 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAVOR#: Sharp Attention Kernel Approximations via New Classes of Positive Random Features
Feb 01, 2023



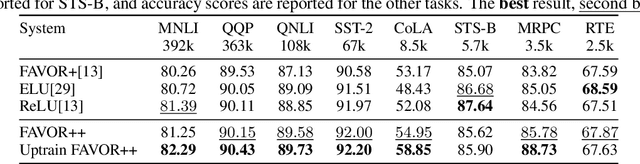
The problem of efficient approximation of a linear operator induced by the Gaussian or softmax kernel is often addressed using random features (RFs) which yield an unbiased approximation of the operator's result. Such operators emerge in important applications ranging from kernel methods to efficient Transformers. We propose parameterized, positive, non-trigonometric RFs which approximate Gaussian and softmax-kernels. In contrast to traditional RF approximations, parameters of these new methods can be optimized to reduce the variance of the approximation, and the optimum can be expressed in closed form. We show that our methods lead to variance reduction in practice ($e^{10}$-times smaller variance and beyond) and outperform previous methods in a kernel regression task. Using our proposed mechanism, we also present FAVOR#, a method for self-attention approximation in Transformers. We show that FAVOR# outperforms other random feature methods in speech modelling and natural language processing.
DETR++: Taming Your Multi-Scale Detection Transformer
Jun 07, 2022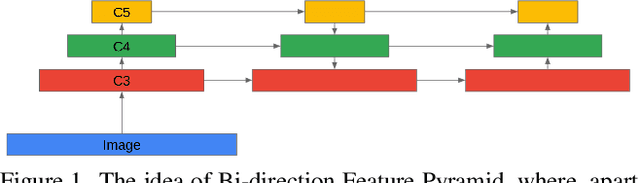
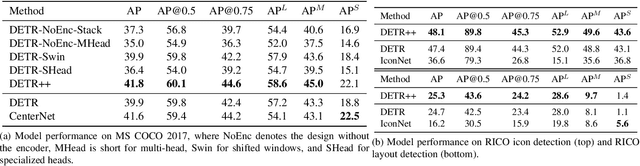
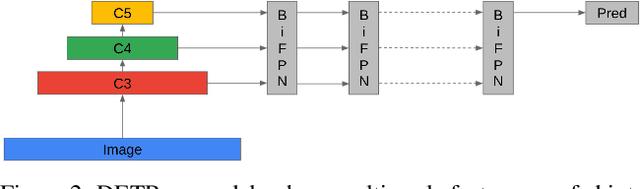
Convolutional Neural Networks (CNN) have dominated the field of detection ever since the success of AlexNet in ImageNet classification [12]. With the sweeping reform of Transformers [27] in natural language processing, Carion et al. [2] introduce the Transformer-based detection method, i.e., DETR. However, due to the quadratic complexity in the self-attention mechanism in the Transformer, DETR is never able to incorporate multi-scale features as performed in existing CNN-based detectors, leading to inferior results in small object detection. To mitigate this issue and further improve performance of DETR, in this work, we investigate different methods to incorporate multi-scale features and find that a Bi-directional Feature Pyramid (BiFPN) works best with DETR in further raising the detection precision. With this discovery, we propose DETR++, a new architecture that improves detection results by 1.9% AP on MS COCO 2017, 11.5% AP on RICO icon detection, and 9.1% AP on RICO layout extraction over existing baselines.
