 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness with Semi-Infinite Constrained Learning
Oct 29, 2021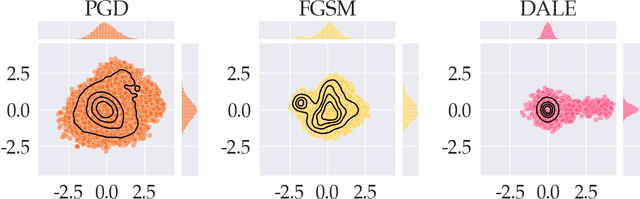
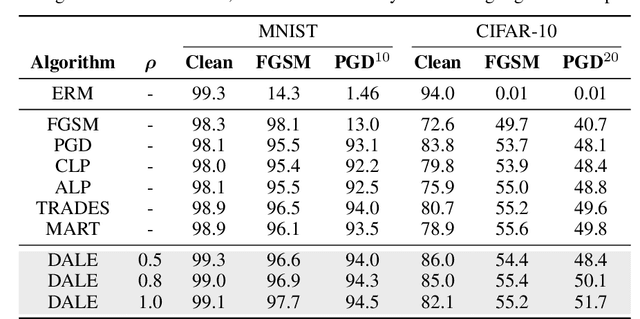
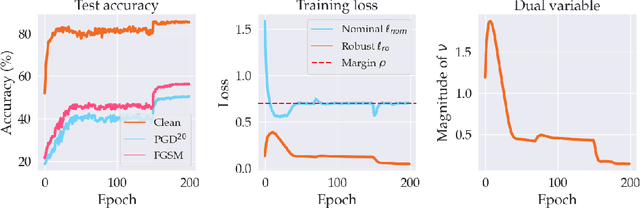
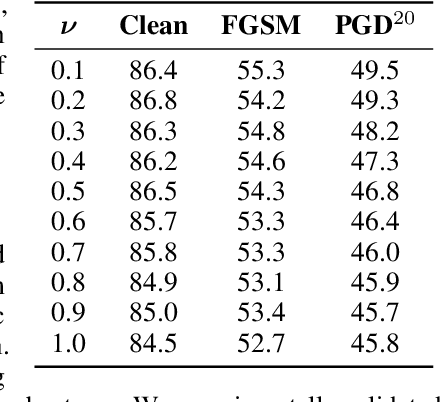
Despite strong performance in numerous applications, the fragility of deep learning to input perturbations has raised serious questions about its use in safety-critical domains. While adversarial training can mitigate this issue in practice, state-of-the-art methods are increasingly application-dependent, heuristic in nature, and suffer from fundamental trade-offs between nominal performance and robustness. Moreover, the problem of finding worst-case perturbations is non-convex and underparameterized, both of which engender a non-favorable optimization landscape. Thus, there is a gap between the theory and practice of adversarial training, particularly with respect to when and why adversarial training works. In this paper, we take a constrained learning approach to address these questions and to provide a theoretical foundation for robust learning. In particular, we leverage semi-infinite optimization and non-convex duality theory to show that adversarial training is equivalent to a statistical problem over perturbation distributions, which we characterize completely. Notably, we show that a myriad of previous robust training techniques can be recovered for particular, sub-optimal choices of these distributions. Using these insights, we then propose a hybrid Langevin Monte Carlo approach of which several common algorithms (e.g., PGD) are special cases. Finally, we show that our approach can mitigate the trade-off between nominal and robust performance, yielding state-of-the-art results on MNIST and CIFAR-10. Our code is available at: https://github.com/arobey1/advbench.
