 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Macro-Actions with Disentangled Effects for Efficient Planning with the Goal-Count Heuristic
Apr 28, 2020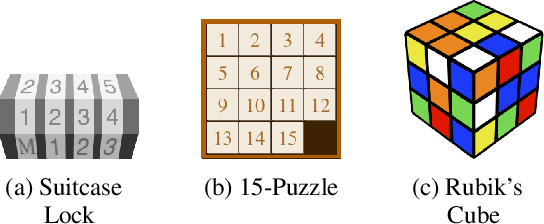

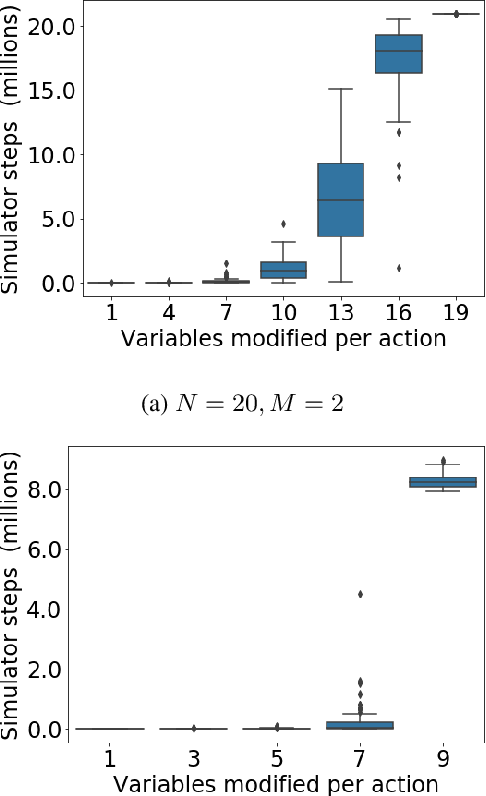

The difficulty of classical planning increases exponentially with search-tree depth. Heuristic search can make planning more efficient, but good heuristics often require domain-specific assumptions and may not generalize to new problems. Rather than treating the planning problem as fixed and carefully designing a heuristic to match it, we instead construct macro-actions that support efficient planning with the simple and general-purpose "goal-count" heuristic. Our approach searches for macro-actions that modify only a small number of state variables (we call this measure "entanglement"). We show experimentally that reducing entanglement exponentially decreases planning time with the goal-count heuristic. Our method discovers macro-actions with disentangled effects that dramatically improve planning efficiency for 15-puzzle and Rubik's cube, reliably solving each domain without prior knowledge, and solving Rubik's cube with orders of magnitude less data than competing approaches.
On the Role of Weight Sharing During Deep Option Learning
Feb 06, 2020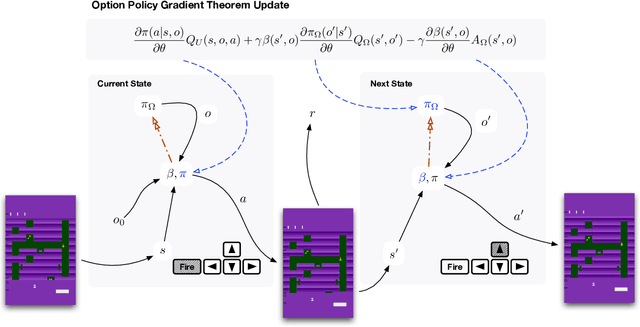
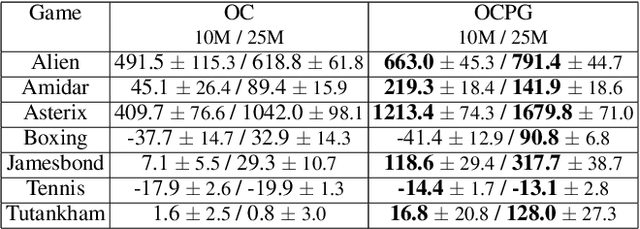


The options framework is a popular approach for building temporally extended actions in reinforcement learning. In particular, the option-critic architecture provides general purpose policy gradient theorems for learning actions from scratch that are extended in time. However, past work makes the key assumption that each of the components of option-critic has independent parameters. In this work we note that while this key assumption of the policy gradient theorems of option-critic holds in the tabular case, it is always violated in practice for the deep function approximation setting. We thus reconsider this assumption and consider more general extensions of option-critic and hierarchical option-critic training that optimize for the full architecture with each update. It turns out that not assuming parameter independence challenges a belief in prior work that training the policy over options can be disentangled from the dynamics of the underlying options. In fact, learning can be sped up by focusing the policy over options on states where options are actually likely to terminate. We put our new algorithms to the test in application to sample efficient learning of Atari games, and demonstrate significantly improved stability and faster convergence when learning long options.
