 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Attention-Based Models with Augmented Memory for End-to-End Speech Recognition
Nov 03, 2020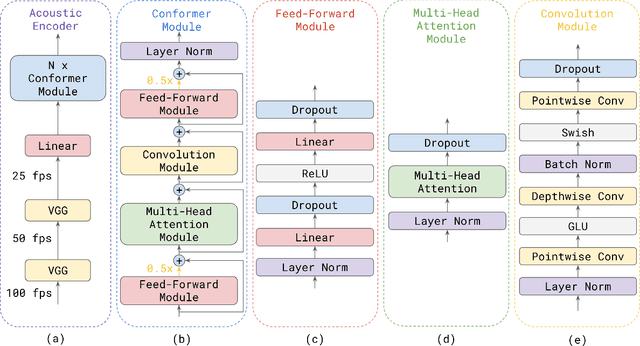
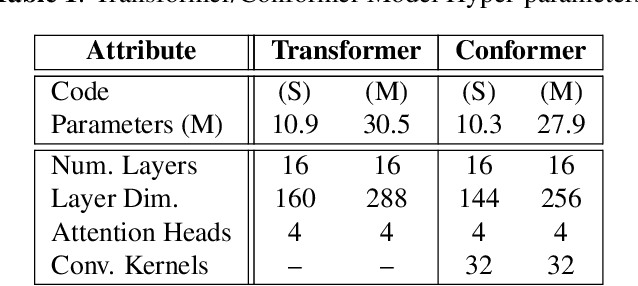
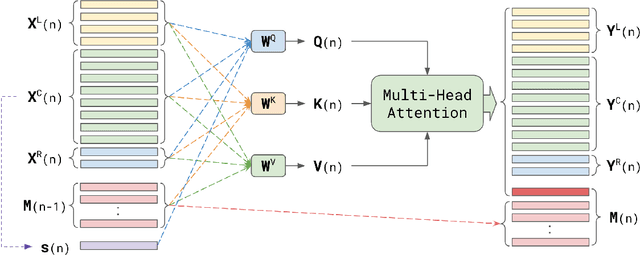
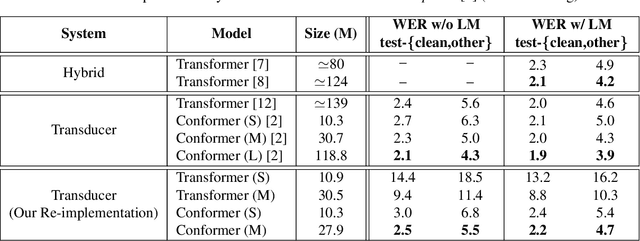
Attention-based models have been gaining popularity recently for their strong performance demonstrated in fields such as machine translation and automatic speech recognition. One major challenge of attention-based models is the need of access to the full sequence and the quadratically growing computational cost concerning the sequence length. These characteristics pose challenges, especially for low-latency scenarios, where the system is often required to be streaming. In this paper, we build a compact and streaming speech recognition system on top of the end-to-end neural transducer architecture with attention-based modules augmented with convolution. The proposed system equips the end-to-end models with the streaming capability and reduces the large footprint from the streaming attention-based model using augmented memory. On the LibriSpeech dataset, our proposed system achieves word error rates 2.7% on test-clean and 5.8% on test-other, to our best knowledge the lowest among streaming approaches reported so far.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020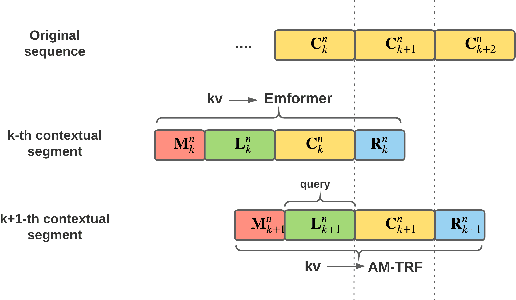
