 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Scores Make Instance-dependent Label-noise Learning Possible
Jan 11, 2020

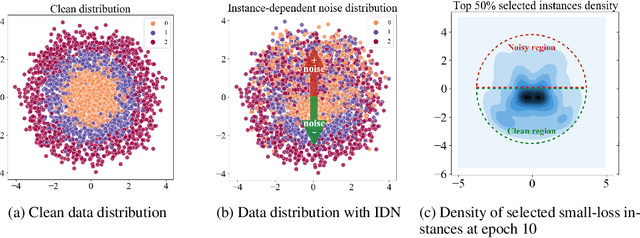
Learning with noisy labels has drawn a lot of attention. In this area, most of recent works only consider class-conditional noise, where the label noise is independent of its input features. This noise model may not be faithful to many real-world applications. Instead, few pioneer works have studied instance-dependent noise, but these methods are limited to strong assumptions on noise models. To alleviate this issue, we introduce confidence-scored instance-dependent noise (CSIDN), where each instance-label pair is associated with a confidence score. The confidence scores are sufficient to estimate the noise functions of each instance with minimal assumptions. Moreover, such scores can be easily and cheaply derived during the construction of the dataset through crowdsourcing or automatic annotation. To handle CSIDN, we design a benchmark algorithm termed instance-level forward correction. Empirical results on synthetic and real-world datasets demonstrate the utility of our proposed method.
Where is the Bottleneck of Adversarial Learning with Unlabeled Data?
Nov 20, 2019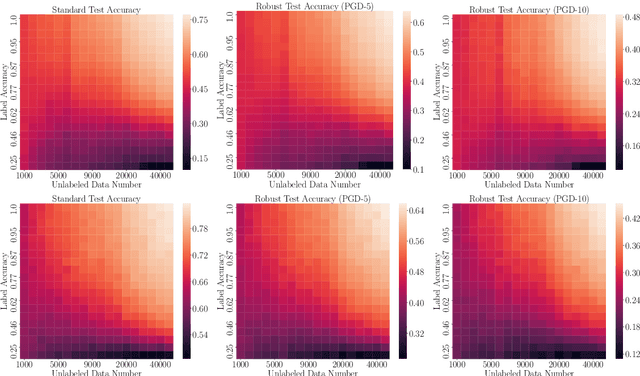
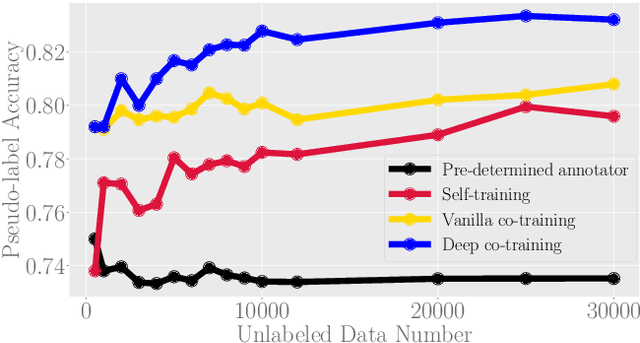
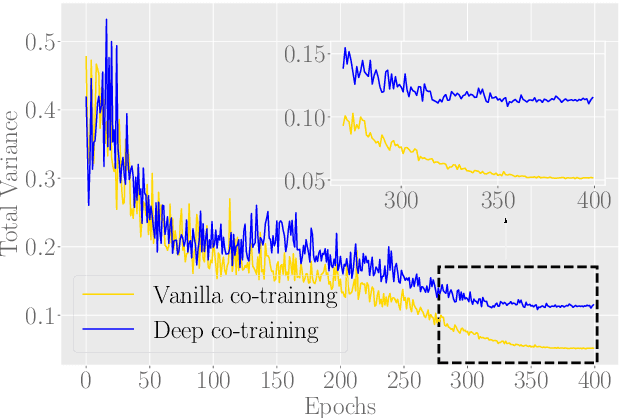
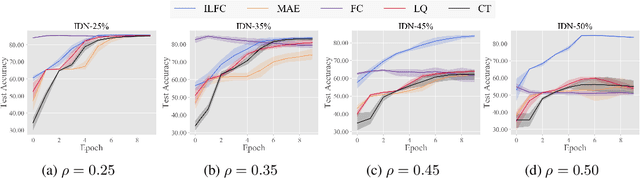
Deep neural networks (DNNs) are incredibly brittle due to adversarial examples. To robustify DNNs, adversarial training was proposed, which requires large-scale but well-labeled data. However, it is quite expensive to annotate large-scale data well. To compensate for this shortage, several seminal works are utilizing large-scale unlabeled data. In this paper, we observe that seminal works do not perform well, since the quality of pseudo labels on unlabeled data is quite poor, especially when the amount of unlabeled data is significantly larger than that of labeled data. We believe that the quality of pseudo labels is the bottleneck of adversarial learning with unlabeled data. To tackle this bottleneck, we leverage deep co-training, which trains two deep networks and encourages two networks diverged by exploiting peer's adversarial examples. Based on deep co-training, we propose robust co-training (RCT) for adversarial learning with unlabeled data. We conduct comprehensive experiments on CIFAR-10 and SVHN datasets. Empirical results demonstrate that our RCT can significantly outperform baselines (e.g., robust self-training (RST)) in both standard test accuracy and robust test accuracy w.r.t. different datasets, different network structures, and different types of adversarial training.