Robust Motion Planning in the Presence of Estimation Uncertainty
Aug 26, 2021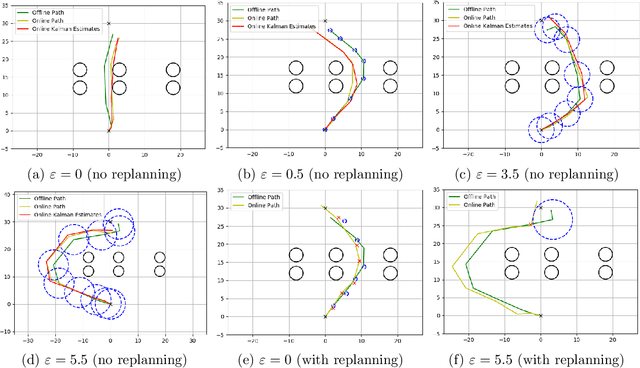
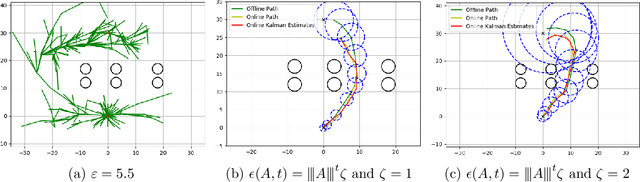
Motion planning is a fundamental problem and focuses on finding control inputs that enable a robot to reach a goal region while safely avoiding obstacles. However, in many situations, the state of the system may not be known but only estimated using, for instance, a Kalman filter. This results in a novel motion planning problem where safety must be ensured in the presence of state estimation uncertainty. Previous approaches to this problem are either conservative or integrate state estimates optimistically which leads to non-robust solutions. Optimistic solutions require frequent replanning to not endanger the safety of the system. We propose a new formulation to this problem with the aim to be robust to state estimation errors while not being overly conservative. In particular, we formulate a stochastic optimal control problem that contains robustified risk-aware safety constraints by incorporating robustness margins to account for state estimation errors. We propose a novel sampling-based approach that builds trees exploring the reachable space of Gaussian distributions that capture uncertainty both in state estimation and in future measurements. We provide robustness guarantees and show, both in theory and simulations, that the induced robustness margins constitute a trade-off between conservatism and robustness for planning under estimation uncertainty that allows to control the frequency of replanning.
Technical Report: Distributed Sampling-based Planning for Non-Myopic Active Information Gathering
Jul 23, 2021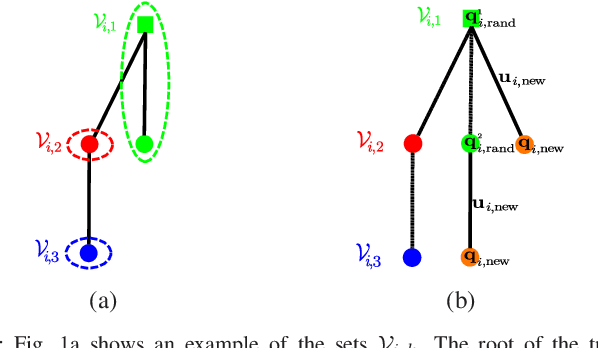
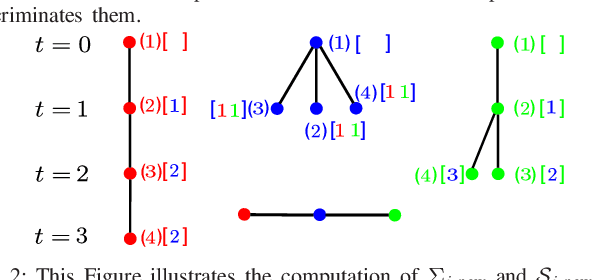
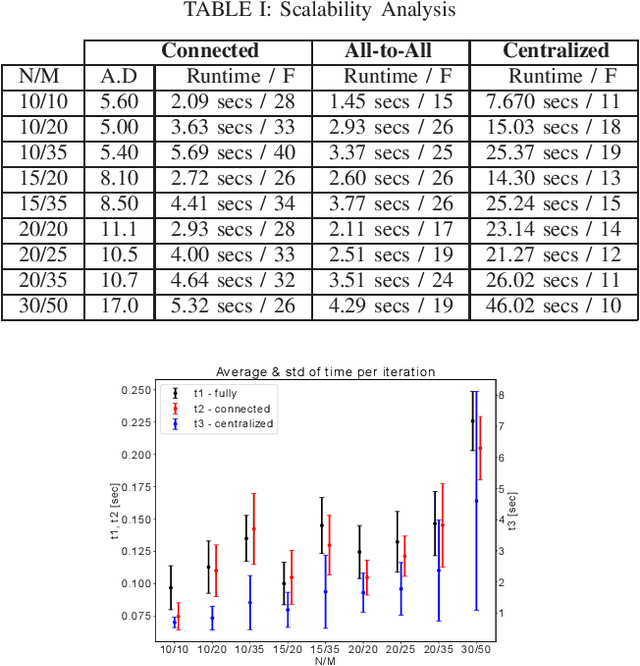
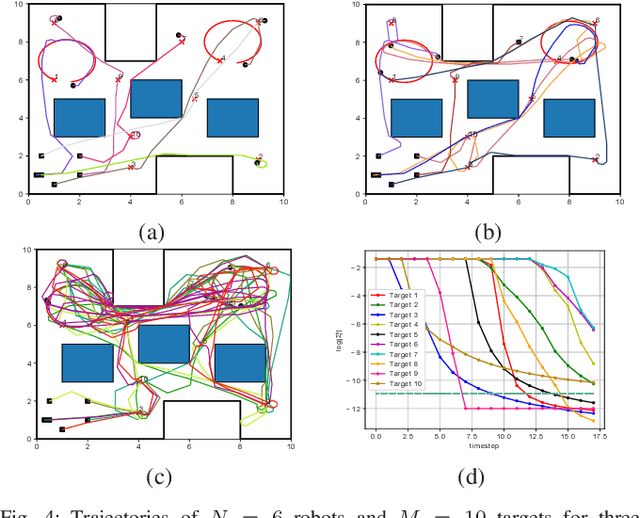
This paper addresses the problem of active information gathering for multi-robot systems. Specifically, we consider scenarios where robots are tasked with reducing uncertainty of dynamical hidden states evolving in complex environments. The majority of existing information gathering approaches are centralized and, therefore, they cannot be applied to distributed robot teams where communication to a central user is not available. To address this challenge, we propose a novel