 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolygames: Improved Zero Learning
Jan 27, 2020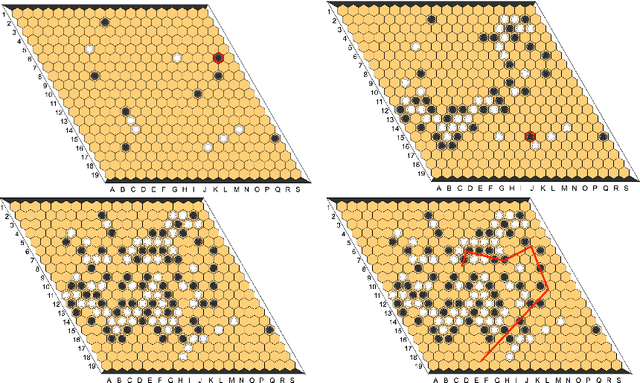
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
Scaling Up Online Speech Recognition Using ConvNets
Jan 27, 2020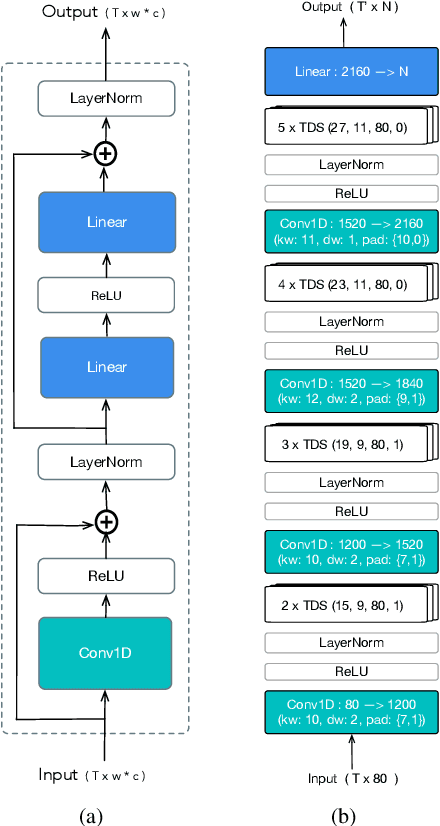
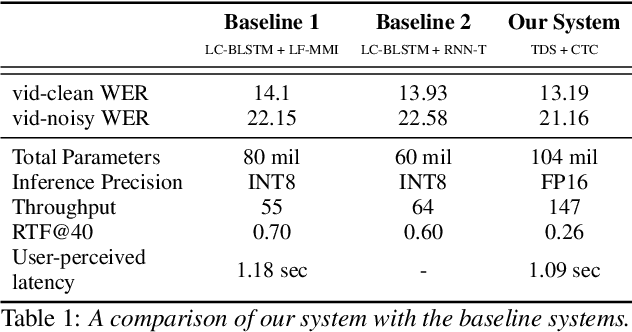

We design an online end-to-end speech recognition system based on Time-Depth Separable (TDS) convolutions and Connectionist Temporal Classification (CTC). We improve the core TDS architecture in order to limit the future context and hence reduce latency while maintaining accuracy. The system has almost three times the throughput of a well tuned hybrid ASR baseline while also having lower latency and a better word error rate. Also important to the efficiency of the recognizer is our highly optimized beam search decoder. To show the impact of our design choices, we analyze throughput, latency, accuracy, and discuss how these metrics can be tuned based on the user requirements.