Searching to Exploit Memorization Effect in Learning from Corrupted Labels
Nov 06, 2019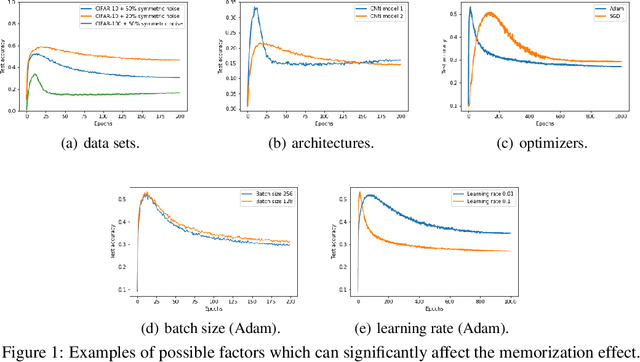
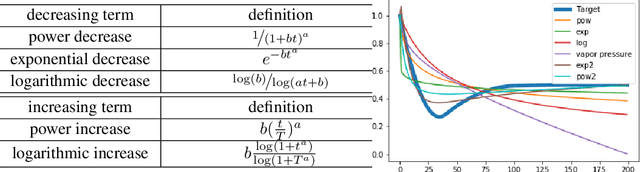
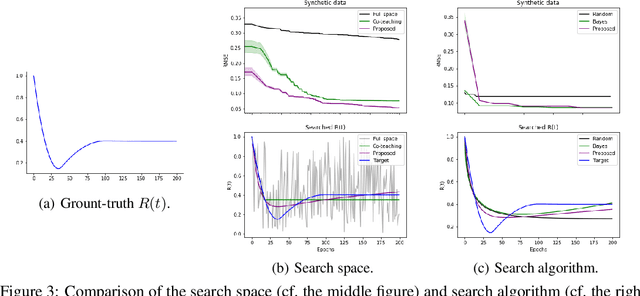
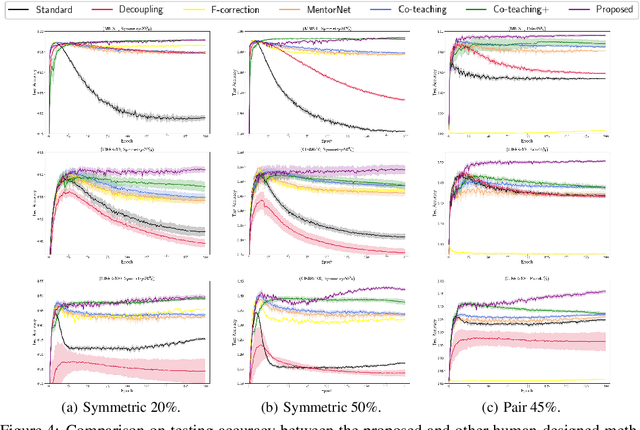
Sample-selection approaches, which attempt to pick up clean instances from the noisy training data set, have become one promising direction to robust learning from corrupted labels. These methods all build on the memorization effect, which means deep networks learn easy patterns first and then gradually over-fit the training data set. In this paper, we show how to properly select instances so that the training process can benefit the most from the memorization effect is a hard problem. Specifically, memorization can heavily depend on many factors, e.g., data set and network architecture. Nonetheless, there still exist general patterns of how memorization can occur. These facts motivate us to exploit memorization by automated machine learning (AutoML) techniques. First, we design an expressive but compact search space based on observed general patterns. Then, we propose to use the natural gradient-based search algorithm to efficiently search through space. Finally, extensive experiments on both synthetic data sets and benchmark data sets demonstrate that the proposed method can not only be much efficient than existing AutoML algorithms but can also achieve much better performance than the state-of-the-art approaches for learning from corrupted labels.