distributed sampling-based planning algorithm that can significantly increase robot and target scalability while decreasing computational cost. In our non-myopic approach, all robots build in parallel local trees exploring the information space and their corresponding motion space. As the robots construct their respective local trees, they communicate with their neighbors to exchange and aggregate their local beliefs about the hidden state through a distributed Kalman filter. We show that the proposed algorithm is probabilistically complete and asymptotically optimal. We provide extensive simulation results that demonstrate the scalability of the proposed algorithm and that it can address large-scale, multi-robot information gathering tasks, that are computationally challenging for centralized methods.
Safe Pontryagin Differentiable Programming
May 31, 2021
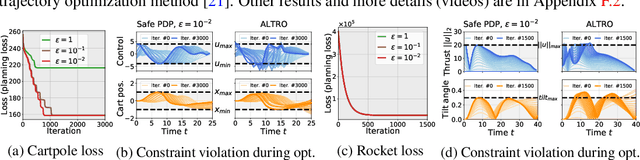
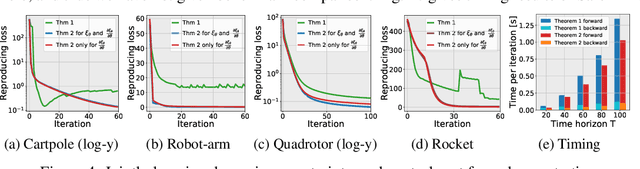
We propose a Safe Pontryagin Differentiable Programming (Safe PDP) methodology, which establishes a theoretical and algorithmic safe differentiable framework to solve a broad class of safety-critical learning and control tasks -- problems that require the guarantee of both immediate and long-term constraint satisfaction at any stage of the learning and control progress. In the spirit of interior-point methods, Safe PDP handles different types of state and input constraints by incorporating them into the cost and loss through barrier functions. We prove the following fundamental features of Safe PDP: first, both the constrained solution and its gradient in backward pass can be approximated by solving a more efficient unconstrained counterpart; second, the approximation for both the solution and its gradient can be controlled for arbitrary accuracy using a barrier parameter; and third, importantly, any intermediate results throughout the approximation and optimization are strictly respecting all constraints, thus guaranteeing safety throughout the entire learning and control process. We demonstrate the capabilities of Safe PDP in solving various safe learning and control tasks, including safe policy optimization, safe motion planning, and learning MPCs from demonstrations, on different challenging control systems such as 6-DoF maneuvering quadrotor and 6-DoF rocket powered landing.