Hybrid Reinforcement Learning with Expert State Sequences
Mar 11, 2019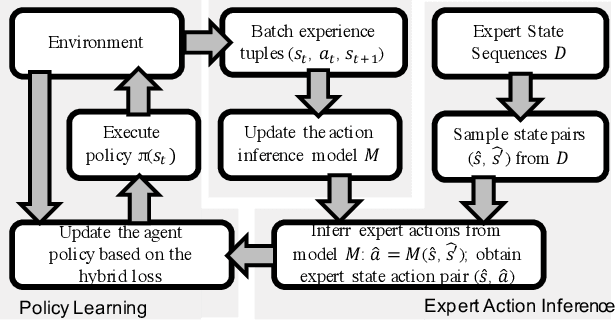
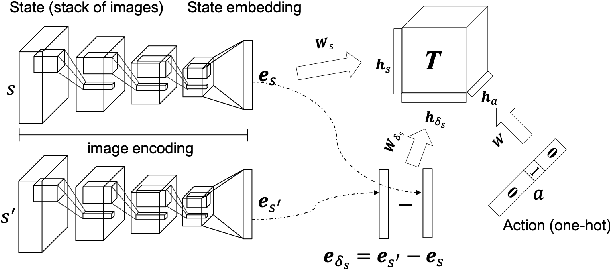
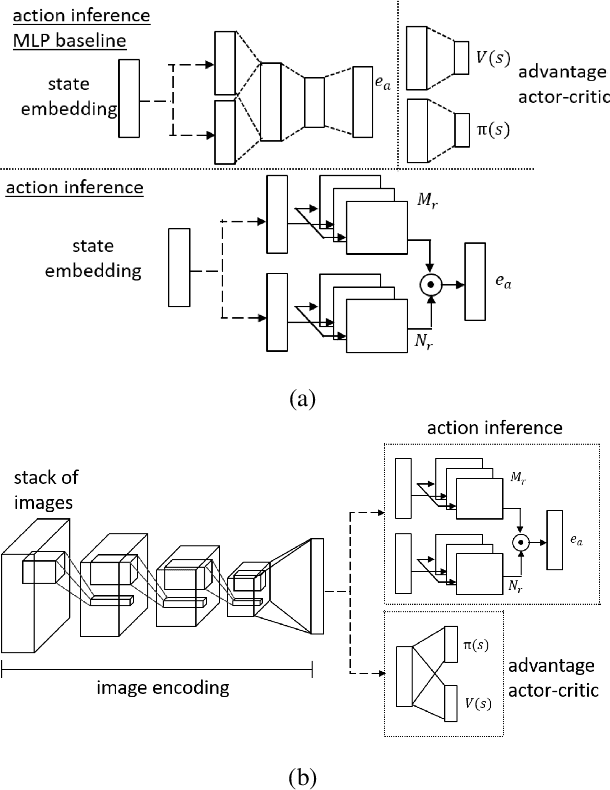
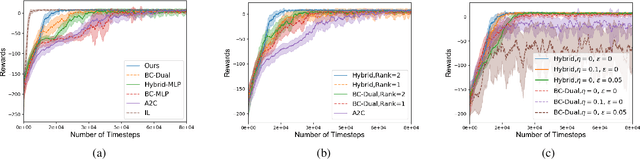
Existing imitation learning approaches often require that the complete demonstration data, including sequences of actions and states, are available. In this paper, we consider a more realistic and difficult scenario where a reinforcement learning agent only has access to the state sequences of an expert, while the expert actions are unobserved. We propose a novel tensor-based model to infer the unobserved actions of the expert state sequences. The policy of the agent is then optimized via a hybrid objective combining reinforcement learning and imitation learning. We evaluated our hybrid approach on an illustrative domain and Atari games. The empirical results show that (1) the agents are able to leverage state expert sequences to learn faster than pure reinforcement learning baselines, (2) our tensor-based action inference model is advantageous compared to standard deep neural networks in inferring expert actions, and (3) the hybrid policy optimization objective is robust against noise in expert state sequences.
