 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Catastrophic Forgetting in Massively Multilingual Continual Learning
May 25, 2023



Real-life multilingual systems should be able to efficiently incorporate new languages as data distributions fed to the system evolve and shift over time. To do this, systems need to handle the issue of catastrophic forgetting, where the model performance drops for languages or tasks seen further in its past. In this paper, we study catastrophic forgetting, as well as methods to minimize this, in a massively multilingual continual learning framework involving up to 51 languages and covering both classification and sequence labeling tasks. We present LR ADJUST, a learning rate scheduling method that is simple, yet effective in preserving new information without strongly overwriting past knowledge. Furthermore, we show that this method is effective across multiple continual learning approaches. Finally, we provide further insights into the dynamics of catastrophic forgetting in this massively multilingual setup.
Multi-lingual and Multi-cultural Figurative Language Understanding
May 25, 2023Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. In this work, we create a figurative language inference dataset, \datasetname, for seven diverse languages associated with a variety of cultures: Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili and Yoruba. Our dataset reveals that each language relies on cultural and regional concepts for figurative expressions, with the highest overlap between languages originating from the same region. We assess multilingual LMs' abilities to interpret figurative language in zero-shot and few-shot settings. All languages exhibit a significant deficiency compared to English, with variations in performance reflecting the availability of pre-training and fine-tuning data, emphasizing the need for LMs to be exposed to a broader range of linguistic and cultural variation during training.
GlobalBench: A Benchmark for Global Progress in Natural Language Processing
May 24, 2023



Despite the major advances in NLP, significant disparities in NLP system performance across languages still exist. Arguably, these are due to uneven resource allocation and sub-optimal incentives to work on less resourced languages. To track and further incentivize the global development of equitable language technology, we introduce GlobalBench. Prior multilingual benchmarks are static and have focused on a limited number of tasks and languages. In contrast, GlobalBench is an ever-expanding collection that aims to dynamically track progress on all NLP datasets in all languages. Rather than solely measuring accuracy, GlobalBench also tracks the estimated per-speaker utility and equity of technology across all languages, providing a multi-faceted view of how language technology is serving people of the world. Furthermore, GlobalBench is designed to identify the most under-served languages, and rewards research efforts directed towards those languages. At present, the most under-served languages are the ones with a relatively high population, but nonetheless overlooked by composite multilingual benchmarks (like Punjabi, Portuguese, and Wu Chinese). Currently, GlobalBench covers 966 datasets in 190 languages, and has 1,128 system submissions spanning 62 languages.
Prompting Multilingual Large Language Models to Generate Code-Mixed Texts: The Case of South East Asian Languages
Mar 30, 2023



While code-mixing is a common linguistic practice in many parts of the world, collecting high-quality and low-cost code-mixed data remains a challenge for natural language processing (NLP) research. The proliferation of Large Language Models (LLMs) in recent times compels one to ask: can these systems be used for data generation? In this article, we explore prompting multilingual LLMs in a zero-shot manner to create code-mixed data for five languages in South East Asia (SEA) -- Indonesian, Malay, Chinese, Tagalog, Vietnamese, as well as the creole language Singlish. We find that ChatGPT shows the most potential, capable of producing code-mixed text 68% of the time when the term "code-mixing" is explicitly defined. Moreover, both ChatGPT's and InstructGPT's (davinci-003) performances in generating Singlish texts are noteworthy, averaging a 96% success rate across a variety of prompts. Their code-mixing proficiency, however, is dampened by word choice errors that lead to semantic inaccuracies. Other multilingual models such as BLOOMZ and Flan-T5-XXL are unable to produce code-mixed texts altogether. By highlighting the limited promises of LLMs in a specific form of low-resource data generation, we call for a measured approach when applying similar techniques to other data-scarce NLP contexts.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
The Decades Progress on Code-Switching Research in NLP: A Systematic Survey on Trends and Challenges
Dec 19, 2022