STL Robustness Risk over Discrete-Time Stochastic Processes
Apr 22, 2021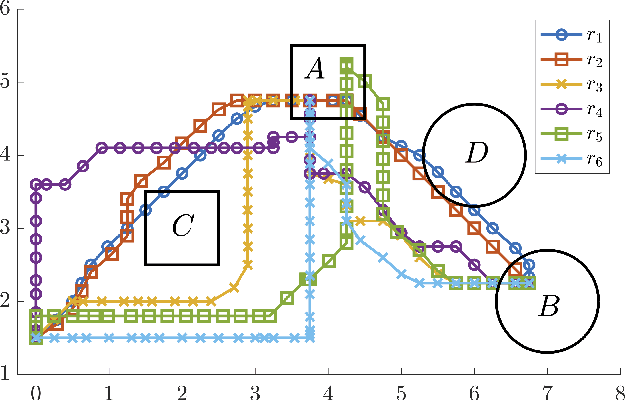


We present a framework to interpret signal temporal logic (STL) formulas over discrete-time stochastic processes in terms of the induced risk. Each realization of a stochastic process either satisfies or violates an STL formula. In fact, we can assign a robustness value to each realization that indicates how robustly this realization satisfies an STL formula. We then define the risk of a stochastic process not satisfying an STL formula robustly, referred to as the "STL robustness risk". In our definition, we permit general classes of risk measures such as, but not limited to, the value-at-risk. While in general hard to compute, we propose an approximation of the STL robustness risk. This approximation has the desirable property of being an upper bound of the STL robustness risk when the chosen risk measure is monotone, a property satisfied by most risk measures. Motivated by the interest in data-driven approaches, we present a sampling-based method for calculating an upper bound of the approximate STL robustness risk for the value-at-risk that holds with high probability. While we consider the case of the value-at-risk, we highlight that such sampling-based methods are viable for other risk measures.
Linear Systems can be Hard to Learn
Apr 02, 2021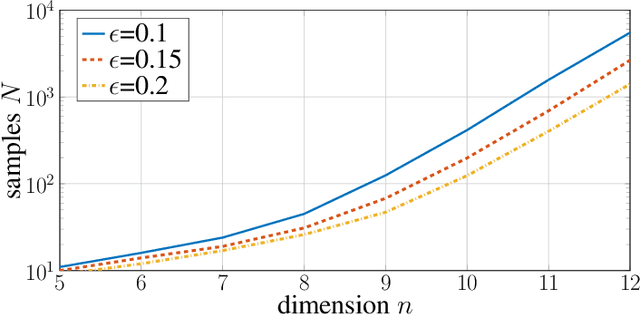
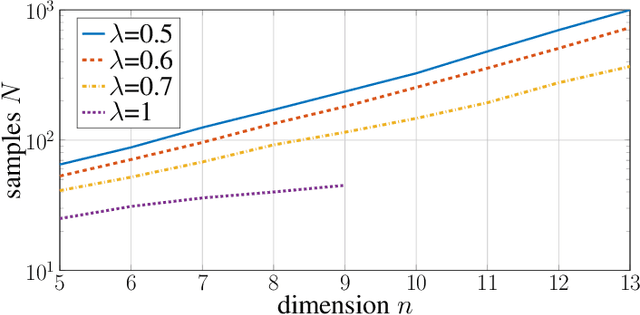
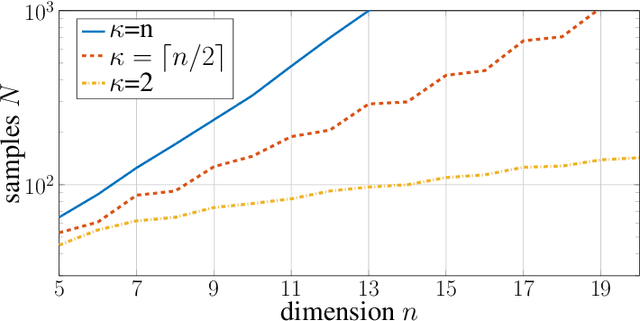
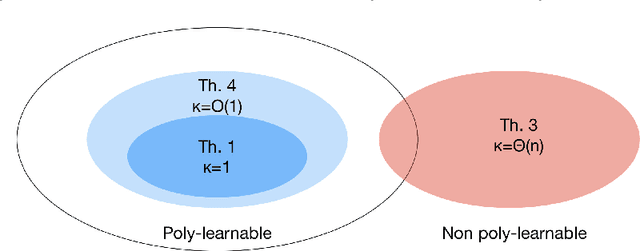
In this paper, we investigate when system identification is statistically easy or hard, in the finite sample regime. Statistically easy to learn linear system classes have sample complexity that is polynomial with the system dimension. Most prior research in the finite sample regime falls in this category, focusing on systems that are directly excited by process noise. Statistically hard to learn linear system classes have worst-case sample complexity that is at least exponential with the system dimension, regardless of the identification algorithm. Using tools from minimax theory, we show that classes of linear systems can be hard to learn. Such classes include, for example, under-actuated or under-excited systems with weak coupling among the states. Having classified some systems as easy or hard to learn, a natural question arises as to what system properties fundamentally affect the hardness of system identifiability. Towards this direction, we characterize how the controllability index of linear systems affects the sample complexity of identification. More specifically, we show that the sample complexity of robustly controllable linear systems is upper bounded by an exponential function of the controllability index. This implies that identification is easy for classes of linear systems with small controllability index and potentially hard if the controllability index is large. Our analysis is based on recent statistical tools for finite sample analysis of system identification as well as a novel lower bound that relates controllability index with the least singular value of the controllability Gramian.