Learning Hierarchical Teaching in Cooperative Multiagent Reinforcement Learning
Mar 07, 2019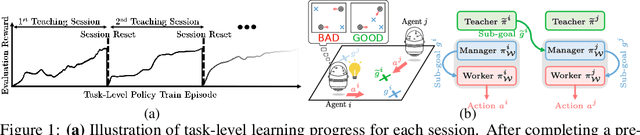
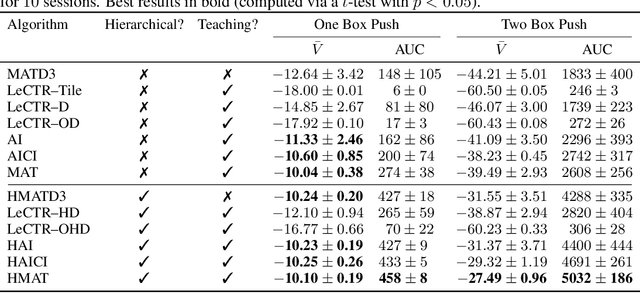
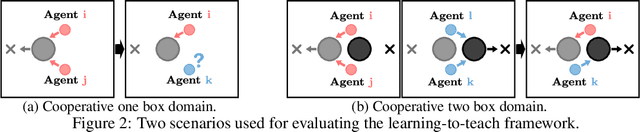

Heterogeneous knowledge naturally arises among different agents in cooperative multiagent reinforcement learning. As such, learning can be greatly improved if agents can effectively pass their knowledge on to other agents. Existing work has demonstrated that peer-to-peer knowledge transfer, a process referred to as action advising, improves team-wide learning. In contrast to previous frameworks that advise at the level of primitive actions, we aim to learn high-level teaching policies that decide when and what high-level action (e.g., sub-goal) to advise a teammate. We introduce a new learning to teach framework, called hierarchical multiagent teaching (HMAT). The proposed framework solves difficulties faced by prior work on multiagent teaching when operating in domains with long horizons, delayed rewards, and continuous states/actions by leveraging temporal abstraction and deep function approximation. Our empirical evaluations show that HMAT accelerates team-wide learning progress in difficult environments that are more complex than those explored in previous work. HMAT also learns teaching policies that can be transferred to different teammates/tasks and can even teach teammates with heterogeneous action spaces.
