 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
Feb 11, 2026Understanding how language model capabilities transfer from pretraining to supervised fine-tuning (SFT) is fundamental to efficient model development and data curation. In this work, we investigate four core questions: RQ1. To what extent do accuracy and confidence rankings established during pretraining persist after SFT? RQ2. Which benchmarks serve as robust cross-stage predictors and which are unreliable? RQ3. How do transfer dynamics shift with model scale? RQ4. How well does model confidence align with accuracy, as a measure of calibration quality? Does this alignment pattern transfer across training stages? We address these questions through a suite of correlation protocols applied to accuracy and confidence metrics across diverse data mixtures and model scales. Our experiments reveal that transfer reliability varies dramatically across capability categories, benchmarks, and scales -- with accuracy and confidence exhibiting distinct, sometimes opposing, scaling dynamics. These findings shed light on the complex interplay between pretraining decisions and downstream outcomes, providing actionable guidance for benchmark selection, data curation, and efficient model development.
Tracing Knowledge in Language Models Back to the Training Data
May 24, 2022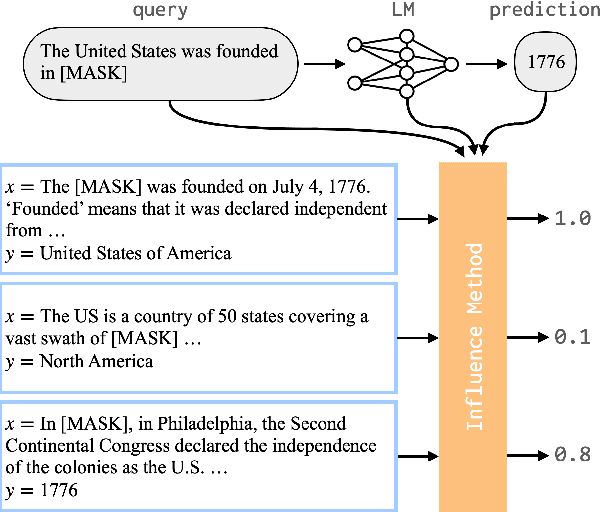
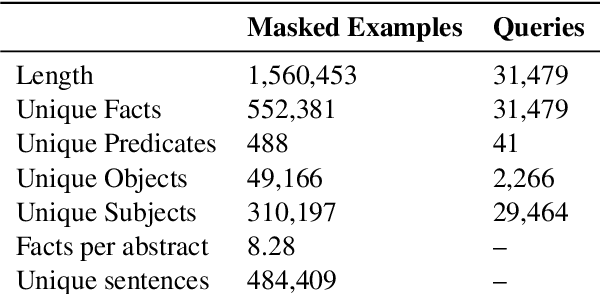
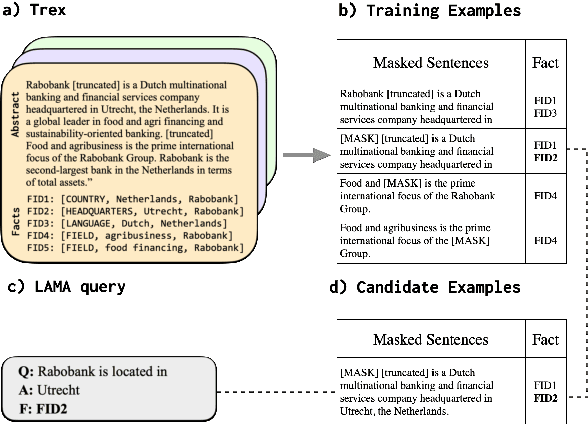
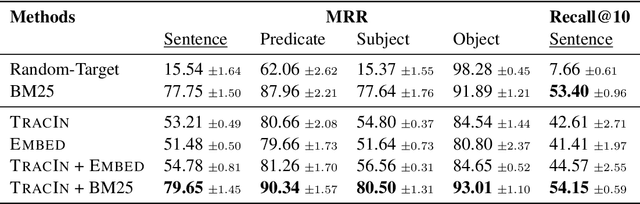
Neural language models (LMs) have been shown to memorize a great deal of factual knowledge. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we introduce a new benchmark for fact tracing: tracing language models' assertions back to the training examples that provided evidence for those predictions. Prior work has suggested that dataset-level influence methods might offer an effective framework for tracing predictions back to training data. However, such methods have not been evaluated for fact tracing, and researchers primarily have studied them through qualitative analysis or as a data cleaning technique for classification/regression tasks. We present the first experiments that evaluate influence methods for fact tracing, using well-understood information retrieval (IR) metrics. We compare two popular families of influence methods -- gradient-based and embedding-based -- and show that neither can fact-trace reliably; indeed, both methods fail to outperform an IR baseline (BM25) that does not even access the LM. We explore why this occurs (e.g., gradient saturation) and demonstrate that existing influence methods must be improved significantly before they can reliably attribute factual predictions in LMs.