 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Experience Replay for Continual Visual Control and Forecasting
Mar 12, 2023



Learning physical dynamics in a series of non-stationary environments is a challenging but essential task for model-based reinforcement learning (MBRL) with visual inputs. It requires the agent to consistently adapt to novel tasks without forgetting previous knowledge. In this paper, we present a new continual learning approach for visual dynamics modeling and explore its efficacy in visual control and forecasting. The key assumption is that an ideal world model can provide a non-forgetting environment simulator, which enables the agent to optimize the policy in a multi-task learning manner based on the imagined trajectories from the world model. To this end, we first propose the mixture world model that learns task-specific dynamics priors with a mixture of Gaussians, and then introduce a new training strategy to overcome catastrophic forgetting, which we call predictive experience replay. Finally, we extend these methods to continual RL and further address the value estimation problems with the exploratory-conservative behavior learning approach. Our model remarkably outperforms the naive combinations of existing continual learning and visual RL algorithms on DeepMind Control and Meta-World benchmarks with continual visual control tasks. It is also shown to effectively alleviate the forgetting of spatiotemporal dynamics in video prediction datasets with evolving domains.
Camouflaged Object Detection via Context-aware Cross-level Fusion
Jul 27, 2022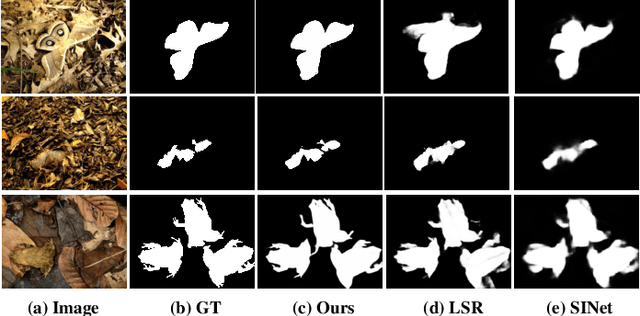
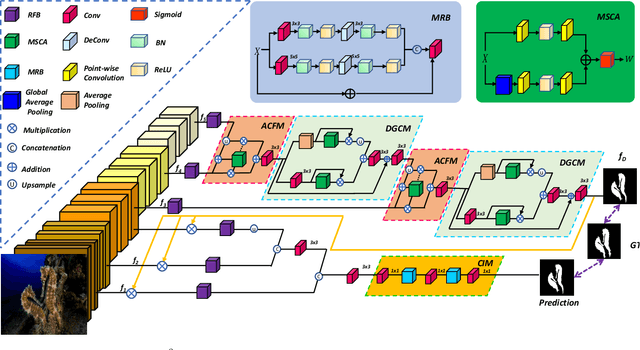

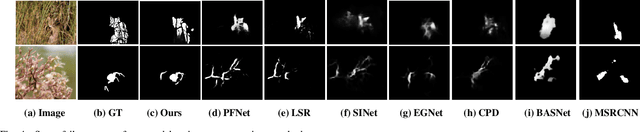
Camouflaged object detection (COD) aims to identify the objects that conceal themselves in natural scenes. Accurate COD suffers from a number of challenges associated with low boundary contrast and the large variation of object appearances, e.g., object size and shape. To address these challenges, we propose a novel Context-aware Cross-level Fusion Network (C2F-Net), which fuses context-aware cross-level features for accurately identifying camouflaged objects. Specifically, we compute informative attention coefficients from multi-level features with our Attention-induced Cross-level Fusion Module (ACFM), which further integrates the features under the guidance of attention coefficients. We then propose a Dual-branch Global Context Module (DGCM) to refine the fused features for informative feature representations by exploiting rich global context information. Multiple ACFMs and DGCMs are integrated in a cascaded manner for generating a coarse prediction from high-level features. The coarse prediction acts as an attention map to refine the low-level features before passing them to our Camouflage Inference Module (CIM) to generate the final prediction. We perform extensive experiments on three widely used benchmark datasets and compare C2F-Net with state-of-the-art (SOTA) models. The results show that C2F-Net is an effective COD model and outperforms SOTA models remarkably. Further, an evaluation on polyp segmentation datasets demonstrates the promising potentials of our C2F-Net in COD downstream applications. Our code is publicly available at: https://github.com/Ben57882/C2FNet-TSCVT.