Learning Abstract Options
Nov 06, 2018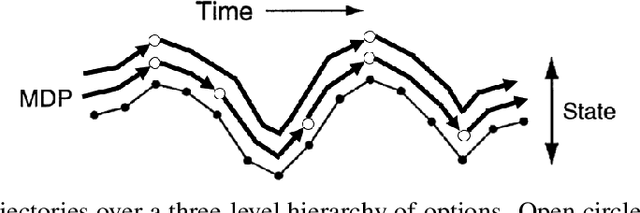

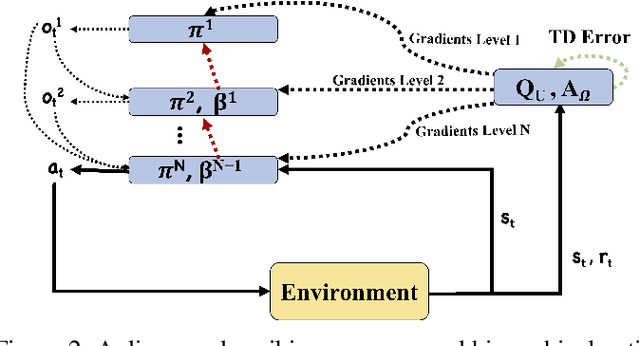
Building systems that autonomously create temporal abstractions from data is a key challenge in scaling learning and planning in reinforcement learning. One popular approach for addressing this challenge is the options framework (Sutton et al., 1999). However, only recently in (Bacon et al., 2017) was a policy gradient theorem derived for online learning of general purpose options in an end to end fashion. In this work, we extend previous work on this topic that only focuses on learning a two-level hierarchy including options and primitive actions to enable learning simultaneously at multiple resolutions in time. We achieve this by considering an arbitrarily deep hierarchy of options where high level temporally extended options are composed of lower level options with finer resolutions in time. We extend results from (Bacon et al., 2017) and derive policy gradient theorems for a deep hierarchy of options. Our proposed hierarchical option-critic architecture is capable of learning internal policies, termination conditions, and hierarchical compositions over options without the need for any intrinsic rewards or subgoals. Our empirical results in both discrete and continuous environments demonstrate the efficiency of our framework.
Dialog-based Interactive Image Retrieval
Nov 01, 2018

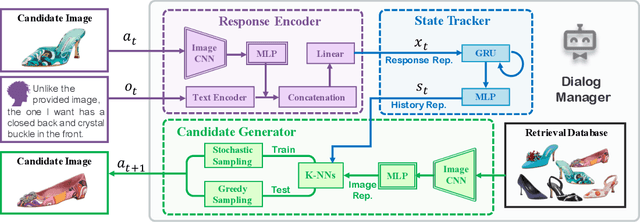
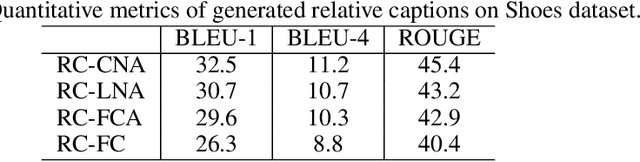
Existing methods for interactive image retrieval have demonstrated the merit of integrating user feedback, improving retrieval results. However, most current systems rely on restricted forms of user feedback, such as binary relevance responses, or feedback based on a fixed set of relative attributes, which limits their impact. In this paper, we introduce a new approach to interactive image search that enables users to provide feedback via natural language, allowing for more natural and effective interaction. We formulate the task of dialog-based interactive image retrieval as a reinforcement learning problem, and reward the dialog system for improving the rank of the target image during each dialog turn. To mitigate the cumbersome and costly process of collecting human-machine conversations as the dialog system learns, we train our system with a user simulator, which is itself trained to describe the differences between target and candidate images. The efficacy of our approach is demonstrated in a footwear retrieval application. Experiments on both simulated and real-world data show that 1) our proposed learning framework achieves better accuracy than other supervised and reinforcement learning baselines and 2) user feedback based on natural language rather than pre-specified attributes leads to more effective retrieval results, and a more natural and expressive communication interface.
