 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Scout: Multi-Target Tracking Using Neural Radiance Fields in Dense Urban Environments
Jun 11, 2024



We study pursuit-evasion games in highly occluded urban environments, e.g. tall buildings in a city, where a scout (quadrotor) tracks multiple dynamic targets on the ground. We show that we can build a neural radiance field (NeRF) representation of the city -- online -- using RGB and depth images from different vantage points. This representation is used to calculate the information gain to both explore unknown parts of the city and track the targets -- thereby giving a completely first-principles approach to actively tracking dynamic targets. We demonstrate, using a custom-built simulator using Open Street Maps data of Philadelphia and New York City, that we can explore and locate 20 stationary targets within 300 steps. This is slower than a greedy baseline which which does not use active perception. But for dynamic targets that actively hide behind occlusions, we show that our approach maintains, at worst, a tracking error of 200m; the greedy baseline can have a tracking error as large as 600m. We observe a number of interesting properties in the scout's policies, e.g., it switches its attention to track a different target periodically, as the quality of the NeRF representation improves over time, the scout also becomes better in terms of target tracking.
Active Perception using Neural Radiance Fields
Oct 15, 2023



We study active perception from first principles to argue that an autonomous agent performing active perception should maximize the mutual information that past observations posses about future ones. Doing so requires (a) a representation of the scene that summarizes past observations and the ability to update this representation to incorporate new observations (state estimation and mapping), (b) the ability to synthesize new observations of the scene (a generative model), and (c) the ability to select control trajectories that maximize predictive information (planning). This motivates a neural radiance field (NeRF)-like representation which captures photometric, geometric and semantic properties of the scene grounded. This representation is well-suited to synthesizing new observations from different viewpoints. And thereby, a sampling-based planner can be used to calculate the predictive information from synthetic observations along dynamically-feasible trajectories. We use active perception for exploring cluttered indoor environments and employ a notion of semantic uncertainty to check for the successful completion of an exploration task. We demonstrate these ideas via simulation in realistic 3D indoor environments.