Continual Predictive Learning from Videos
Apr 12, 2022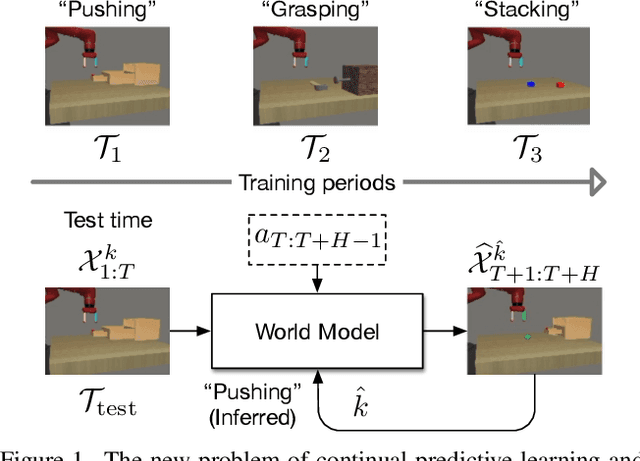
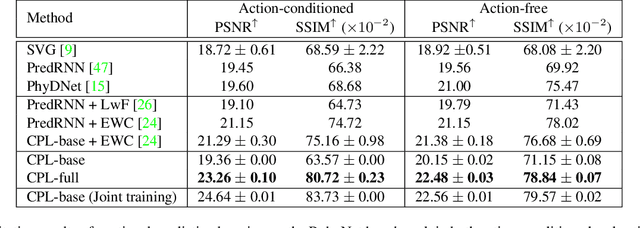
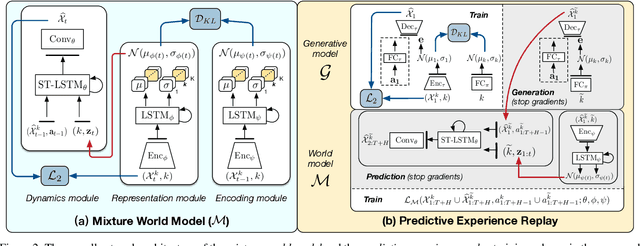
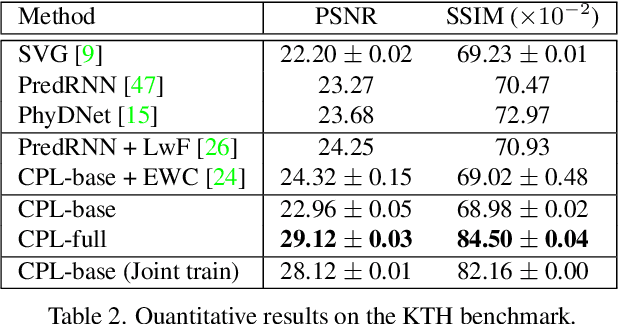
Predictive learning ideally builds the world model of physical processes in one or more given environments. Typical setups assume that we can collect data from all environments at all times. In practice, however, different prediction tasks may arrive sequentially so that the environments may change persistently throughout the training procedure. Can we develop predictive learning algorithms that can deal with more realistic, non-stationary physical environments? In this paper, we study a new continual learning problem in the context of video prediction, and observe that most existing methods suffer from severe catastrophic forgetting in this setup. To tackle this problem, we propose the continual predictive learning (CPL) approach, which learns a mixture world model via predictive experience replay and performs test-time adaptation with non-parametric task inference. We construct two new benchmarks based on RoboNet and KTH, in which different tasks correspond to different physical robotic environments or human actions. Our approach is shown to effectively mitigate forgetting and remarkably outperform the na\"ive combinations of previous art in video prediction and continual learning.