Resilient Active Information Acquisition with Teams of Robots
Mar 17, 2021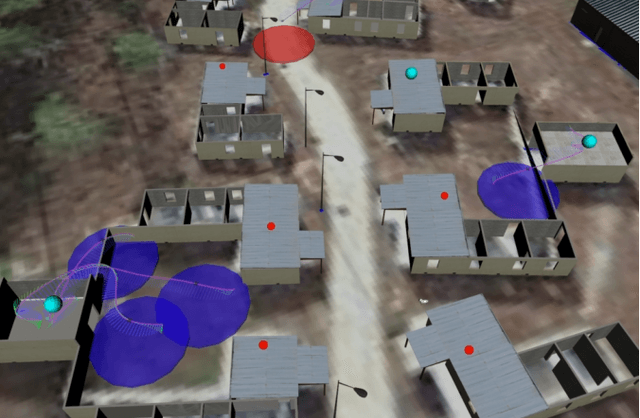
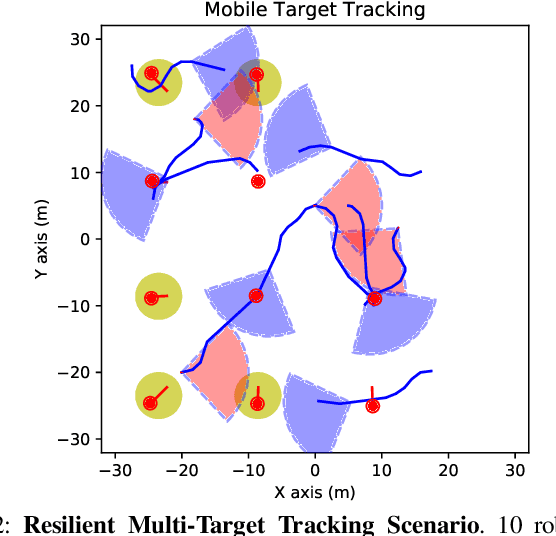
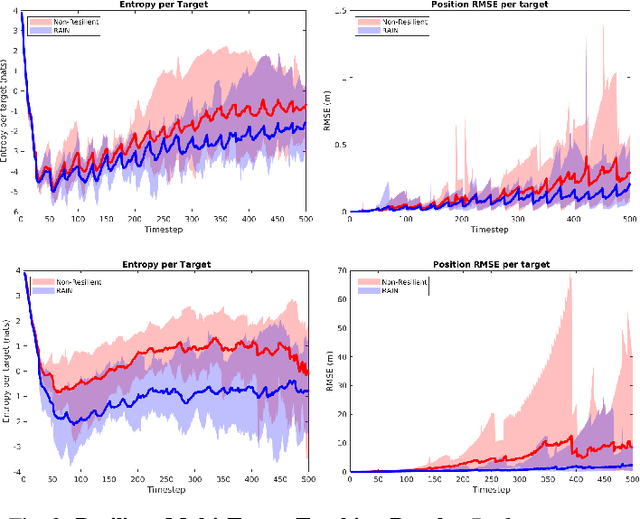
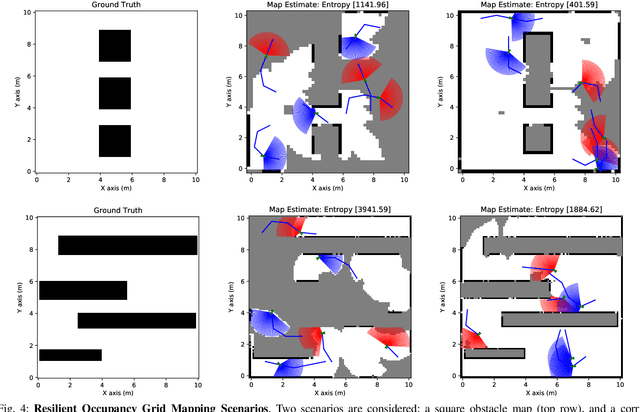
Emerging applications of collaborative autonomy, such as Multi-Target Tracking, Unknown Map Exploration, and Persistent Surveillance, require robots plan paths to navigate an environment while maximizing the information collected via on-board sensors. In this paper, we consider such information acquisition tasks but in adversarial environments, where attacks may temporarily disable the robots' sensors. We propose the first receding horizon algorithm, aiming for robust and adaptive multi-robot planning against any number of attacks, which we call Resilient Active Information acquisitioN (RAIN). RAIN calls, in an online fashion, a Robust Trajectory Planning (RTP) subroutine which plans attack-robust control inputs over a look-ahead planning horizon. We quantify RTP's performance by bounding its suboptimality. We base our theoretical analysis on notions of curvature introduced in combinatorial optimization. We evaluate RAIN in three information acquisition scenarios: Multi-Target Tracking, Occupancy Grid Mapping, and Persistent Surveillance. The scenarios are simulated in C++ and a Unity-based simulator. In all simulations, RAIN runs in real-time, and exhibits superior performance against a state-of-the-art baseline information acquisition algorithm, even in the presence of a high number of attacks. We also demonstrate RAIN's robustness and effectiveness against varying models of attacks (worst-case and random), as well as, varying replanning rates.