Learning to Learn without Forgetting By Maximizing Transfer and Minimizing Interference
Oct 29, 2018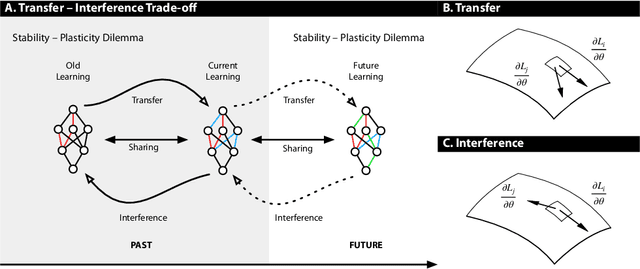
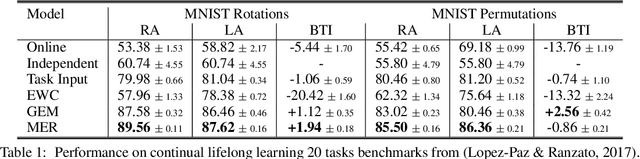
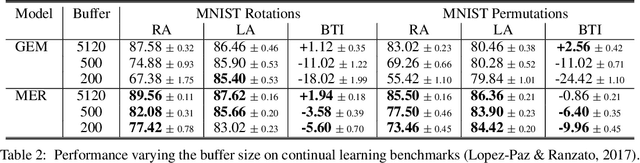
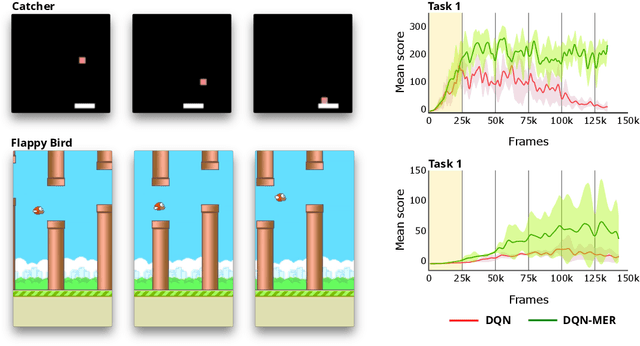
Lack of performance when it comes to continual learning over non-stationary distributions of data remains a major challenge in scaling neural network learning to more human realistic settings. In this work we propose a new conceptualization of the continual learning problem in terms of a trade-off between transfer and interference. We then propose a new algorithm, Meta-Experience Replay (MER), that directly exploits this view by combining experience replay with optimization based meta-learning. This method learns parameters that make interference based on future gradients less likely and transfer based on future gradients more likely. We conduct experiments across continual lifelong supervised learning benchmarks and non-stationary reinforcement learning environments demonstrating that our approach consistently outperforms recently proposed baselines for continual learning. Our experiments show that the gap between the performance of MER and baseline algorithms grows both as the environment gets more non-stationary and as the fraction of the total experiences stored gets smaller.
Learning to Teach in Cooperative Multiagent Reinforcement Learning
Aug 31, 2018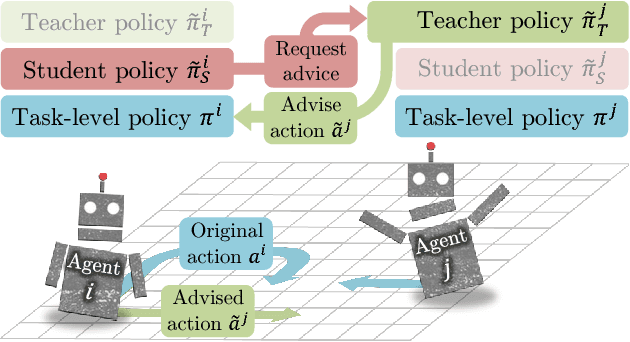

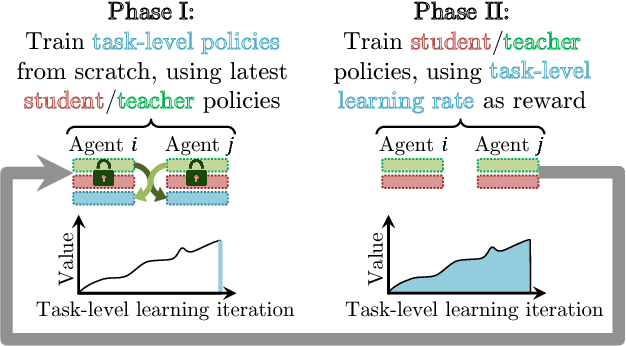
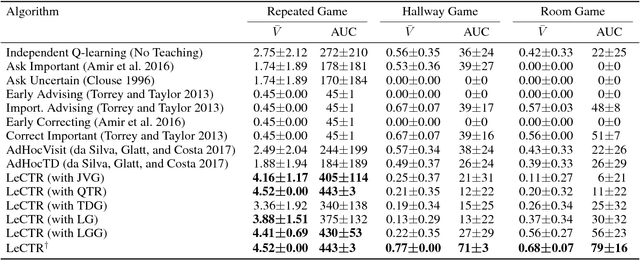
Collective human knowledge has clearly benefited from the fact that innovations by individuals are taught to others through communication. Similar to human social groups, agents in distributed learning systems would likely benefit from communication to share knowledge and teach skills. The problem of teaching to improve agent learning has been investigated by prior works, but these approaches make assumptions that prevent application of teaching to general multiagent problems, or require domain expertise for problems they can apply to. This learning to teach problem