Scalable Evaluation and Improvement of Document Set Expansion via Neural Positive-Unlabeled Learning
Oct 29, 2019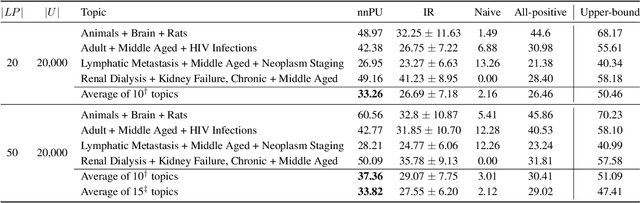
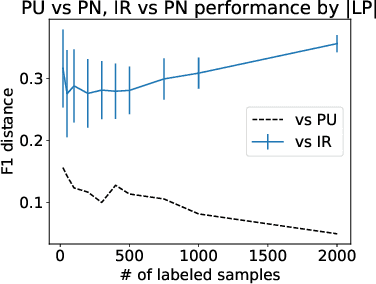
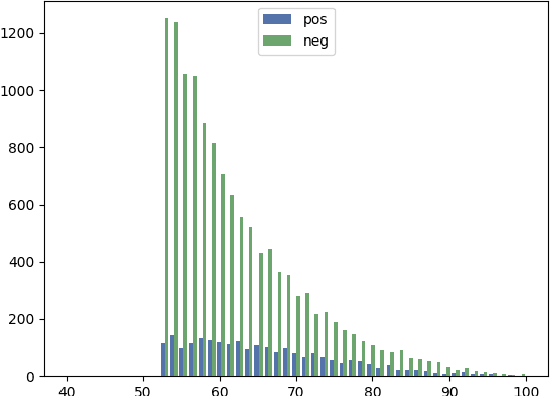
We consider the situation in which a user has collected a small set of documents on a cohesive topic, and they want to retrieve additional documents on this topic from a large collection. Information Retrieval (IR) solutions treat the document set as a query, and look for similar documents in the collection. We propose to extend the IR approach by treating the problem as an instance of positive-unlabeled (PU) learning---i.e., learning binary classifiers from only positive and unlabeled data, where the positive data corresponds to the query documents, and the unlabeled data is the results returned by the IR engine. Utilizing PU learning for text with big neural networks is a largely unexplored field. We discuss various challenges in applying PU learning to the setting, including an unknown class prior, extremely imbalanced data and large-scale accurate evaluation of models, and we propose solutions and empirically validate them. We demonstrate the effectiveness of the method using a series of experiments of retrieving PubMed abstracts adhering to fine-grained topics. We demonstrate improvements over the base IR solution and other baselines. Implementation is available at https://github.com/sayaendo/document-set-expansion-pu.
Mitigating Overfitting in Supervised Classification from Two Unlabeled Datasets: A Consistent Risk Correction Approach
Oct 20, 2019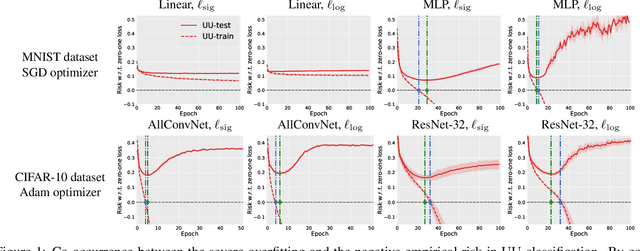
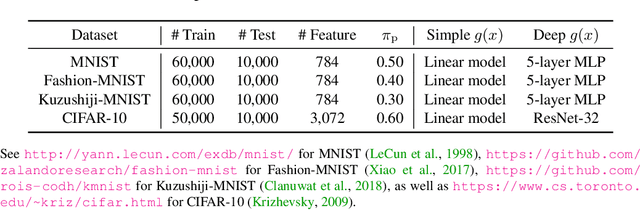
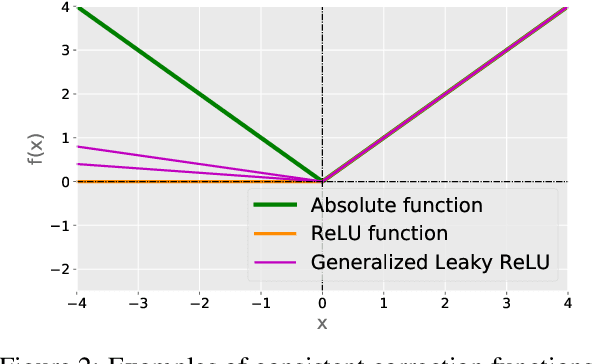
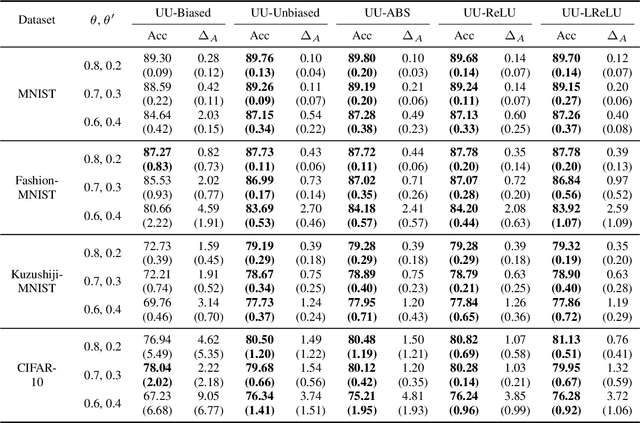
From two unlabeled (U) datasets with different class priors, we can train a binary classifier by empirical risk minimization, which is called UU classification. It is promising since UU methods are compatible with any neural network (NN) architecture and optimizer as if it is standard supervised classification. In this paper, however, we find that UU methods may suffer severe overfitting, and there is a high co-occurrence between the overfitting and the