Technical Report: Scalable Active Information Acquisition for Multi-Robot Systems
Mar 16, 2021
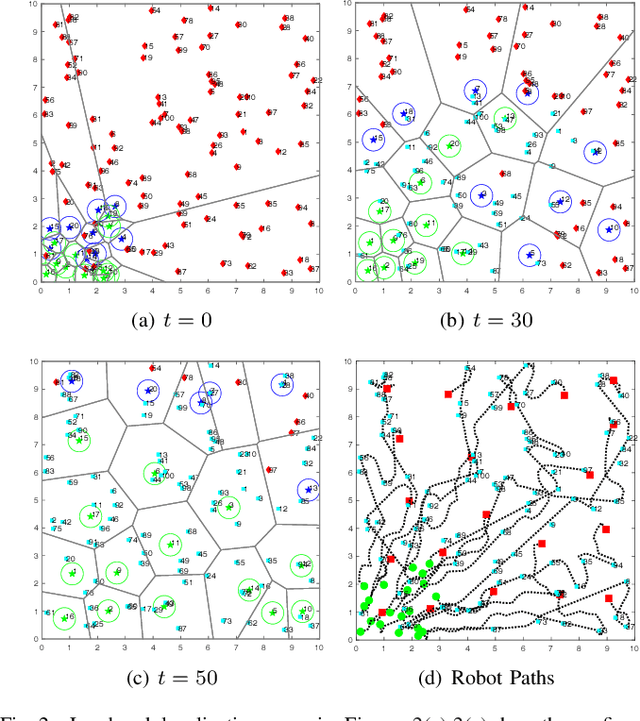
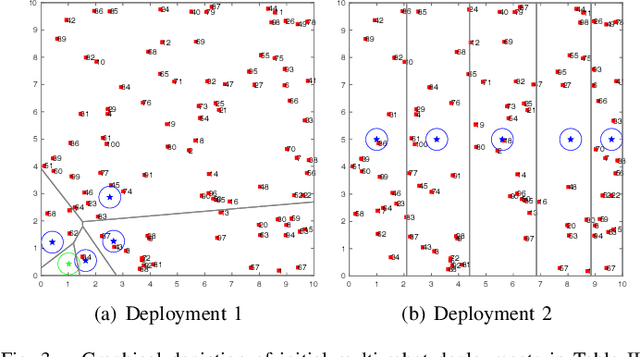

This paper proposes a novel highly scalable non-myopic planning algorithm for multi-robot Active Information Acquisition (AIA) tasks. AIA scenarios include target localization and tracking, active SLAM, surveillance, environmental monitoring and others. The objective is to compute control policies for multiple robots which minimize the accumulated uncertainty of a static hidden state over an a priori unknown horizon. The majority of existing AIA approaches are centralized and, therefore, face scaling challenges. To mitigate this issue, we propose an online algorithm that relies on decomposing the AIA task into local tasks via a dynamic space-partitioning method. The local subtasks are formulated online and require the robots to switch between exploration and active information gathering roles depending on their functionality in the environment. The switching process is tightly integrated with optimizing information gathering giving rise to a hybrid control approach. We show that the proposed decomposition-based algorithm is probabilistically complete for homogeneous sensor teams and under linearity and Gaussian assumptions. We provide extensive simulation results that show that the proposed algorithm can address large-scale estimation tasks that are computationally challenging to solve using existing centralized approaches.