Video Polyp Segmentation: A Deep Learning Perspective
Mar 27, 2022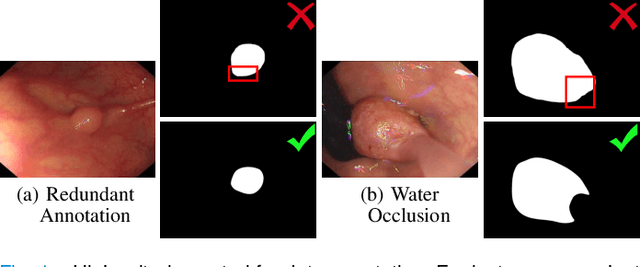
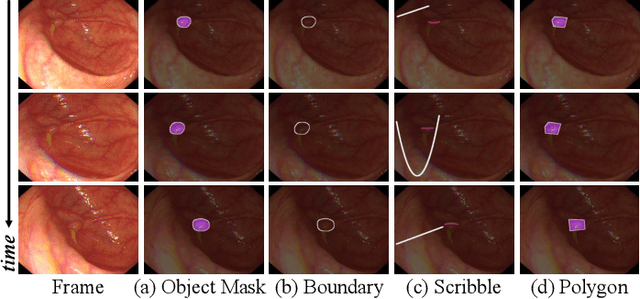
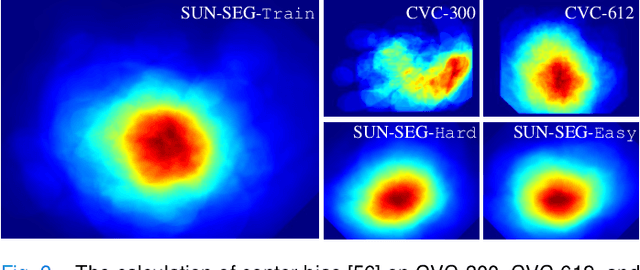
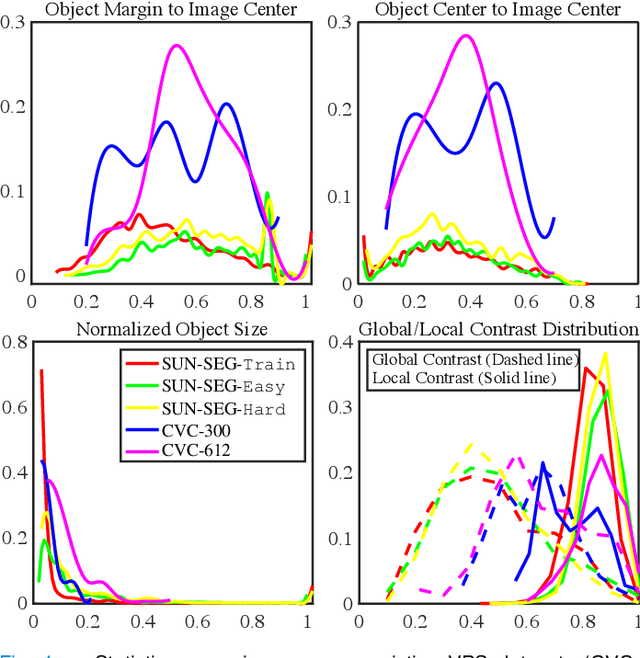
In the deep learning era, we present the first comprehensive video polyp segmentation (VPS) study. Over the years, developments in VPS are not moving forward with ease due to the lack of large-scale fine-grained segmentation annotations. To tackle this issue, we first introduce a high-quality per-frame annotated VPS dataset, named SUN-SEG, which includes 158,690 frames from the famous SUN dataset. We provide additional annotations with diverse types, i.e., attribute, object mask, boundary, scribble, and polygon. Second, we design a simple but efficient baseline, dubbed PNS+, consisting of a global encoder, a local encoder, and normalized self-attention (NS) blocks. The global and local encoders receive an anchor frame and multiple successive frames to extract long-term and short-term feature representations, which are then progressively updated by two NS blocks. Extensive experiments show that PNS+ achieves the best performance and real-time inference speed (170fps), making it a promising solution for the VPS task. Third, we extensively evaluate 13 representative polyp/object segmentation models on our SUN-SEG dataset and provide attribute-based comparisons. Benchmark results are available at https: //github.com/GewelsJI/VPS.