Libri-Light: A Benchmark for ASR with Limited or No Supervision
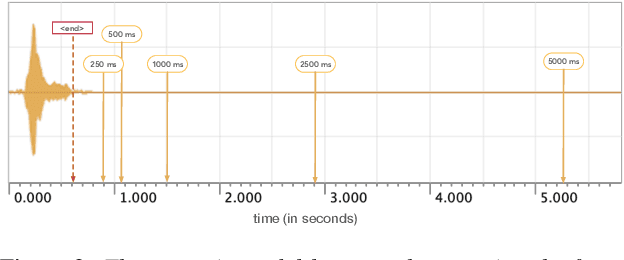
Dec 17, 2019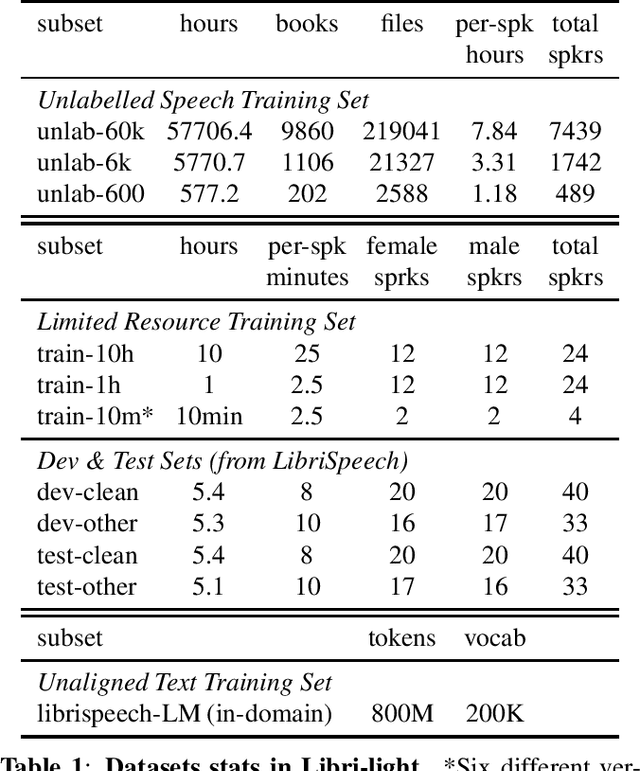
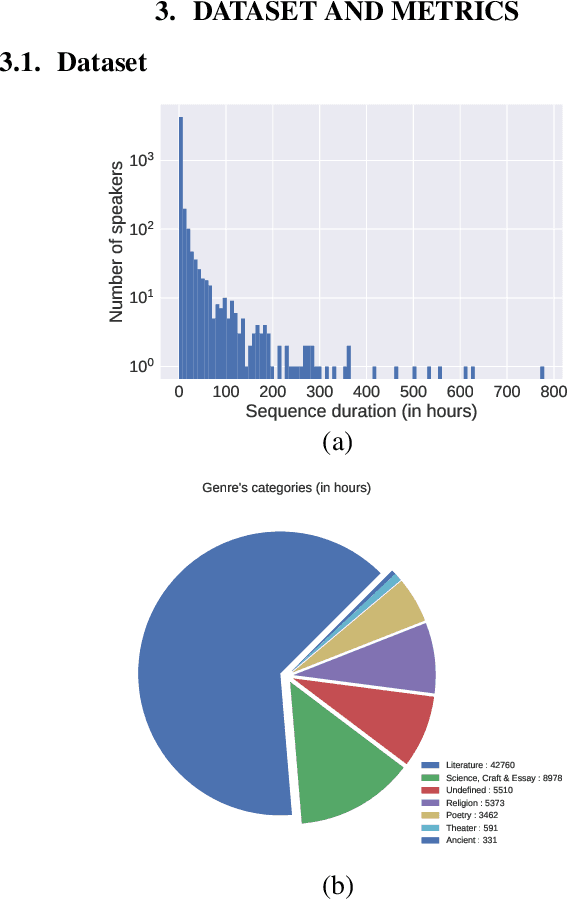
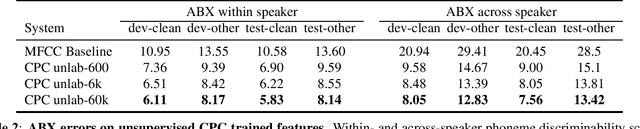
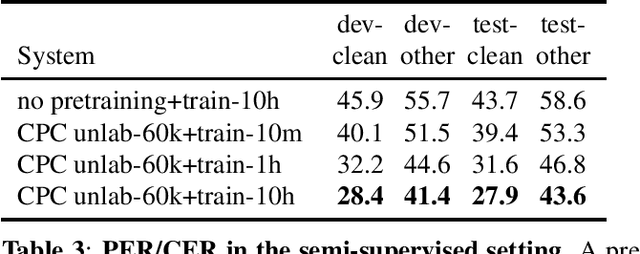
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.
