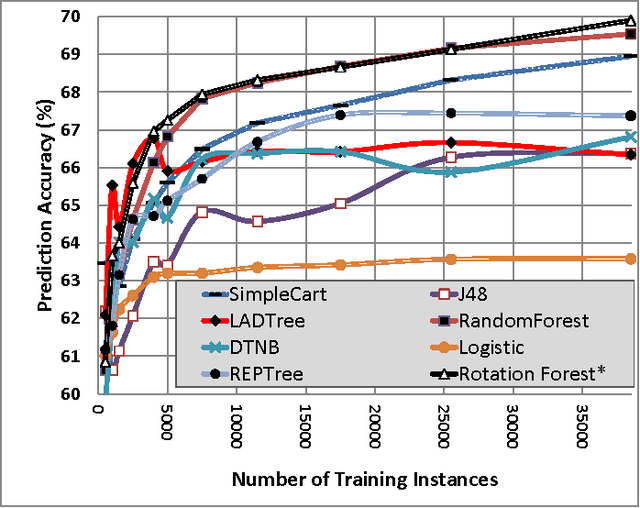
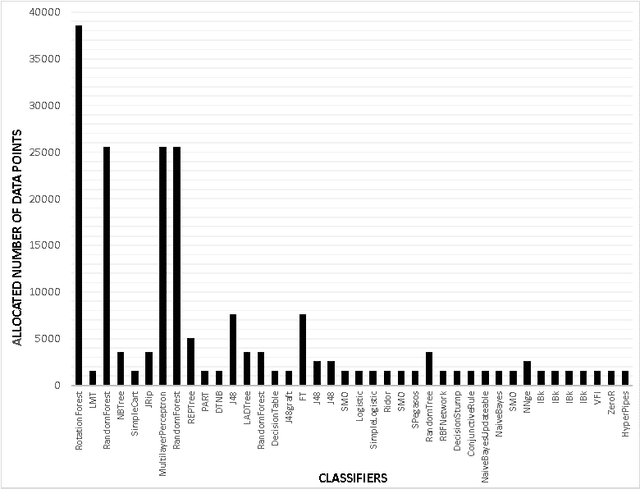
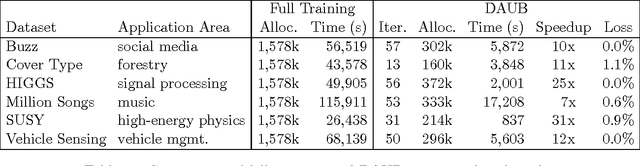
We study a novel machine learning (ML) problem setting of sequentially allocating small subsets of training data amongst a large set of classifiers. The goal is to select a classifier that will give near-optimal accuracy when trained on all data, while also minimizing the cost of misallocated samples. This is motivated by large modern datasets and ML toolkits with many combinations of learning algorithms and hyper-parameters. Inspired by the principle of "optimism under uncertainty," we propose an innovative strategy, Data Allocation using Upper Bounds (DAUB), which robustly achieves these objectives across a variety of real-world datasets. We further develop substantial theoretical support for DAUB in an idealized setting where the expected accuracy of a classifier trained on $n$ samples can be known exactly. Under these conditions we establish a rigorous sub-linear bound on the regret of the approach (in terms of misallocated data), as well as a rigorous bound on suboptimality of the selected classifier. Our accuracy estimates using real-world datasets only entail mild violations of the theoretical scenario, suggesting that the practical behavior of DAUB is likely to approach the idealized behavior.
Analysis of Watson's Strategies for Playing Jeopardy!
Feb 04, 2014
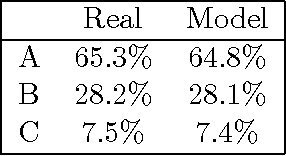
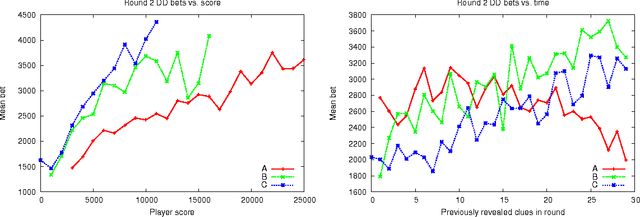
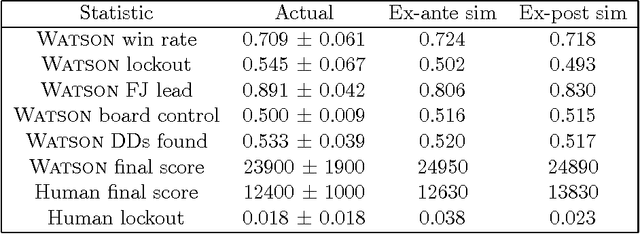
Major advances in Question Answering technology were needed for IBM Watson to play Jeopardy! at championship level -- the show requires rapid-fire answers to challenging natural language questions, broad general knowledge, high precision, and accurate confidence estimates. In addition, Jeopardy! features four types of decision making carrying great strategic importance: (1) Daily Double wagering; (2) Final Jeopardy wagering; (3) selecting the next square when in control of the board; (4) deciding whether to attempt to answer, i.e., "buzz in." Using sophisticated strategies for these decisions, that properly account for the game state and future event probabilities, can significantly boost a players overall chances to win, when compared with simple "rule of thumb" strategies. This article presents our approach to developing Watsons game-playing strategies, comprising development of a faithful simulation model, and then using learning and Monte-Carlo methods within the simulator to optimize Watsons strategic decision-making. After giving a detailed description of each of our game-strategy algorithms, we then focus in particular on validating the accuracy of the simulators predictions, and documenting performance improvements using our methods. Quantitative performance benefits are shown with respect to both simple heuristic strategies, and actual human contestant performance in historical episodes. We further extend our analysis of human play to derive a number of valuable and counterintuitive examples illustrating how human contestants may improve their performance on the show.