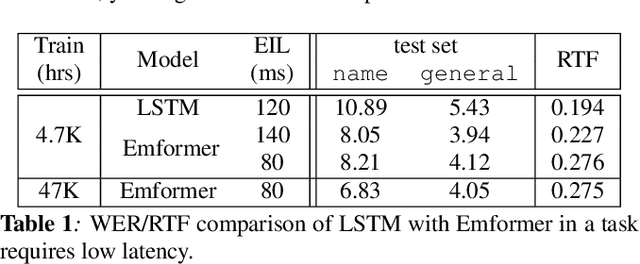
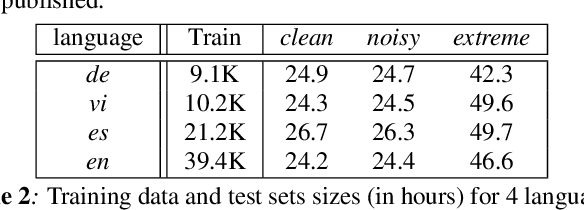
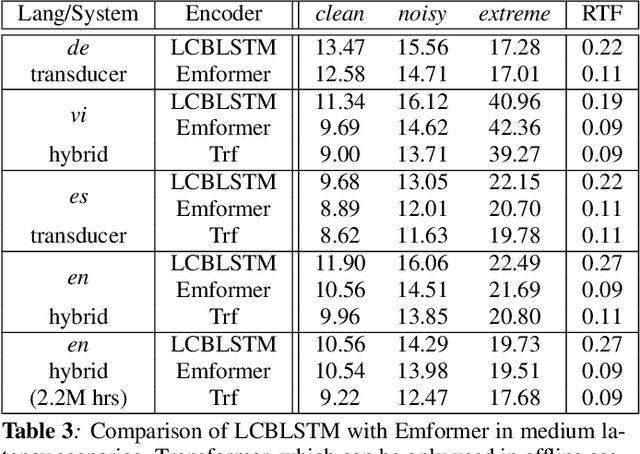
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Oct 29, 2020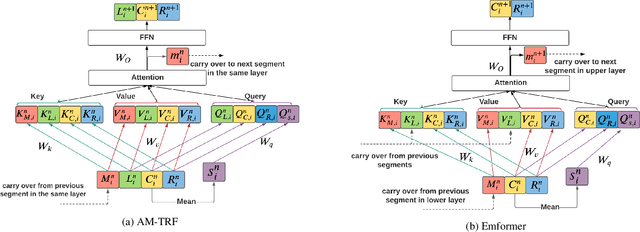
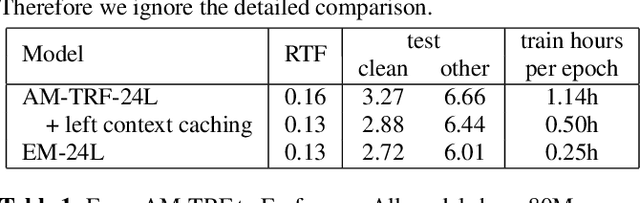
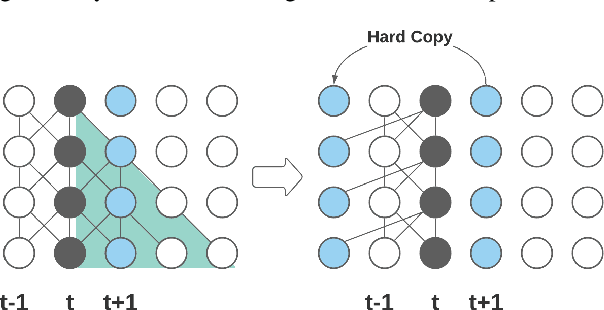
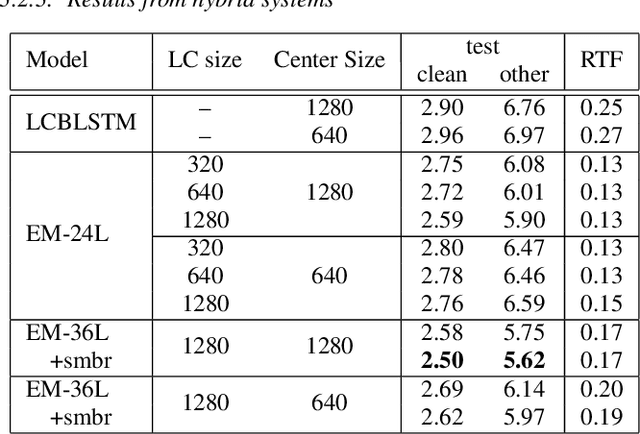
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.
Fast, Simpler and More Accurate Hybrid ASR Systems Using Wordpieces
May 19, 2020

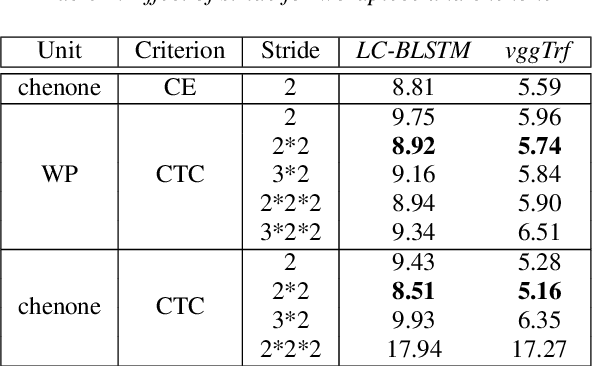
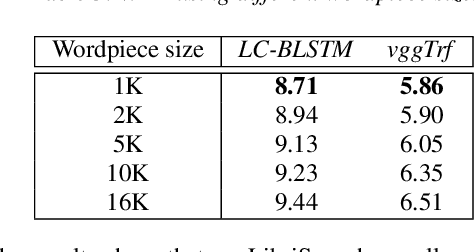
In this work, we first show that on the widely used LibriSpeech benchmark, our transformer-based context-dependent connectionist temporal classification (CTC) system produces state-of-the-art results. We then show that using wordpieces as modeling units combined with CTC training, we can greatly simplify the engineering pipeline compared to conventional frame-based cross-entropy training by excluding all the GMM bootstrapping, decision tree building and force alignment steps, while still achieving very competitive word-error-rate. Additionally, using wordpieces as modeling units can significantly improve runtime efficiency since we can use larger stride without losing accuracy. We further confirm these findings on two internal \emph{VideoASR} datasets: German, which is similar to English as a fusional language, and Turkish, which is an agglutinative language.