Code-Switching, a common phenomenon in written text and conversation, has been studied over decades by the natural language processing (NLP) research community. Initially, code-switching is intensively explored by leveraging linguistic theories and, currently, more machine-learning oriented approaches to develop models. We introduce a comprehensive systematic survey on code-switching research in natural language processing to understand the progress of the past decades and conceptualize the challenges and tasks on the code-switching topic. Finally, we summarize the trends and findings and conclude with a discussion for future direction and open questions for further investigation.
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Dec 19, 2022



The BLOOM model is a large open-source multilingual language model capable of zero-shot learning, but its pretraining was limited to 46 languages. To improve its zero-shot performance on unseen languages, it is desirable to adapt BLOOM, but previous works have only explored adapting small language models. In this work, we apply existing language adaptation strategies to BLOOM and benchmark its zero-shot prompting performance on eight new languages. We find language adaptation to be effective at improving zero-shot performance in new languages. Surprisingly, adapter-based finetuning is more effective than continued pretraining for large models. In addition, we discover that prompting performance is not significantly affected by language specifics, such as the writing system. It is primarily determined by the size of the language adaptation data. We also add new languages to BLOOMZ, which is a multitask finetuned version of BLOOM capable of following task instructions zero-shot. We find including a new language in the multitask fine-tuning mixture to be the most effective method to teach BLOOMZ a new language. We conclude that with sufficient training data language adaptation can generalize well to diverse languages. Our code is available at \url{https://github.com/bigscience-workshop/multilingual-modeling/}.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Transfer Learning Application of Self-supervised Learning in ARPES
Aug 23, 2022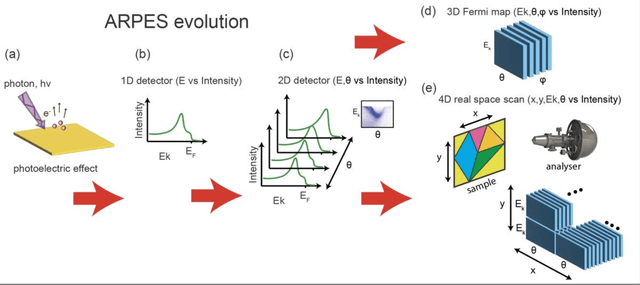
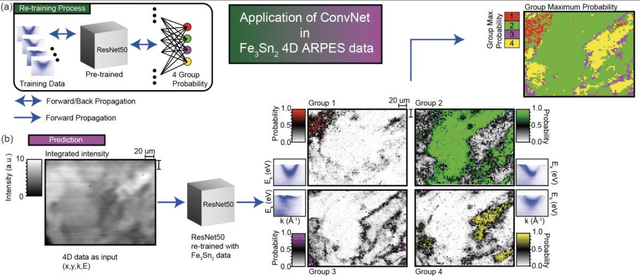
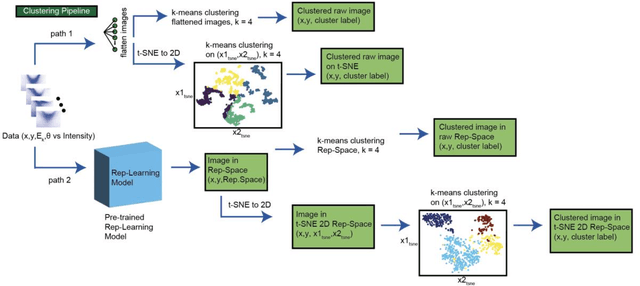