Specificity-preserving RGB-D Saliency Detection
Aug 18, 2021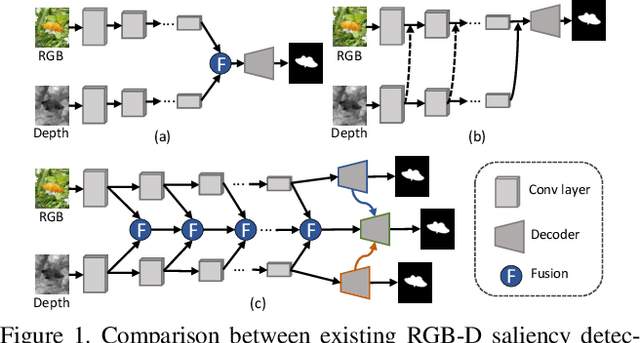
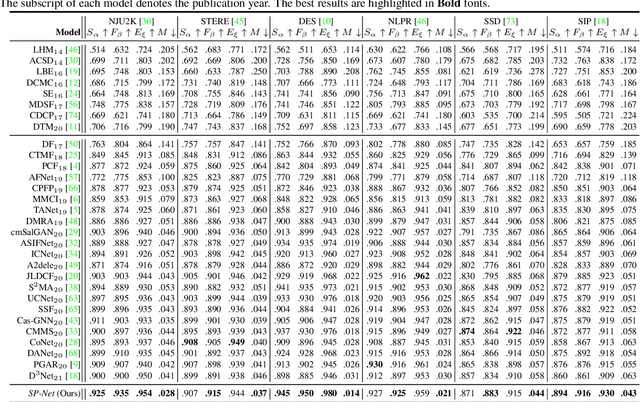
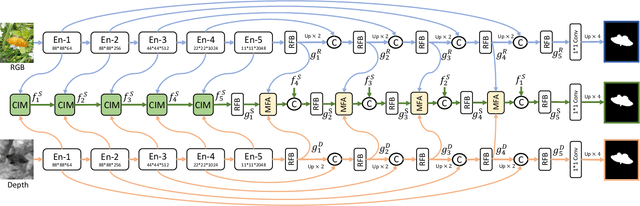
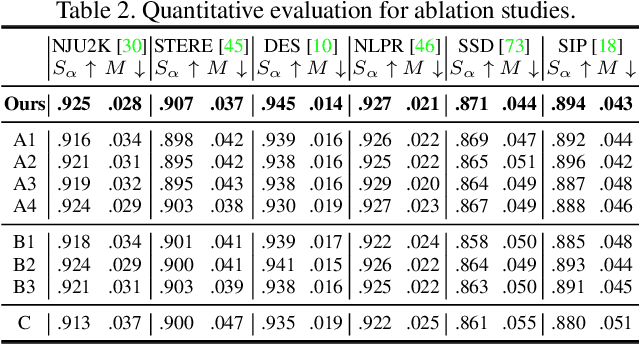
RGB-D saliency detection has attracted increasing attention, due to its effectiveness and the fact that depth cues can now be conveniently captured. Existing works often focus on learning a shared representation through various fusion strategies, with few methods explicitly considering how to preserve modality-specific characteristics. In this paper, taking a new perspective, we propose a specificity-preserving network (SP-Net) for RGB-D saliency detection, which benefits saliency detection performance by exploring both the shared information and modality-specific properties (e.g., specificity). Specifically, two modality-specific networks and a shared learning network are adopted to generate individual and shared saliency maps. A cross-enhanced integration module (CIM) is proposed to fuse cross-modal features in the shared learning network, which are then propagated to the next layer for integrating cross-level information. Besides, we propose a multi-modal feature aggregation (MFA) module to integrate the modality-specific features from each individual decoder into the shared decoder, which can provide rich complementary multi-modal information to boost the saliency detection performance. Further, a skip connection is used to combine hierarchical features between the encoder and decoder layers. Experiments on six benchmark datasets demonstrate that our SP-Net outperforms other state-of-the-art methods. Code is available at: https://github.com/taozh2017/SPNet.