Model-Based Domain Generalization
Feb 23, 2021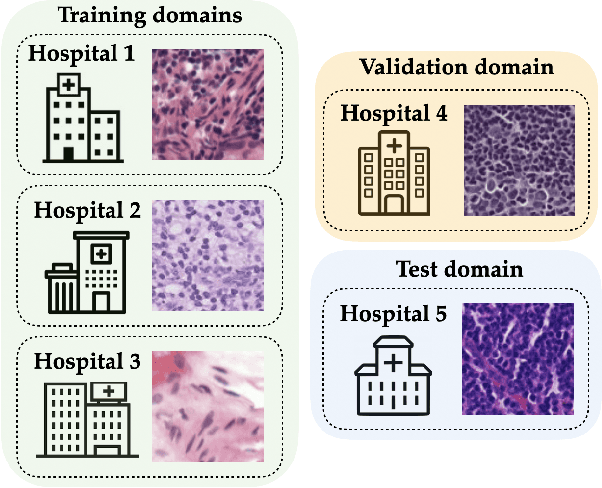

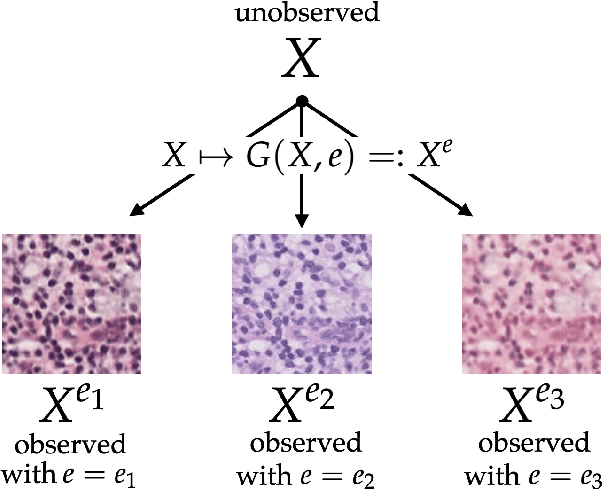

We consider the problem of domain generalization, in which a predictor is trained on data drawn from a family of related training domains and tested on a distinct and unseen test domain. While a variety of approaches have been proposed for this setting, it was recently shown that no existing algorithm can consistently outperform empirical risk minimization (ERM) over the training domains. To this end, in this paper we propose a novel approach for the domain generalization problem called Model-Based Domain Generalization. In our approach, we first use unlabeled data from the training domains to learn multi-modal domain transformation models that map data from one training domain to any other domain. Next, we propose a constrained optimization-based formulation for domain generalization which enforces that a trained predictor be invariant to distributional shifts under the underlying domain transformation model. Finally, we propose a novel algorithmic framework for efficiently solving this constrained optimization problem. In our experiments, we show that this approach outperforms both ERM and domain generalization algorithms on numerous well-known, challenging datasets, including WILDS, PACS, and ImageNet. In particular, our algorithms beat the current state-of-the-art methods on the very-recently-proposed WILDS benchmark by up to 20 percentage points.