End-to-end ASR: from Supervised to Semi-Supervised Learning with Modern Architectures
Nov 19, 2019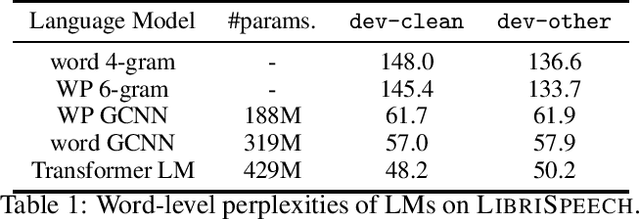
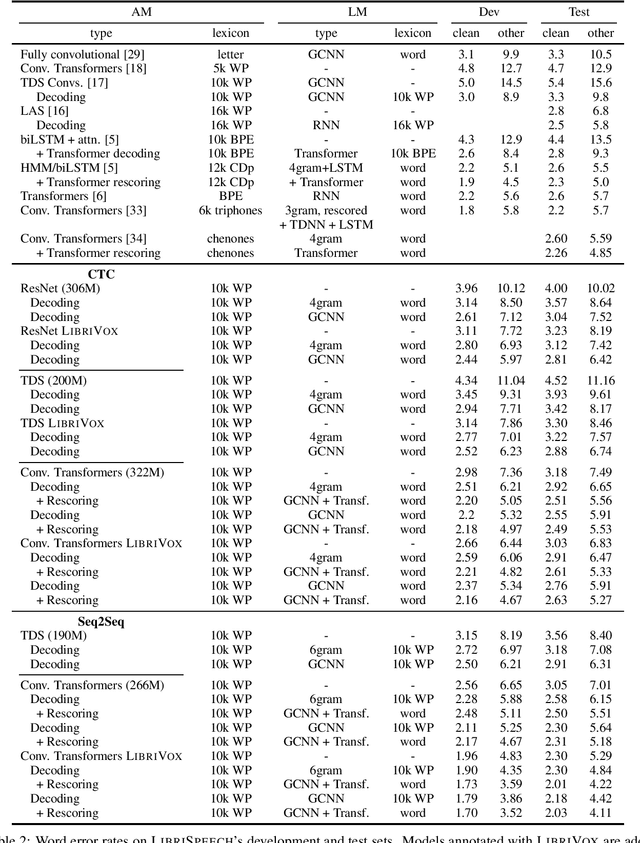
We study ResNet-, Time-Depth Separable ConvNets-, and Transformer-based acoustic models, trained with CTC or Seq2Seq criterions. We perform experiments on the LibriSpeech dataset, with and without LM decoding, optionally with beam rescoring. We reach 5.18% WER with external language models for decoding and rescoring. Additionally, we leverage the unlabeled data from LibriVox by doing semi-supervised training and show that it is possible to reach 5.29% WER on test-other without decoding, and 4.11% WER with decoding and rescoring, with only the standard 960 hours from LibriSpeech as labeled data.