Bayesian Inference in Monte-Carlo Tree Search
Mar 15, 2012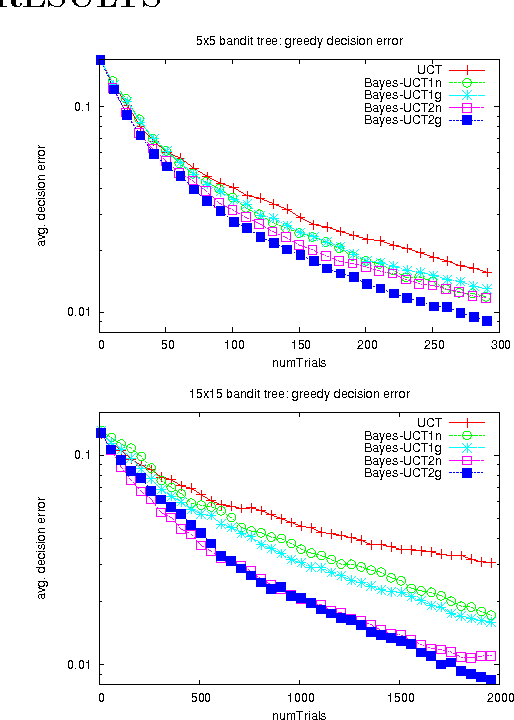
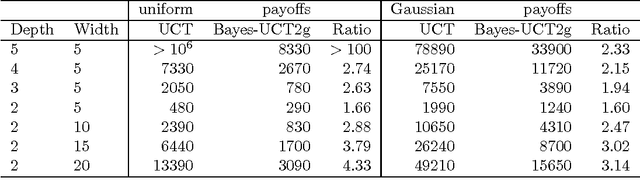
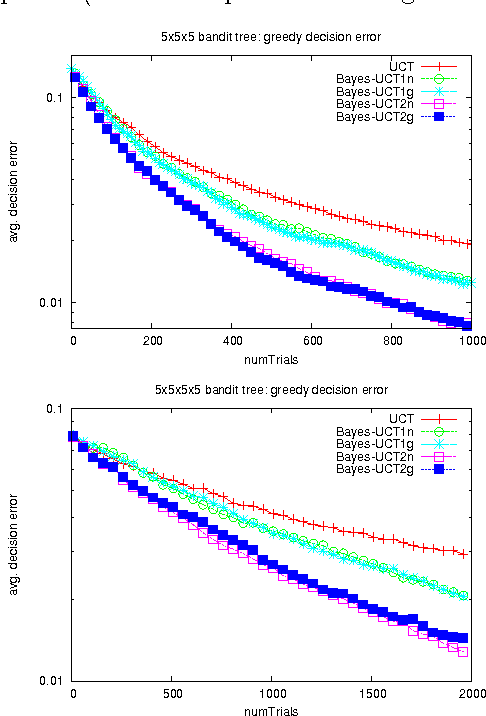

Monte-Carlo Tree Search (MCTS) methods are drawing great interest after yielding breakthrough results in computer Go. This paper proposes a Bayesian approach to MCTS that is inspired by distributionfree approaches such as UCT [13], yet significantly differs in important respects. The Bayesian framework allows potentially much more accurate (Bayes-optimal) estimation of node values and node uncertainties from a limited number of simulation trials. We further propose propagating inference in the tree via fast analytic Gaussian approximation methods: this can make the overhead of Bayesian inference manageable in domains such as Go, while preserving high accuracy of expected-value estimates. We find substantial empirical outperformance of UCT in an idealized bandit-tree test environment, where we can obtain valuable insights by comparing with known ground truth. Additionally we rigorously prove on-policy and off-policy convergence of the proposed methods.