Chefs' Random Tables: Non-Trigonometric Random Features
May 30, 2022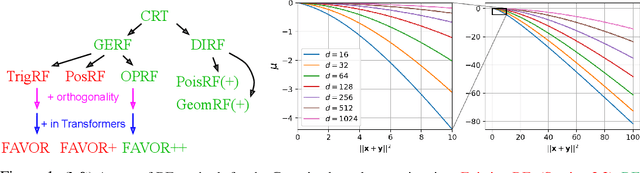
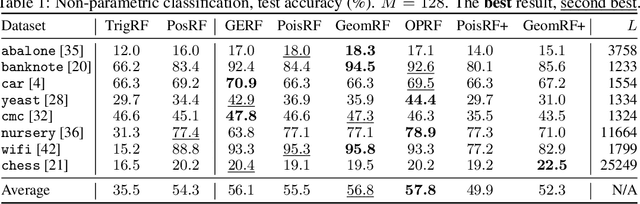
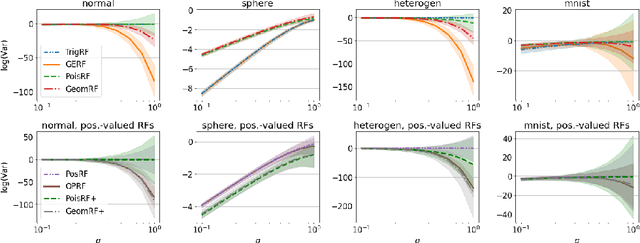
We introduce chefs' random tables (CRTs), a new class of non-trigonometric random features (RFs) to approximate Gaussian and softmax kernels. CRTs are an alternative to standard random kitchen sink (RKS) methods, which inherently rely on the trigonometric maps. We present variants of CRTs where RFs are positive, a key requirement for applications in recent low-rank Transformers. Further variance reduction is possible by leveraging statistics which are simple to compute. One instantiation of CRTs, the optimal positive random features (OPRFs), is to our knowledge the first RF method for unbiased softmax kernel estimation with positive and bounded RFs, resulting in exponentially small tails and much lower variance than its counterparts. As we show, orthogonal random features applied in OPRFs provide additional variance reduction for any dimensionality $d$ (not only asymptotically for sufficiently large $d$, as for RKS). We test CRTs on many tasks ranging from non-parametric classification to training Transformers for text, speech and image data, obtaining new state-of-the-art results for low-rank text Transformers, while providing linear space and time complexity.
Tracing Knowledge in Language Models Back to the Training Data
May 24, 2022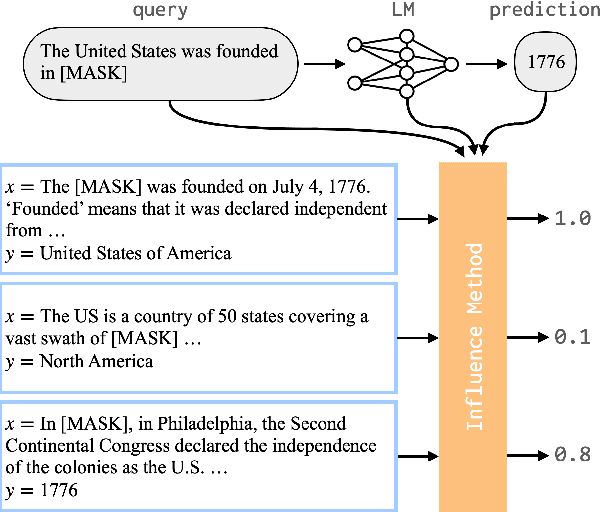
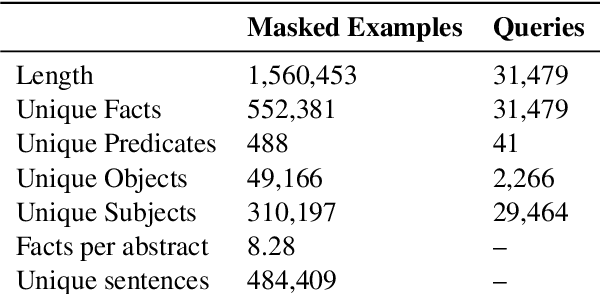
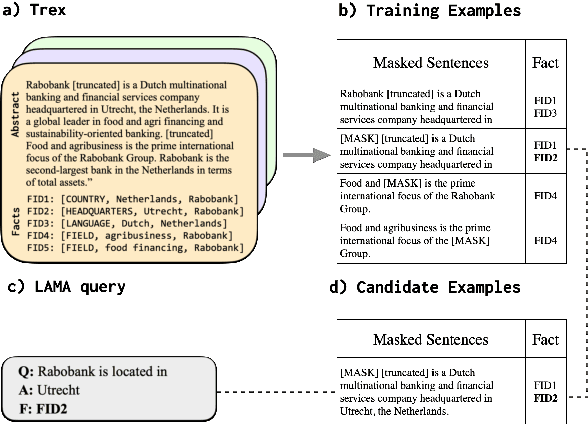
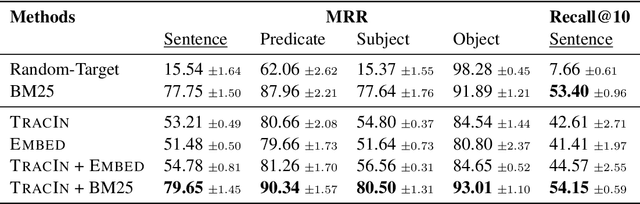
Neural language models (LMs) have been shown to memorize a great deal of factual knowledge. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we introduce a new benchmark for fact tracing: tracing language models' assertions back to the training examples that provided evidence for those predictions. Prior work has suggested that dataset-level influence methods might offer an effective framework for tracing predictions back to training data. However, such methods have not been evaluated for fact tracing, and researchers primarily have studied them through qualitative analysis or as a data cleaning technique for classification/regression tasks. We present the first experiments that evaluate influence methods for fact tracing, using well-understood information retrieval (IR) metrics. We compare two popular families of influence methods -- gradient-based and embedding-based -- and show that neither can fact-trace reliably; indeed, both methods fail to outperform an IR baseline (BM25) that does not even access the LM. We explore why this occurs (e.g., gradient saturation) and demonstrate that existing influence methods must be improved significantly before they can reliably attribute factual predictions in LMs.