Deja-vu: Double Feature Presentation in Deep Transformer Networks
Oct 23, 2019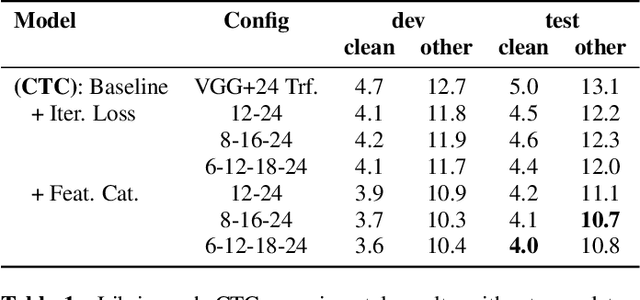
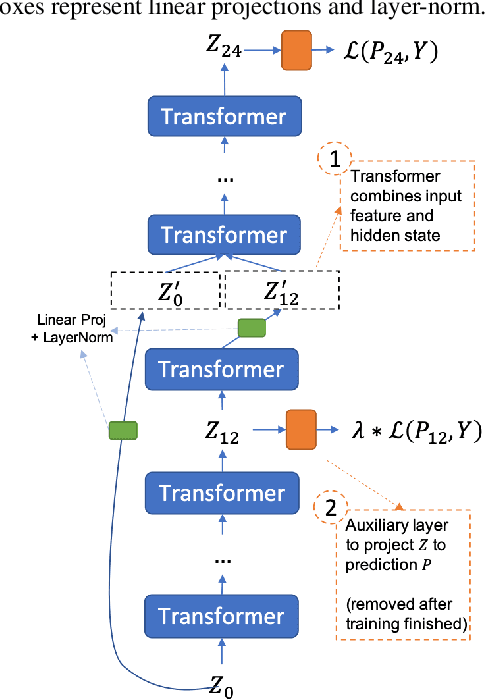
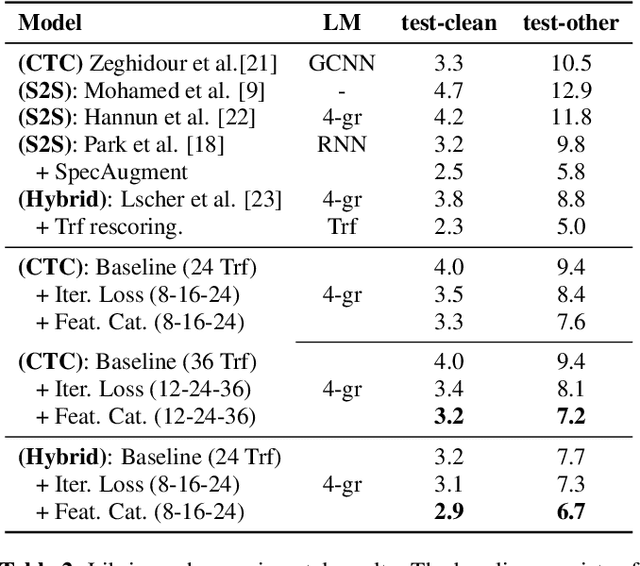
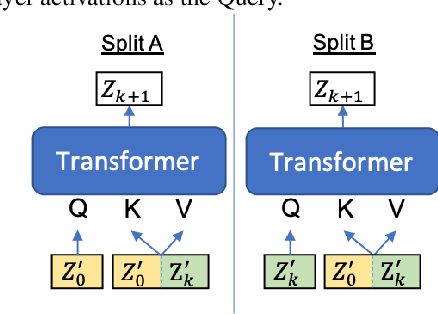
Deep acoustic models typically receive features in the first layer of the network, and process increasingly abstract representations in the subsequent layers. Here, we propose to feed the input features at multiple depths in the acoustic model. As our motivation is to allow acoustic models to re-examine their input features in light of partial hypotheses we introduce intermediate model heads and loss function. We study this architecture in the context of deep Transformer networks, and we use an attention mechanism over both the previous layer activations and the input features. To train this model's intermediate output hypothesis, we apply the objective function at each layer right before feature re-use. We find that the use of such intermediate losses significantly improves performance by itself, as well as enabling input feature re-use. We present results on both Librispeech, and a large scale video dataset, with relative improvements of 10 - 20% for Librispeech and 3.2 - 13% for videos.