Achieving Linear Convergence in Federated Learning under Objective and Systems Heterogeneity
Feb 14, 2021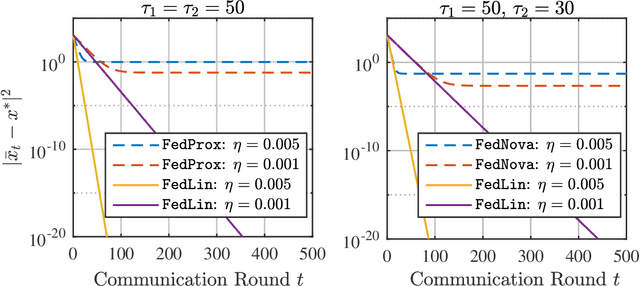
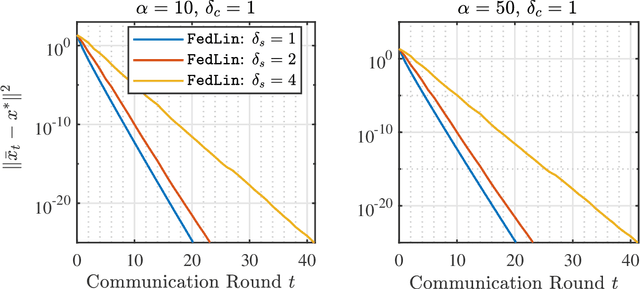
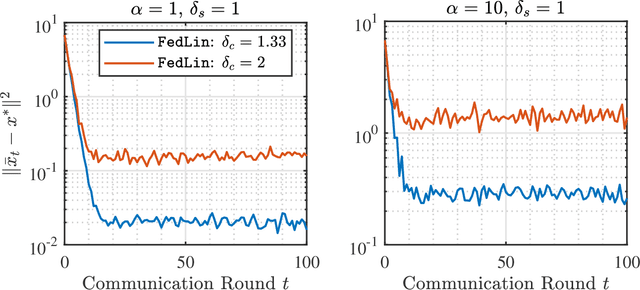
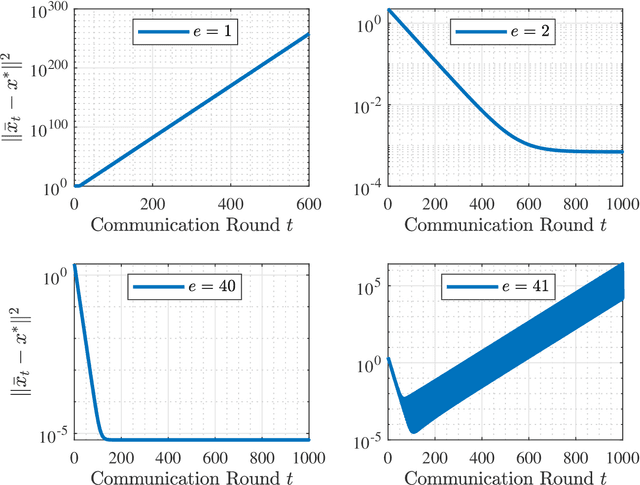
We consider a standard federated learning architecture where a group of clients periodically coordinate with a central server to train a statistical model. We tackle two major challenges in federated learning: (i) objective heterogeneity, which stems from differences in the clients' local loss functions, and (ii) systems heterogeneity, which leads to slow and straggling client devices. Due to such client heterogeneity, we show that existing federated learning algorithms suffer from a fundamental speed-accuracy conflict: they either guarantee linear convergence but to an incorrect point, or convergence to the global minimum but at a sub-linear rate, i.e., fast convergence comes at the expense of accuracy. To address the above limitation, we propose FedLin - a simple, new algorithm that exploits past gradients and employs client-specific learning rates. When the clients' local loss functions are smooth and strongly convex, we show that FedLin guarantees linear convergence to the global minimum. We then establish matching upper and lower bounds on the convergence rate of FedLin that highlight the trade-offs associated with infrequent, periodic communication. Notably, FedLin is the only approach that is able to match centralized convergence rates (up to constants) for smooth strongly convex, convex, and non-convex loss functions despite arbitrary objective and systems heterogeneity. We further show that FedLin preserves linear convergence rates under aggressive gradient sparsification, and quantify the effect of the compression level on the convergence rate.