Threading the Needle of On and Off-Manifold Value Functions for Shapley Explanations
Feb 24, 2022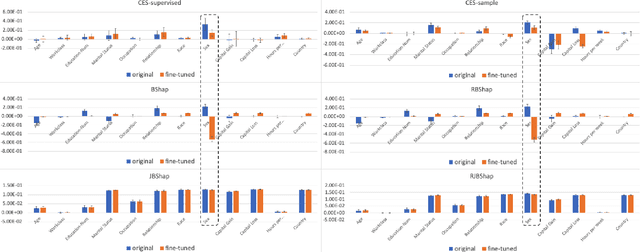

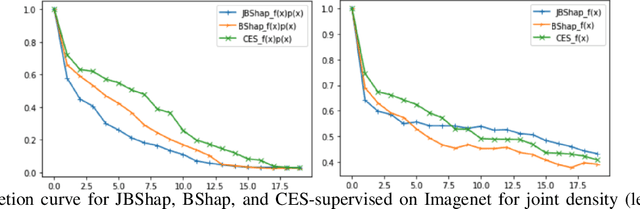
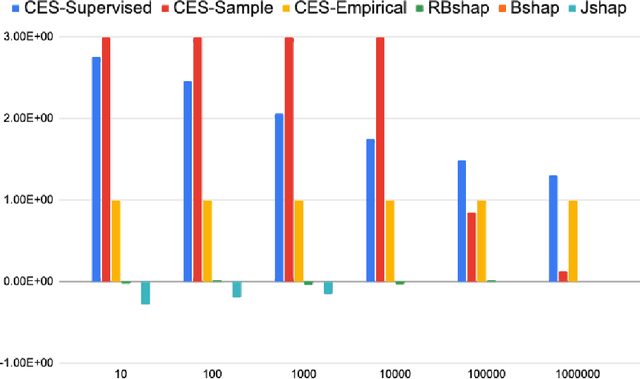
A popular explainable AI (XAI) approach to quantify feature importance of a given model is via Shapley values. These Shapley values arose in cooperative games, and hence a critical ingredient to compute these in an XAI context is a so-called value function, that computes the "value" of a subset of features, and which connects machine learning models to cooperative games. There are many possible choices for such value functions, which broadly fall into two categories: on-manifold and off-manifold value functions, which take an observational and an interventional viewpoint respectively. Both these classes however have their respective flaws, where on-manifold value functions violate key axiomatic properties and are computationally expensive, while off-manifold value functions pay less heed to the data manifold and evaluate the model on regions for which it wasn't trained. Thus, there is no consensus on which class of value functions to use. In this paper, we show that in addition to these existing issues, both classes of value functions are prone to adversarial manipulations on low density regions. We formalize the desiderata of value functions that respect both the model and the data manifold in a set of axioms and are robust to perturbation on off-manifold regions, and show that there exists a unique value function that satisfies these axioms, which we term the Joint Baseline value function, and the resulting Shapley value the Joint Baseline Shapley (JBshap), and validate the effectiveness of JBshap in experiments.