Accelerated Multi-Modal MR Imaging with Transformers
Jun 29, 2021
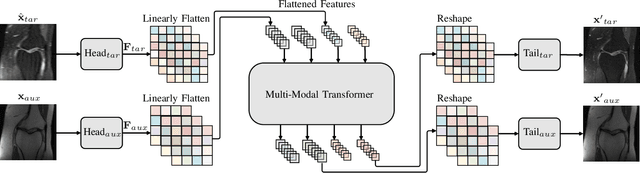
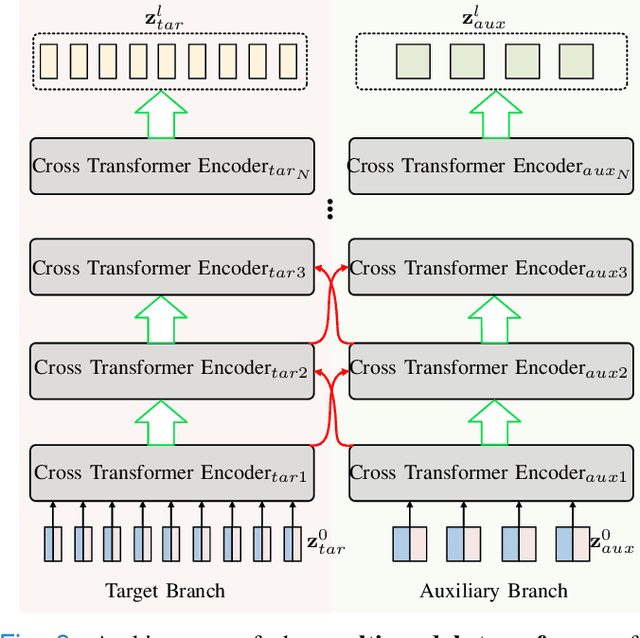
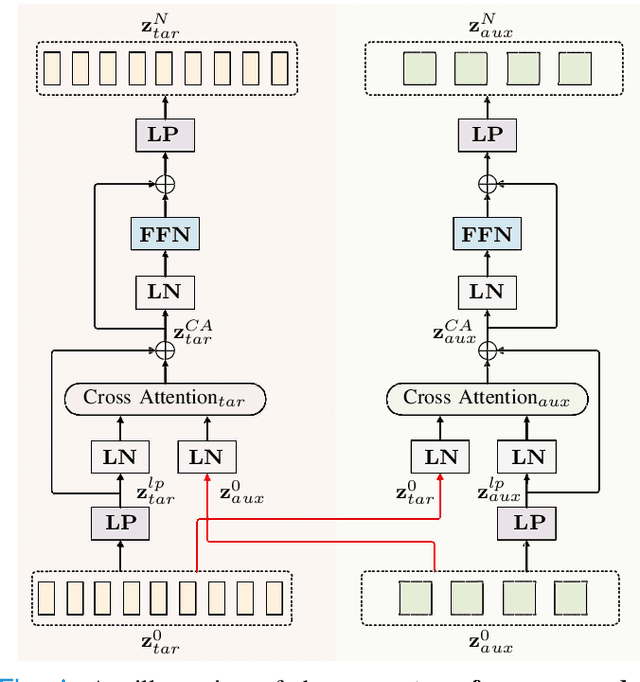
Accelerating multi-modal magnetic resonance (MR) imaging is a new and effective solution for fast MR imaging, providing superior performance in restoring the target modality from its undersampled counterpart with guidance from an auxiliary modality. However, existing works simply introduce the auxiliary modality as prior information, lacking in-depth investigations on the potential mechanisms for fusing two modalities. Further, they usually rely on the convolutional neural networks (CNNs), which focus on local information and prevent them from fully capturing the long-distance dependencies of global knowledge. To this end, we propose a multi-modal transformer (MTrans), which is capable of transferring multi-scale features from the target modality to the auxiliary modality, for accelerated MR imaging. By restructuring the transformer architecture, our MTrans gains a powerful ability to capture deep multi-modal information. More specifically, the target modality and the auxiliary modality are first split into two branches and then fused using a multi-modal transformer module. This module is based on an improved multi-head attention mechanism, named the cross attention module, which absorbs features from the auxiliary modality that contribute to the target modality. Our framework provides two appealing benefits: (i) MTrans is the first attempt at using improved transformers for multi-modal MR imaging, affording more global information compared with CNN-based methods. (ii) A new cross attention module is proposed to exploit the useful information in each branch at different scales. It affords both distinct structural information and subtle pixel-level information, which supplement the target modality effectively.