negative empirical risk regardless of datasets, NN architectures, and optimizers. Hence, to mitigate the overfitting problem of UU methods, we propose to keep two parts of the empirical risk (i.e., false positive and false negative) non-negative by wrapping them in a family of correction functions. We theoretically show that the corrected risk estimator is still asymptotically unbiased and consistent; furthermore we establish an estimation error bound for the corrected risk minimizer. Experiments with feedforward/residual NNs on standard benchmarks demonstrate that our proposed correction can successfully mitigate the overfitting of UU methods and significantly improve the classification accuracy.
Direction Matters: On Influence-Preserving Graph Summarization and Max-cut Principle for Directed Graphs
Jul 22, 2019

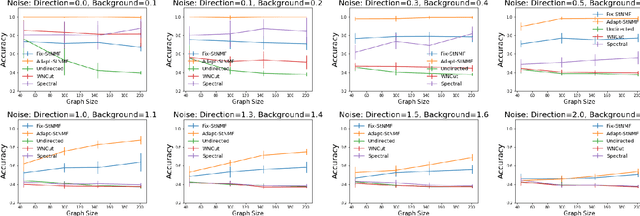
Summarizing large-scaled directed graphs into small-scale representations is a useful but less studied problem setting. Conventional clustering approaches, which based on "Min-Cut"-style criteria, compress both the vertices and edges of the graph into the communities, that lead to a loss of directed edge information. On the other hand, compressing the vertices while preserving the directed edge information provides a way to learn the small-scale representation of a directed graph. The reconstruction error, which measures the edge information preserved by the summarized graph, can be used to learn such representation. Compared to the original graphs, the summarized graphs are easier to analyze and are capable of extracting group-level features which is useful for efficient interventions of population behavior. In this paper, we present a model, based on minimizing reconstruction error with non-negative constraints, which relates to a "Max-Cut" criterion that simultaneously identifies the compressed nodes and the directed compressed relations between these nodes. A multiplicative update algorithm with column-wise normalization is proposed. We further provide theoretical results on the identifiability of the model and on the convergence of the proposed algorithms. Experiments are conducted to demonstrate the accuracy and robustness of the proposed method.