First is Better Than Last for Training Data Influence
Feb 24, 2022
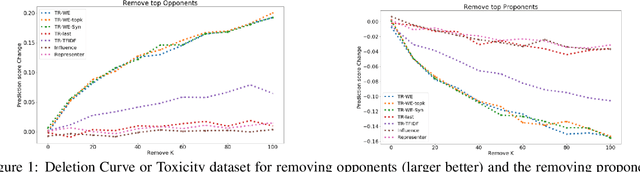

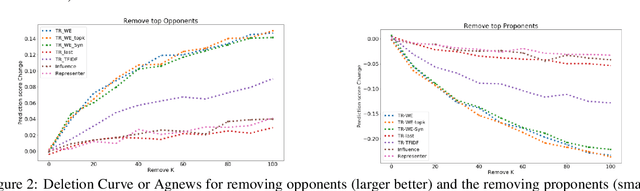
The ability to identify influential training examples enables us to debug training data and explain model behavior. Existing techniques are based on the flow of influence through the model parameters. For large models in NLP applications, it is often computationally infeasible to study this flow through all model parameters, therefore techniques usually pick the last layer of weights. Our first observation is that for classification problems, the last layer is reductive and does not encode sufficient input level information. Deleting influential examples, according to this measure, typically does not change the model's behavior much. We propose a technique called TracIn-WE that modifies a method called TracIn to operate on the word embedding layer instead of the last layer. This could potentially have the opposite concern, that the word embedding layer does not encode sufficient high level information. However, we find that gradients (unlike embeddings) do not suffer from this, possibly because they chain through higher layers. We show that TracIn-WE significantly outperforms other data influence methods applied on the last layer by 4-10 times on the case deletion evaluation on three language classification tasks. In addition, TracIn-WE can produce scores not just at the training data level, but at the word training data level, a further aid in debugging.
EncT5: Fine-tuning T5 Encoder for Non-autoregressive Tasks
Oct 16, 2021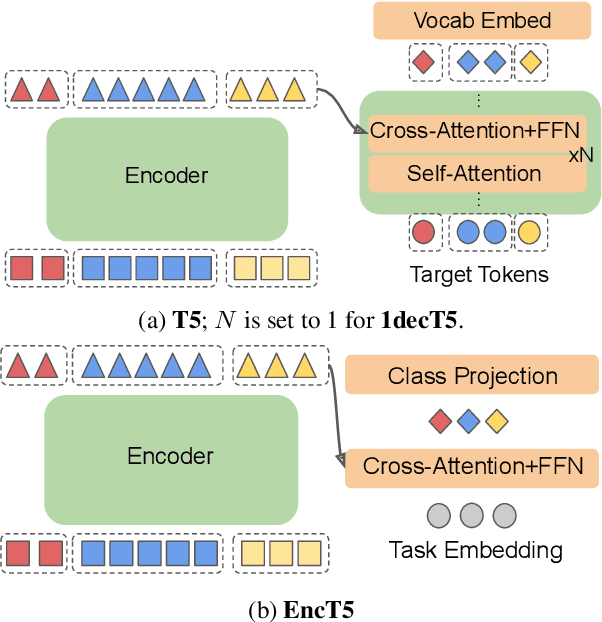
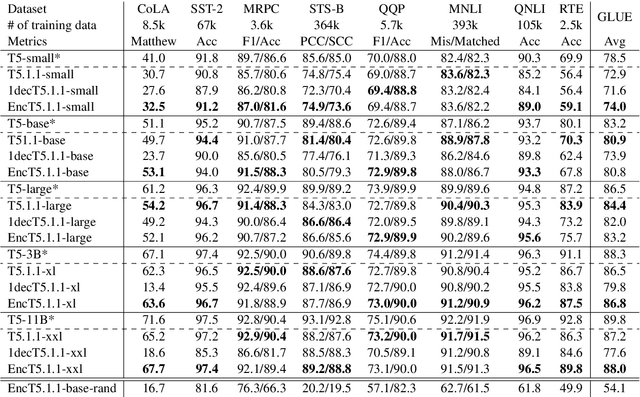
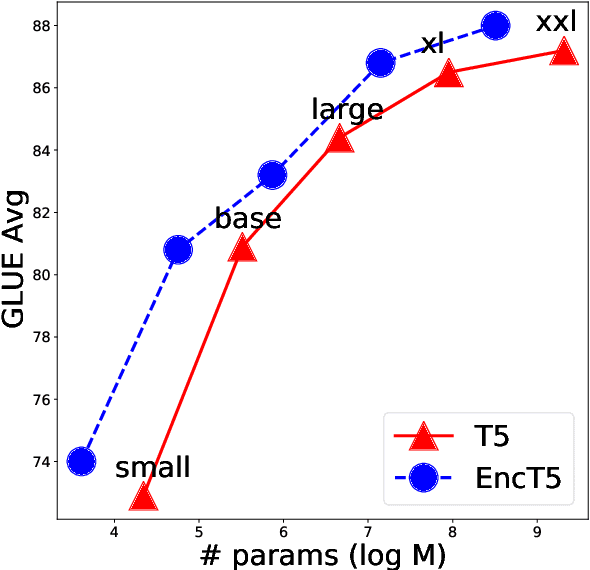
Encoder-decoder transformer architectures have become popular recently with the advent of T5 models. It is also more favorable over architectures like BERT for pre-training on language model task when it comes to large scale models which could take months to train given it's generality. While being able to generalize to more tasks, it is not evident if the proposed encoder-decoder architecture is the most efficient for fine-tuning on classification and regression tasks given the pre-trained model. In this work, we study fine-tuning pre-trained encoder-decoder models such as T5. Particularly, we propose \textbf{EncT5} as a way to efficiently fine-tune pre-trained encoder-decoder T5 models for classification and regression tasks by using the encoder layers. Our experimental results show that \textbf{EncT5} with less than half of the parameters of T5 performs similarly to T5 models on GLUE benchmark. We believe our proposed approach can be easily applied to any pre-trained encoder-decoder model.