has inherent complexities related to measuring long-term impacts of teaching that compound the standard multiagent coordination challenges. In contrast to existing works, this paper presents the first general framework and algorithm for intelligent agents to learn to teach in a multiagent environment. Our algorithm, Learning to Coordinate and Teach Reinforcement (LeCTR), addresses peer-to-peer teaching in cooperative multiagent reinforcement learning. Each agent in our approach learns both when and what to advise, then uses the received advice to improve local learning. Importantly, these roles are not fixed; these agents learn to assume the role of student and/or teacher at the appropriate moments, requesting and providing advice in order to improve teamwide performance and learning. Empirical comparisons against state-of-the-art teaching methods show that our teaching agents not only learn significantly faster, but also learn to coordinate in tasks where existing methods fail.
Diverse Few-Shot Text Classification with Multiple Metrics
May 19, 2018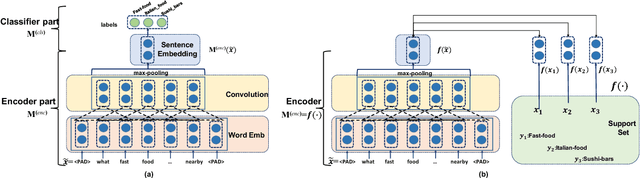
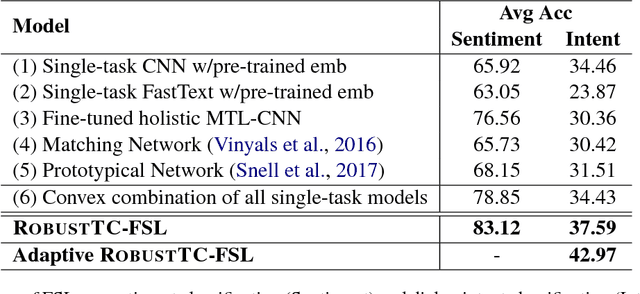
We study few-shot learning in natural language domains. Compared to many existing works that apply either metric-based or optimization-based meta-learning to image domain with low inter-task variance, we consider a more realistic setting, where tasks are diverse. However, it imposes tremendous difficulties to existing state-of-the-art metric-based algorithms since a single metric is insufficient to capture complex task variations in natural language domain. To alleviate the problem, we propose an adaptive metric learning approach that automatically determines the best weighted combination from a set of metrics obtained from meta-training tasks for a newly seen few-shot task. Extensive quantitative evaluations on real-world sentiment analysis and dialog intent classification datasets demonstrate that the proposed method performs favorably against state-of-the-art few shot learning algorithms in terms of predictive accuracy. We make our code and data available for further study.