A Structured Prediction Approach for Generalization in Cooperative Multi-Agent Reinforcement Learning
Oct 19, 2019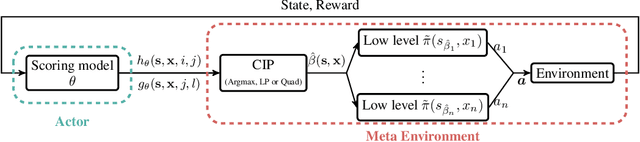
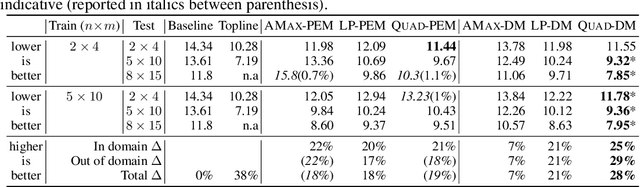
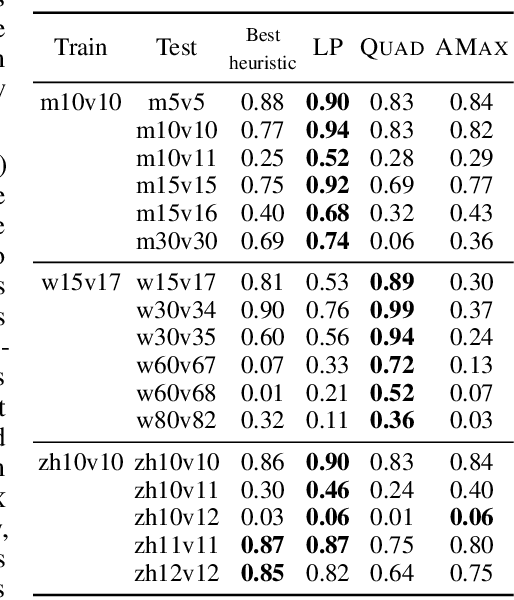
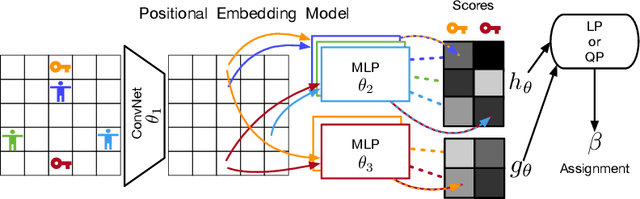
Effective coordination is crucial to solve multi-agent collaborative (MAC) problems. While centralized reinforcement learning methods can optimally solve small MAC instances, they do not scale to large problems and they fail to generalize to scenarios different from those seen during training. In this paper, we consider MAC problems with some intrinsic notion of locality (e.g., geographic proximity) such that interactions between agents and tasks are locally limited. By leveraging this property, we introduce a novel structured prediction approach to assign agents to tasks. At each step, the assignment is obtained by solving a centralized optimization problem (the inference procedure) whose objective function is parameterized by a learned scoring model. We propose different combinations of inference procedures and scoring models able to represent coordination patterns of increasing complexity. The resulting assignment policy can be efficiently learned on small problem instances and readily reused in problems with more agents and tasks (i.e., zero-shot generalization). We report experimental results on a toy search and rescue problem and on several target selection scenarios in StarCraft: Brood War, in which our model significantly outperforms strong rule-based baselines on instances with 5 times more agents and tasks than those seen during training.
Why Build an Assistant in Minecraft?
Jul 25, 2019In this document we describe a rationale for a research program aimed at building an open "assistant" in the game Minecraft, in order to make progress on the problems of natural language understanding and learning from dialogue.