Uncoupled Regression from Pairwise Comparison Data
Jun 03, 2019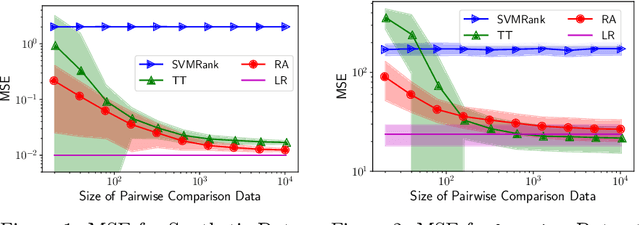
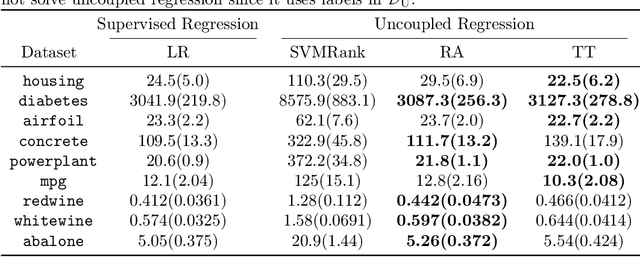
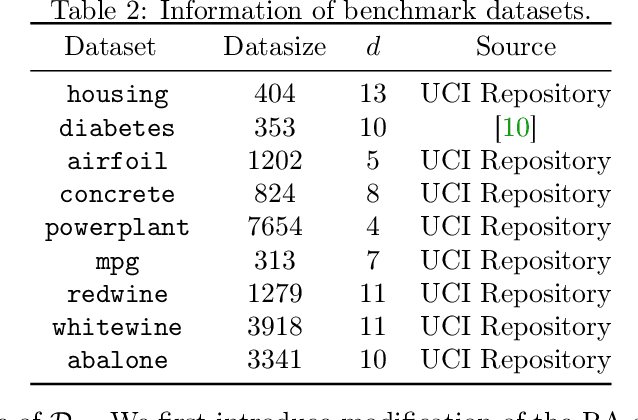
Uncoupled regression is the problem to learn a model from unlabeled data and the set of target values while the correspondence between them is unknown. Such a situation arises in predicting anonymized targets that involve sensitive information, e.g., one's annual income. Since existing methods for uncoupled regression often require strong assumptions on the true target function, and thus, their range of applications is limited, we introduce a novel framework that does not require such assumptions in this paper. Our key idea is to utilize pairwise comparison data, which consists of pairs of unlabeled data that we know which one has a larger target value. Such pairwise comparison data is easy to collect, as typically discussed in the learning-to-rank scenario, and does not break the anonymity of data. We propose two practical methods for uncoupled regression from pairwise comparison data and show that the learned regression model converges to the optimal model with the optimal parametric convergence rate when the target variable distributes uniformly. Moreover, we empirically show that for linear models the proposed methods are comparable to ordinary supervised regression with labeled data.
Are Anchor Points Really Indispensable in Label-Noise Learning?
Jun 01, 2019
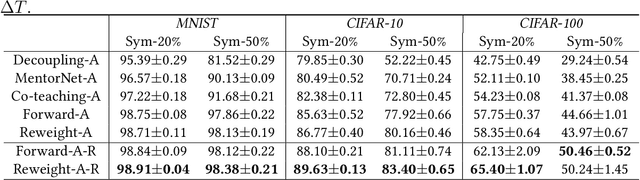
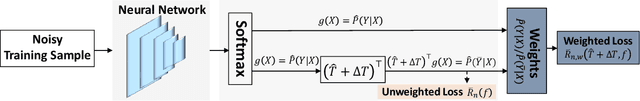
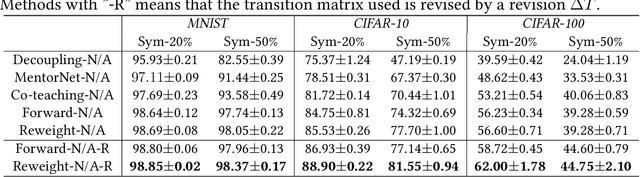
In label-noise learning, \textit{noise transition matrix}, denoting the probabilities that clean labels flip into noisy labels, plays a central role in building \textit{statistically consistent classifiers}. Existing theories have shown that the transition matrix can be learned by exploiting \textit{anchor points} (i.e., data points that belong to a specific class almost surely). However, when there are no anchor points, the transition matrix will be poorly learned, and those current consistent classifiers will significantly degenerate. In this paper, without employing anchor points, we propose a \textit{transition-revision} ($T$-Revision) method to effectively learn transition matrices, leading to better classifiers. Specifically, to learn a transition matrix, we first initialize it by exploiting data points that are similar to anchor points, having high \textit{noisy class posterior probabilities}. Then, we modify the initialized matrix by adding a \textit{slack variable}, which can be learned and validated together with the classifier by using noisy data. Empirical results on benchmark-simulated and real-world label-noise datasets demonstrate that without using exact anchor points, the proposed method is superior to the state-of-the-art label-noise learning methods.