Robust Task Clustering for Deep Many-Task Learning
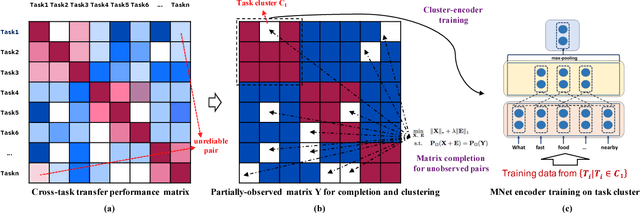
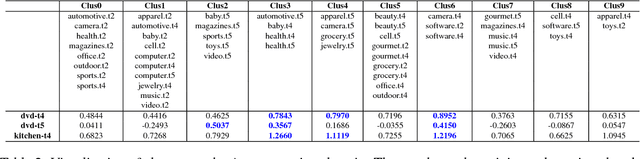
May 18, 2018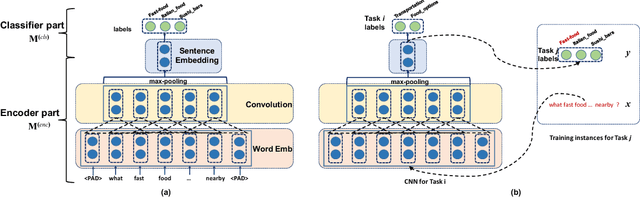
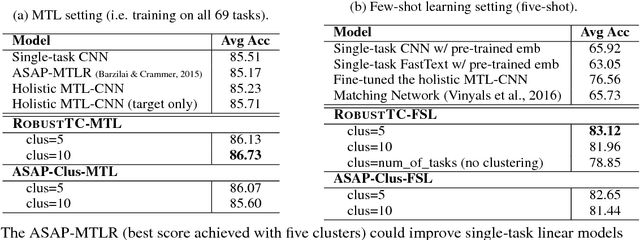
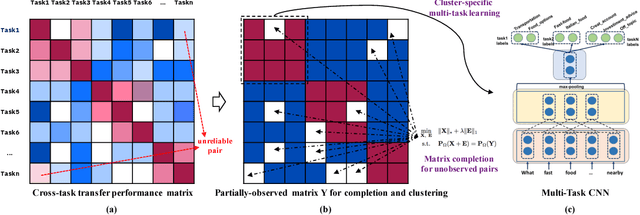
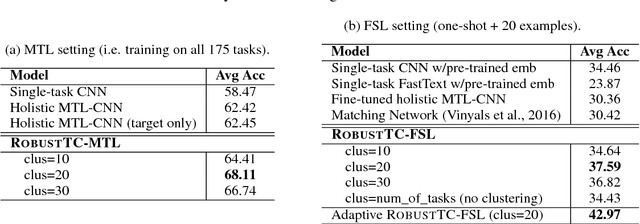
We investigate task clustering for deep-learning based multi-task and few-shot learning in a many-task setting. We propose a new method to measure task similarities with cross-task transfer performance matrix for the deep learning scenario. Although this matrix provides us critical information regarding similarity between tasks, its asymmetric property and unreliable performance scores can affect conventional clustering methods adversely. Additionally, the uncertain task-pairs, i.e., the ones with extremely asymmetric transfer scores, may collectively mislead clustering algorithms to output an inaccurate task-partition. To overcome these limitations, we propose a novel task-clustering algorithm by using the matrix completion technique. The proposed algorithm constructs a partially-observed similarity matrix based on the certainty of cluster membership of the task-pairs. We then use a matrix completion algorithm to complete the similarity matrix. Our theoretical analysis shows that under mild constraints, the proposed algorithm will perfectly recover the underlying "true" similarity matrix with a high probability. Our results show that the new task clustering method can discover task clusters for training flexible and superior neural network models in a multi-task learning setup for sentiment classification and dialog intent classification tasks. Our task clustering approach also extends metric-based few-shot learning methods to adapt multiple metrics, which demonstrates empirical advantages when the tasks are diverse.