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021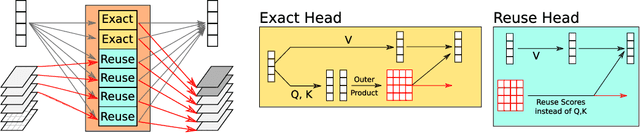
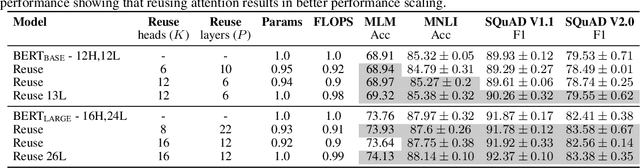
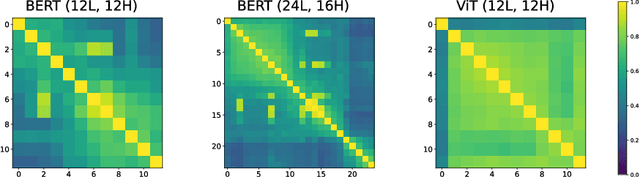
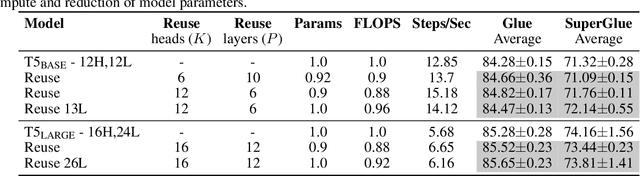
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles
Jun 29, 2021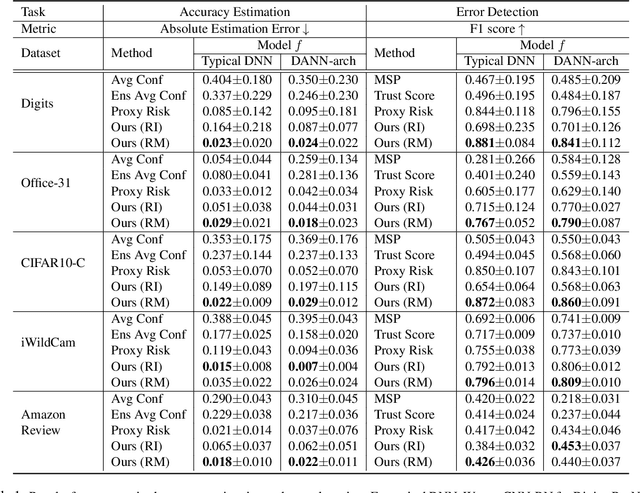
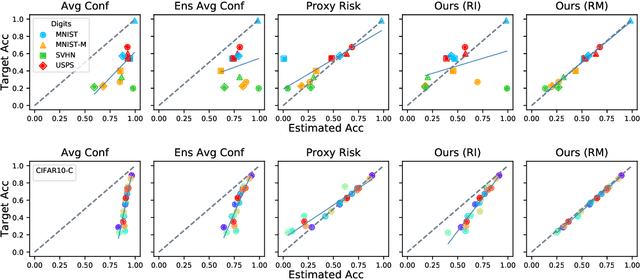
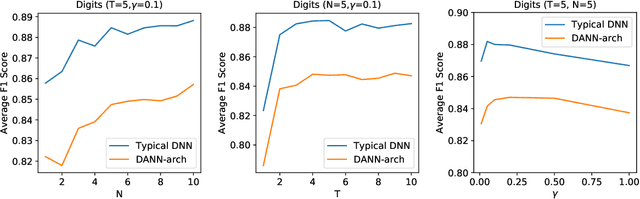
When a deep learning model is deployed in the wild, it can encounter test data drawn from distributions different from the training data distribution and suffer drop in performance. For safe deployment, it is essential to estimate the accuracy of the pre-trained model on the test data. However, the labels for the test inputs are usually not immediately available in practice, and obtaining them can be expensive. This observation leads to two challenging tasks: (1) unsupervised accuracy estimation, which aims to estimate the accuracy of a pre-trained classifier on a set of unlabeled test inputs; (2) error detection, which aims to identify mis-classified test inputs. In this paper, we propose a principled and practically effective framework that simultaneously addresses the two tasks. The proposed framework iteratively learns an ensemble of models to identify mis-classified data points and performs self-training to improve the ensemble with the identified points. Theoretical analysis demonstrates that our framework enjoys provable guarantees for both accuracy estimation and error detection under mild conditions readily satisfied by practical deep learning models. Along with the framework, we proposed and experimented with two instantiations and achieved state-of-the-art results on 59 tasks. For example, on iWildCam, one instantiation reduces the estimation error for unsupervised accuracy estimation by at least 70% and improves the F1 score for error detection by at least 4.7% compared to existing methods.