Context-aware Cross-level Fusion Network for Camouflaged Object Detection
May 26, 2021
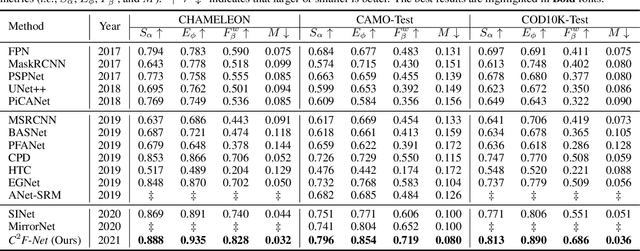
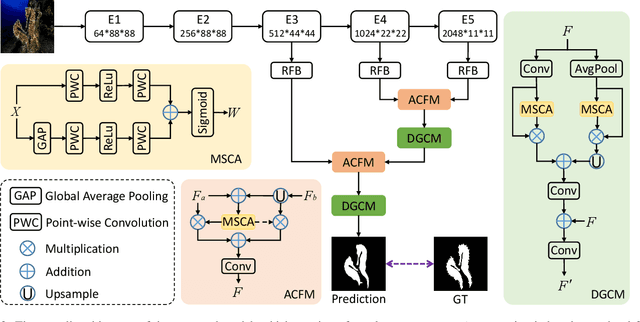

Camouflaged object detection (COD) is a challenging task due to the low boundary contrast between the object and its surroundings. In addition, the appearance of camouflaged objects varies significantly, e.g., object size and shape, aggravating the difficulties of accurate COD. In this paper, we propose a novel Context-aware Cross-level Fusion Network (C2F-Net) to address the challenging COD task. Specifically, we propose an Attention-induced Cross-level Fusion Module (ACFM) to integrate the multi-level features with informative attention coefficients. The fused features are then fed to the proposed Dual-branch Global Context Module (DGCM), which yields multi-scale feature representations for exploiting rich global context information. In C2F-Net, the two modules are conducted on high-level features using a cascaded manner. Extensive experiments on three widely used benchmark datasets demonstrate that our C2F-Net is an effective COD model and outperforms state-of-the-art models remarkably. Our code is publicly available at: https://github.com/thograce/C2FNet.