Strategic Maneuver and Disruption with Reinforcement Learning Approaches for Multi-Agent Coordination
Mar 17, 2022
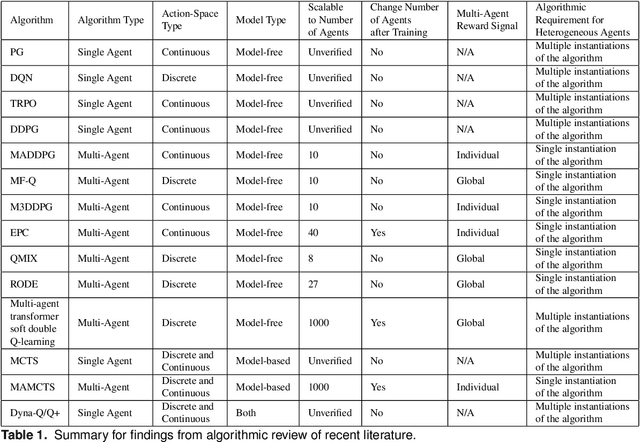
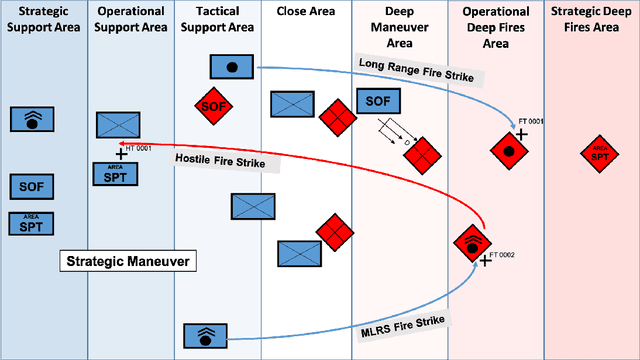
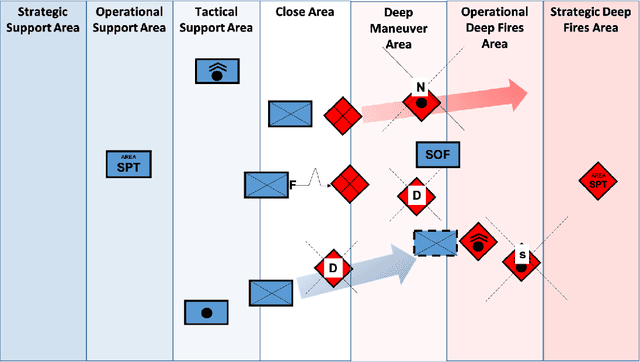
Reinforcement learning (RL) approaches can illuminate emergent behaviors that facilitate coordination across teams of agents as part of a multi-agent system (MAS), which can provide windows of opportunity in various military tasks. Technologically advancing adversaries pose substantial risks to a friendly nation's interests and resources. Superior resources alone are not enough to defeat adversaries in modern complex environments because adversaries create standoff in multiple domains against predictable military doctrine-based maneuvers. Therefore, as part of a defense strategy, friendly forces must use strategic maneuvers and disruption to gain superiority in complex multi-faceted domains such as multi-domain operations (MDO). One promising avenue for implementing strategic maneuver and disruption to gain superiority over adversaries is through coordination of MAS in future military operations. In this paper, we present overviews of prominent works in the RL domain with their strengths and weaknesses for overcoming the challenges associated with performing autonomous strategic maneuver and disruption in military contexts.
Scalable Reinforcement Learning Policies for Multi-Agent Control
Nov 16, 2020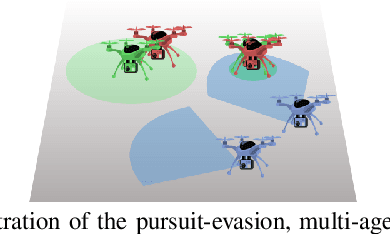
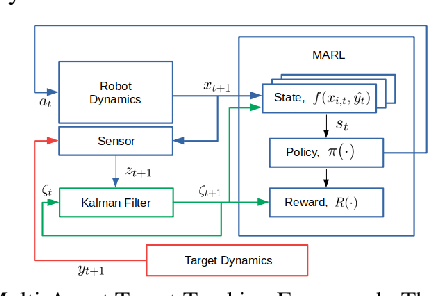
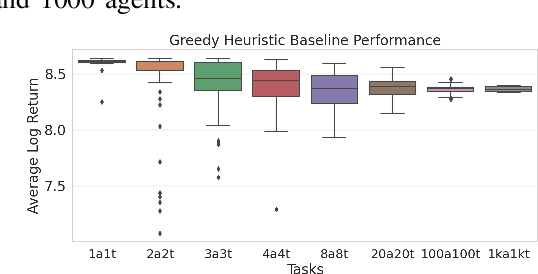
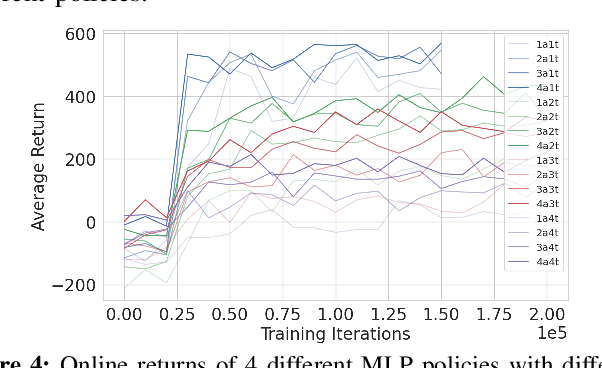
This paper develops a stochastic Multi-Agent Reinforcement Learning (MARL) method to learn control policies that can handle an arbitrary number of external agents; our policies can be executed for tasks consisting of 1000 pursuers and 1000 evaders. We model pursuers as agents with limited on-board sensing and formulate the problem as a decentralized, partially-observable Markov Decision Process. An attention mechanism is used to build a permutation and input-size invariant embedding of the observations for learning a stochastic policy and value function using techniques in entropy-regularized off-policy methods. Simulation experiments on a large number of problems show that our control policies are dramatically scalable and display cooperative behavior in spite of being executed in a decentralized fashion; our methods offer a simple solution to classical multi-agent problems using techniques in reinforcement learning.