The Penalty Imposed by Ablated Data Augmentation
Jun 08, 2020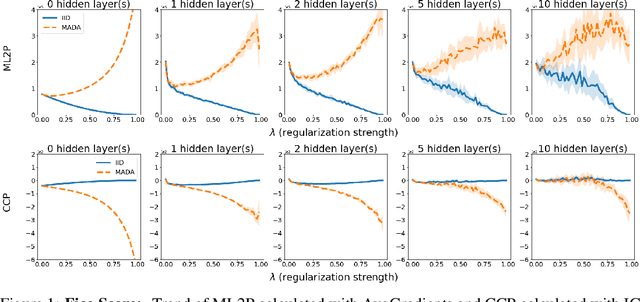
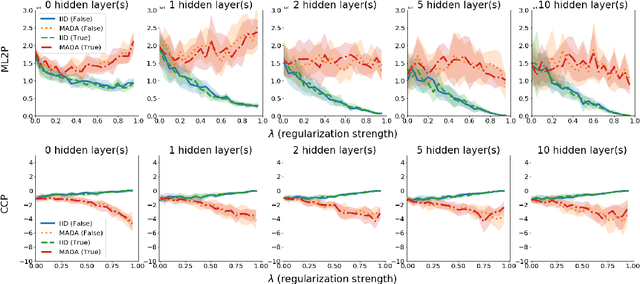
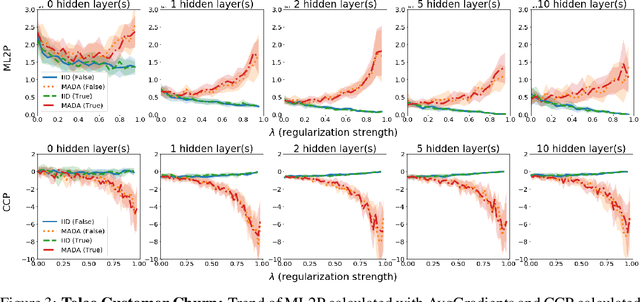
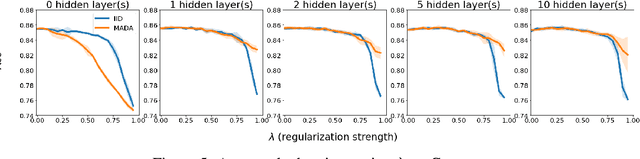
There is a set of data augmentation techniques that ablate parts of the input at random. These include input dropout, cutout, and random erasing. We term these techniques ablated data augmentation. Though these techniques seems similar in spirit and have shown success in improving model performance in a variety of domains, we do not yet have a mathematical understanding of the differences between these techniques like we do for other regularization techniques like L1 or L2. First, we study a formal model of mean ablated data augmentation and inverted dropout for linear regression. We prove that ablated data augmentation is equivalent to optimizing the ordinary least squares objective along with a penalty that we call the Contribution Covariance Penalty and inverted dropout, a more common implementation than dropout in popular frameworks, is equivalent to optimizing the ordinary least squares objective along with Modified L2. For deep networks, we demonstrate an empirical version of the result if we replace contributions with attributions and coefficients with average gradients, i.e., the Contribution Covariance Penalty and Modified L2 Penalty drop with the increase of the corresponding ablated data augmentation across a variety of networks.