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 24, 2021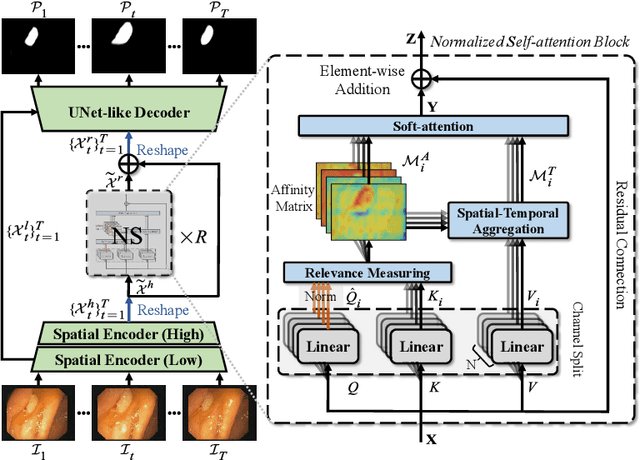
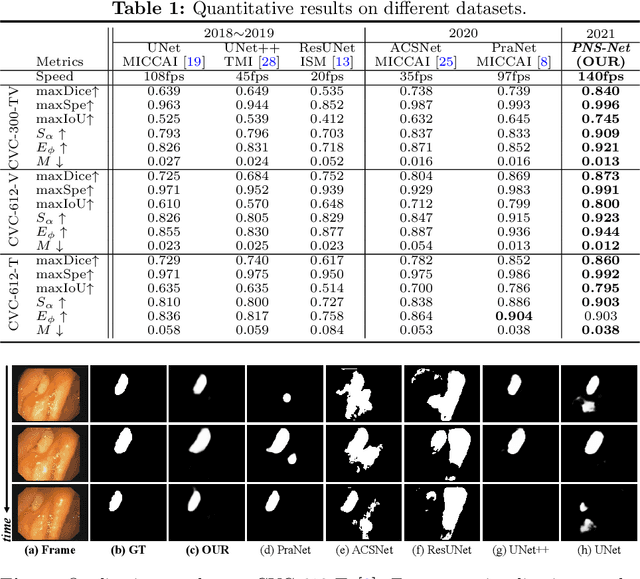
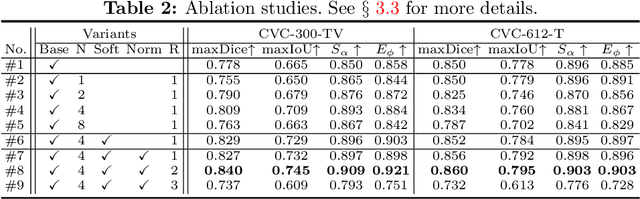
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
Learning Synergistic Attention for Light Field Salient Object Detection
May 16, 2021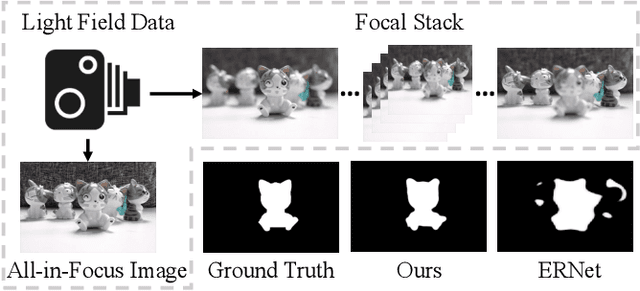
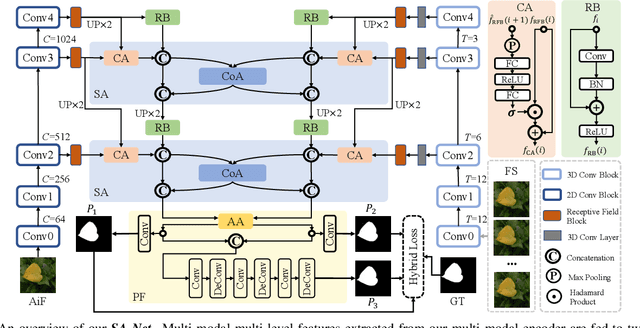
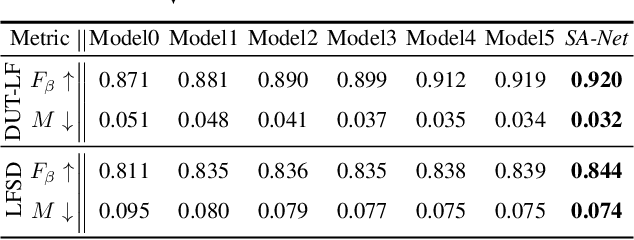
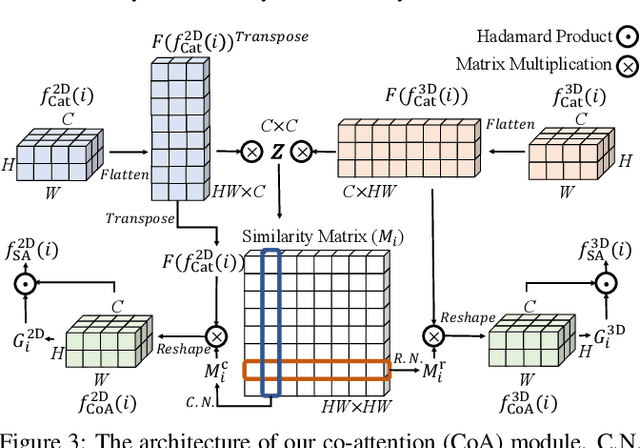
We propose a novel Synergistic Attention Network (SA-Net) to address the light field salient object detection by establishing a synergistic effect between multi-modal features with advanced attention mechanisms. Our SA-Net exploits the rich information of focal stacks via 3D convolutional neural networks, decodes the high-level features of multi-modal light field data with two cascaded synergistic attention modules, and predicts the saliency map using an effective feature fusion module in a progressive manner. Extensive experiments on three widely-used benchmark datasets show that our SA-Net outperforms 28 state-of-the-art models, sufficiently demonstrating its effectiveness and superiority. Our code will be made publicly available.