Growing Action Spaces
Jun 28, 2019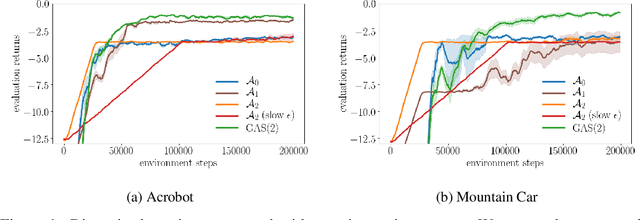
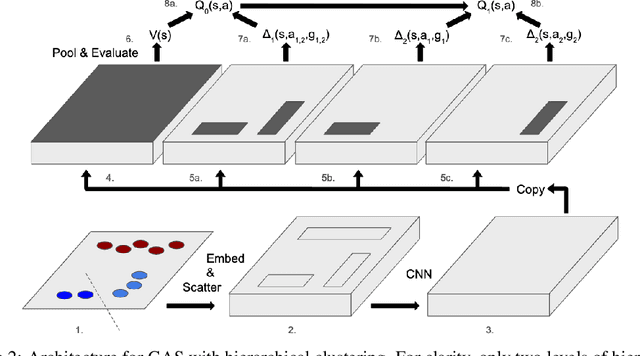
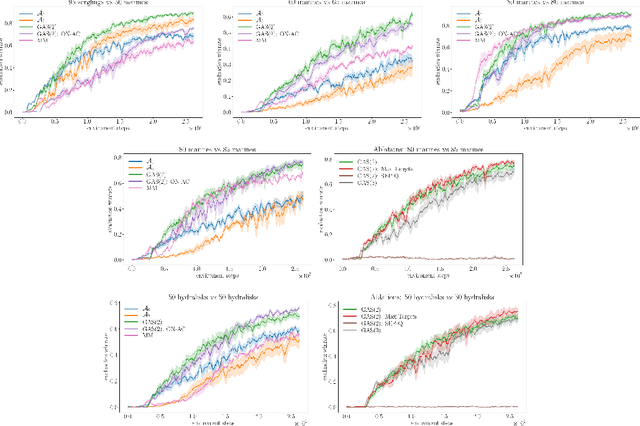

In complex tasks, such as those with large combinatorial action spaces, random exploration may be too inefficient to achieve meaningful learning progress. In this work, we use a curriculum of progressively growing action spaces to accelerate learning. We assume the environment is out of our control, but that the agent may set an internal curriculum by initially restricting its action space. Our approach uses off-policy reinforcement learning to estimate optimal value functions for multiple action spaces simultaneously and efficiently transfers data, value estimates, and state representations from restricted action spaces to the full task. We show the efficacy of our approach in proof-of-concept control tasks and on challenging large-scale StarCraft micromanagement tasks with large, multi-agent action spaces.
Word-level Speech Recognition with a Dynamic Lexicon
Jun 10, 2019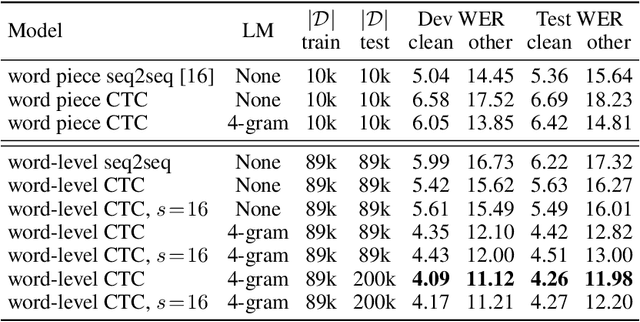

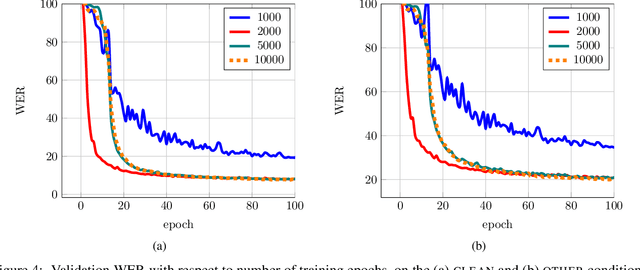
We propose a direct-to-word sequence model with a dynamic lexicon. Our word network constructs word embeddings dynamically from the character level tokens. The word network can be integrated seamlessly with arbitrary sequence models including Connectionist Temporal Classification and encoder-decoder models with attention. Sub-word units are commonly used in speech recognition yet are generated without the use of acoustic context. We show our direct-to-word model can achieve word error rate gains over sub-word level models for speech recognition. Furthermore, we empirically validate that the word-level embeddings we learn contain significant acoustic information, making them more suitable for use in speech recognition. We also show that our direct-to-word approach retains the ability to predict words not seen at training time without any retraining.