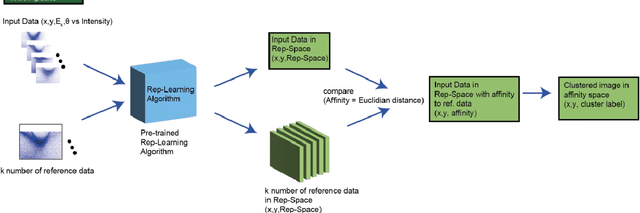
Recent development in angle-resolved photoemission spectroscopy (ARPES) technique involves spatially resolving samples while maintaining the high-resolution feature of momentum space. This development easily expands the data size and its complexity for data analysis, where one of it is to label similar dispersion cuts and map them spatially. In this work, we demonstrate that the recent development in representational learning (self-supervised learning) model combined with k-means clustering can help automate that part of data analysis and save precious time, albeit with low performance. Finally, we introduce a few-shot learning (k-nearest neighbour or kNN) in representational space where we selectively choose one (k=1) image reference for each known label and subsequently label the rest of the data with respect to the nearest reference image. This last approach demonstrates the strength of the self-supervised learning to automate the image analysis in ARPES in particular and can be generalized into any science data analysis that heavily involves image data.
NusaCrowd: A Call for Open and Reproducible NLP Research in Indonesian Languages
Aug 01, 2022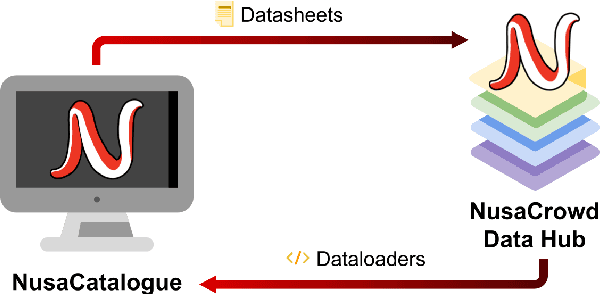
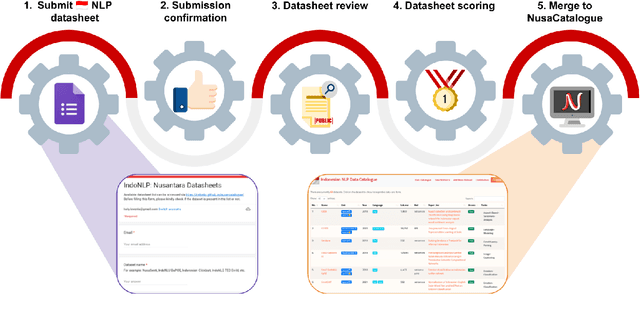
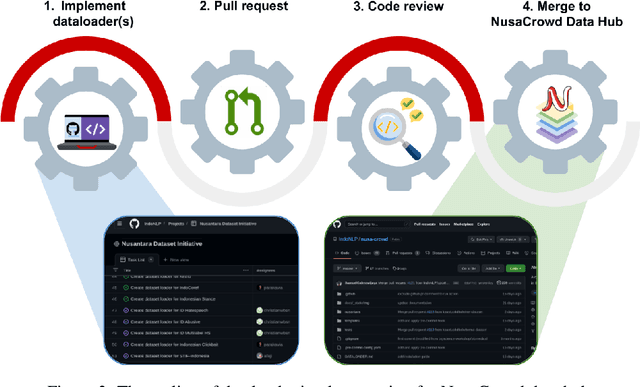
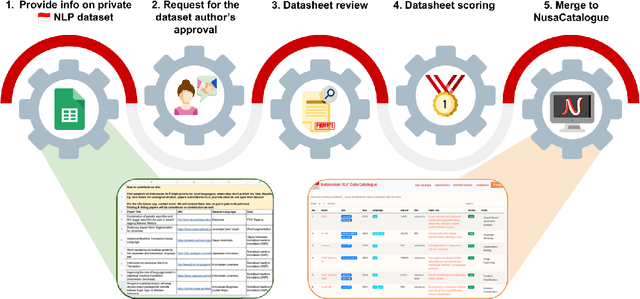
At the center of the underlying issues that halt Indonesian natural language processing (NLP) research advancement, we find data scarcity. Resources in Indonesian languages, especially the local ones, are extremely scarce and underrepresented. Many Indonesian researchers do not publish their dataset. Furthermore, the few public datasets that we have are scattered across different platforms, thus makes performing reproducible and data-centric research in Indonesian NLP even more arduous. Rising to this challenge, we initiate the first Indonesian NLP crowdsourcing effort, NusaCrowd. NusaCrowd strives to provide the largest datasheets aggregation with standardized data loading for NLP tasks in all Indonesian languages. By enabling open and centralized access to Indonesian NLP resources, we hope NusaCrowd can tackle the data scarcity problem hindering NLP progress in Indonesia and bring NLP practitioners to move towards collaboration.