Dual-Octave Convolution for Accelerated Parallel MR Image Reconstruction
Apr 12, 2021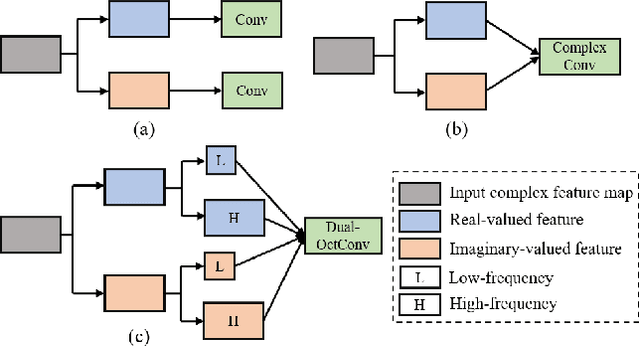
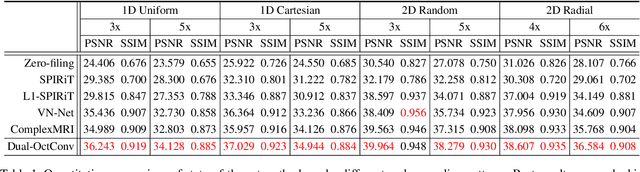
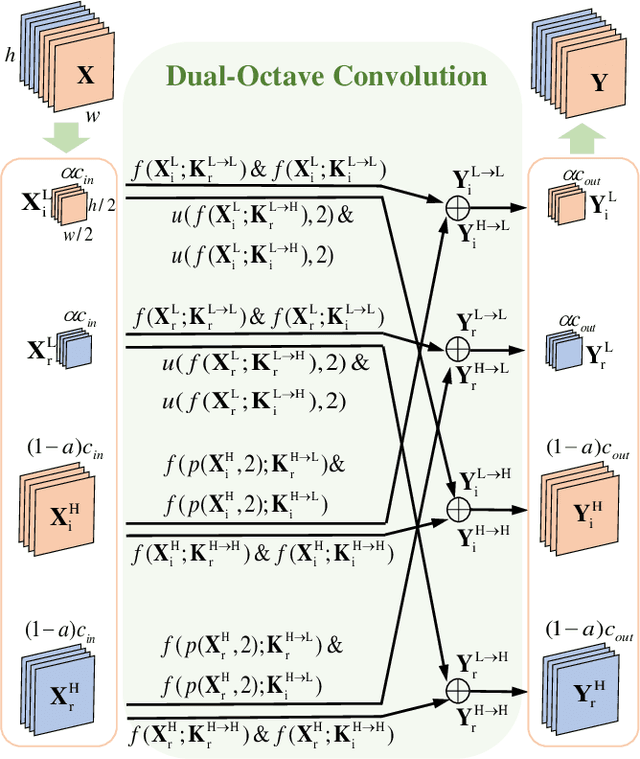
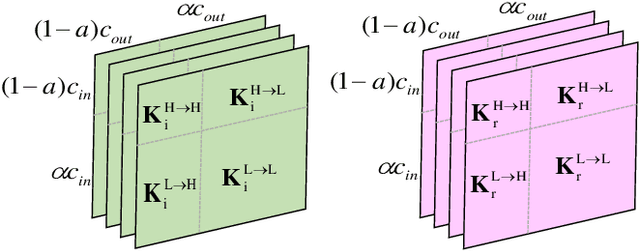
Magnetic resonance (MR) image acquisition is an inherently prolonged process, whose acceleration by obtaining multiple undersampled images simultaneously through parallel imaging has always been the subject of research. In this paper, we propose the Dual-Octave Convolution (Dual-OctConv), which is capable of learning multi-scale spatial-frequency features from both real and imaginary components, for fast parallel MR image reconstruction. By reformulating the complex operations using octave convolutions, our model shows a strong ability to capture richer representations of MR images, while at the same time greatly reducing the spatial redundancy. More specifically, the input feature maps and convolutional kernels are first split into two components (i.e., real and imaginary), which are then divided into four groups according to their spatial frequencies. Then, our Dual-OctConv conducts intra-group information updating and inter-group information exchange to aggregate the contextual information across different groups. Our framework provides two appealing benefits: (i) it encourages interactions between real and imaginary components at various spatial frequencies to achieve richer representational capacity, and (ii) it enlarges the receptive field by learning multiple spatial-frequency features of both the real and imaginary components. We evaluate the performance of the proposed model on the acceleration of multi-coil MR image reconstruction. Extensive experiments are conducted on an {in vivo} knee dataset under different undersampling patterns and acceleration factors. The experimental results demonstrate the superiority of our model in accelerated parallel MR image reconstruction. Our code is available at: github.com/chunmeifeng/Dual-OctConv.
* Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI) 2021