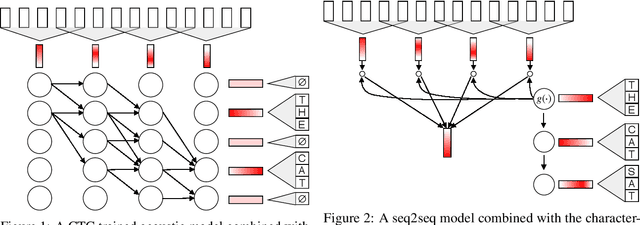
Who Needs Words? Lexicon-Free Speech Recognition
Apr 09, 2019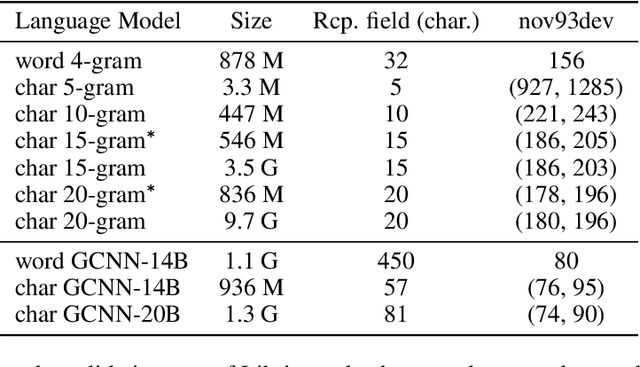
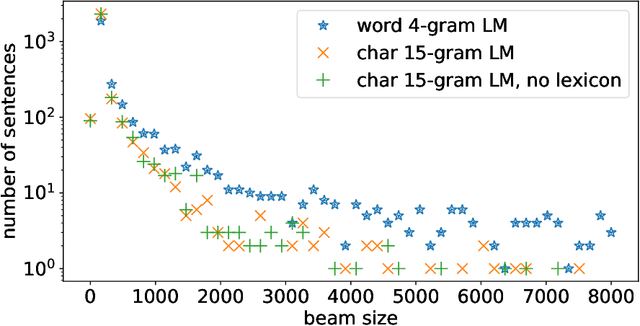
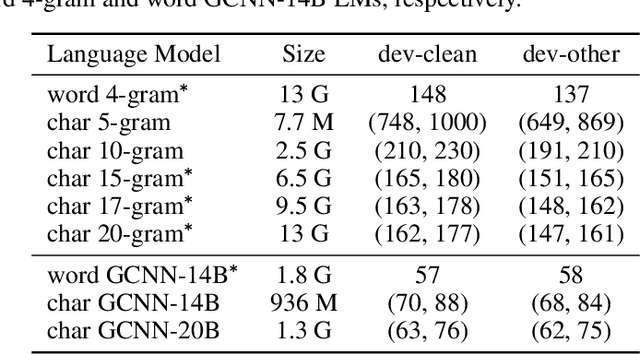
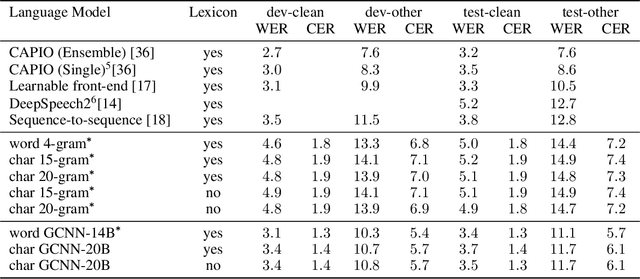
Lexicon-free speech recognition naturally deals with the problem of out-of-vocabulary (OOV) words. In this paper, we show that character-based language models (LM) can perform as well as word-based LMs for speech recognition, in word error rates (WER), even without restricting the decoding to a lexicon. We study character-based LMs and show that convolutional LMs can effectively leverage large (character) contexts, which is key for good speech recognition performance downstream. We specifically show that the lexicon-free decoding performance (WER) on utterances with OOV words using character-based LMs is better than lexicon-based decoding, both with character or word-based LMs.