Fast and Robust Rank Aggregation against Model Misspecification
May 29, 2019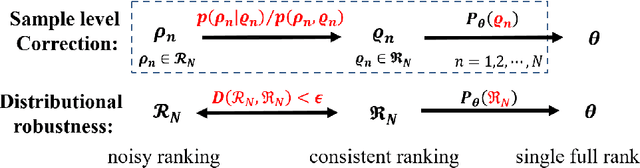

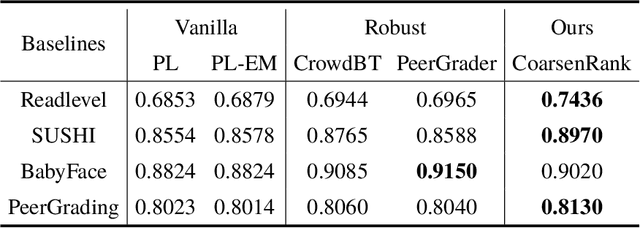
In rank aggregation, preferences from different users are summarized into a total order under the homogeneous data assumption. Thus, model misspecification arises and rank aggregation methods take some noise models into account. However, they all rely on certain noise model assumptions and cannot handle agnostic noises in the real world. In this paper, we propose CoarsenRank, which rectifies the underlying data distribution directly and aligns it to the homogeneous data assumption without involving any noise model. To this end, we define a neighborhood of the data distribution over which Bayesian inference of CoarsenRank is performed, and therefore the resultant posterior enjoys robustness against model misspecification. Further, we derive a tractable closed-form solution for CoarsenRank making it computationally efficient. Experiments on real-world datasets show that CoarsenRank is fast and robust, achieving consistent improvement over baseline methods.
Butterfly: A Panacea for All Difficulties in Wildly Unsupervised Domain Adaptation
May 23, 2019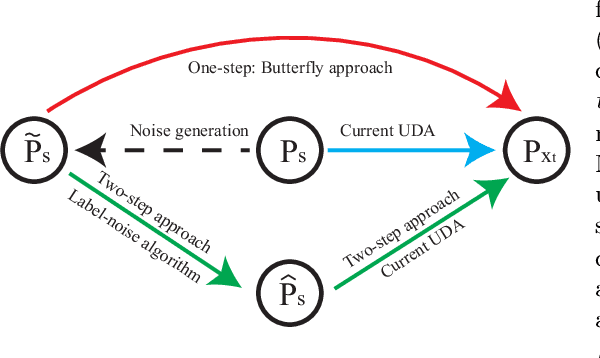
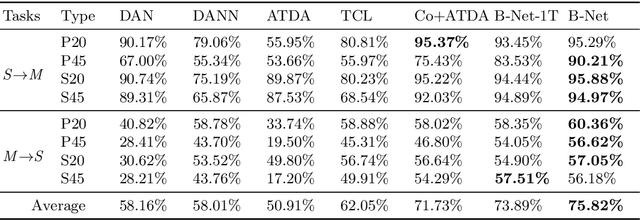
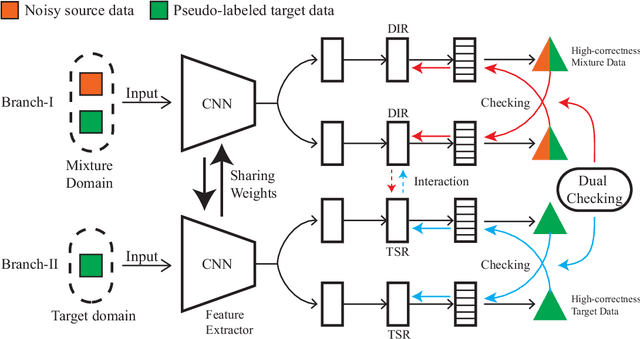

In unsupervised domain adaptation (UDA), classifiers for the target domain (TD) are trained with clean labeled data from the source domain (SD) and unlabeled data from TD. However, in the wild, it is hard to acquire a large amount of perfectly clean labeled data in SD given limited budget. Hence, we consider a new, more realistic and more challenging problem setting, where classifiers have to be trained with noisy labeled data from SD and unlabeled data from TD---we name it wildly UDA (WUDA). We show that WUDA provably ruins all UDA methods if taking no care of label noise in SD, and to this end, we propose a Butterfly framework, a panacea for all difficulties in WUDA. Butterfly maintains four models (e.g., deep networks) simultaneously, where two take care of all adaptations (i.e., noisy-to-clean, labeled-to-unlabeled, and SD-to-TD-distributional) and then the other two can focus on classification in TD. As a consequence, Butterfly possesses all the necessary components for all the challenges in WUDA. Experiments demonstrate that under WUDA, Butterfly significantly outperforms existing baseline methods.