Weak-Attention Suppression For Transformer Based Speech Recognition
May 18, 2020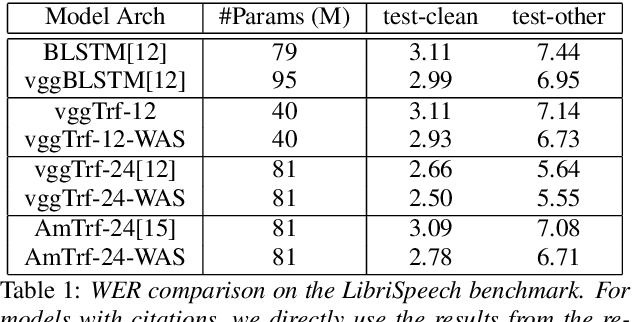
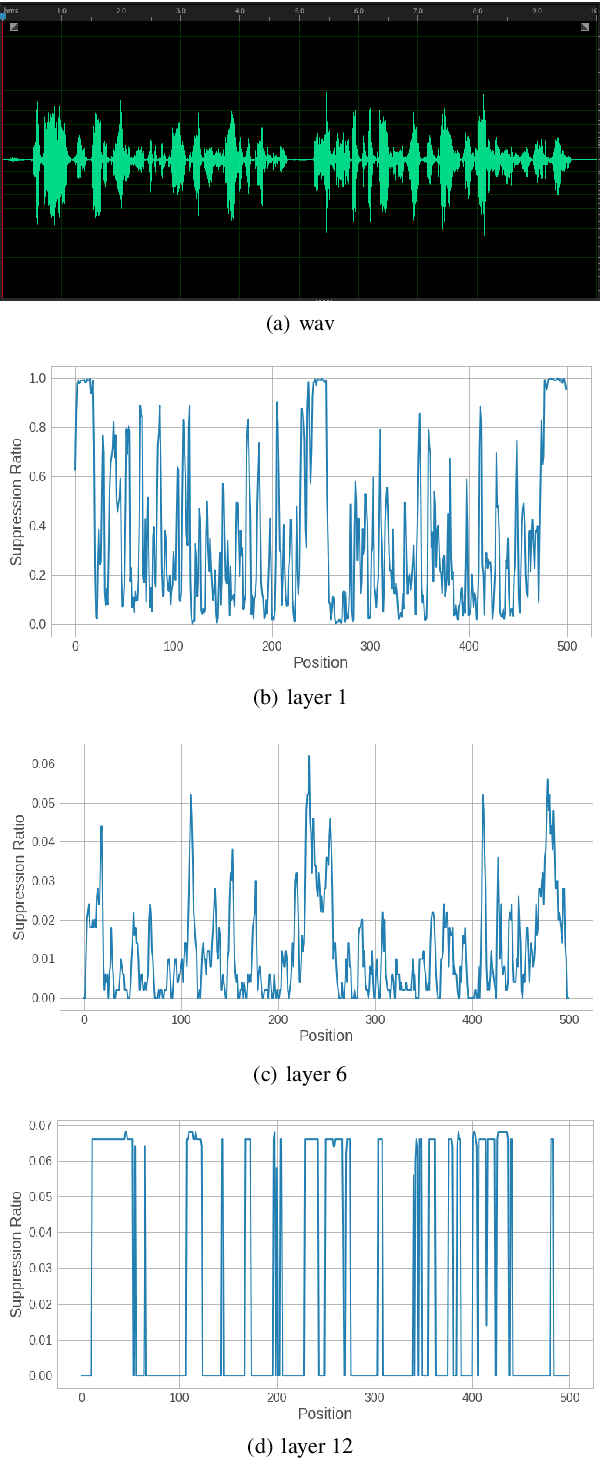
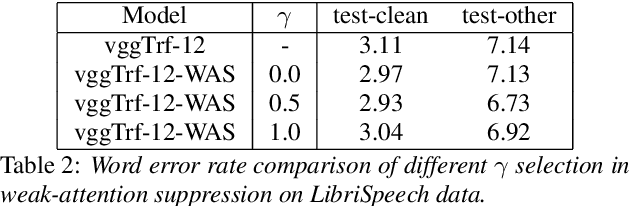
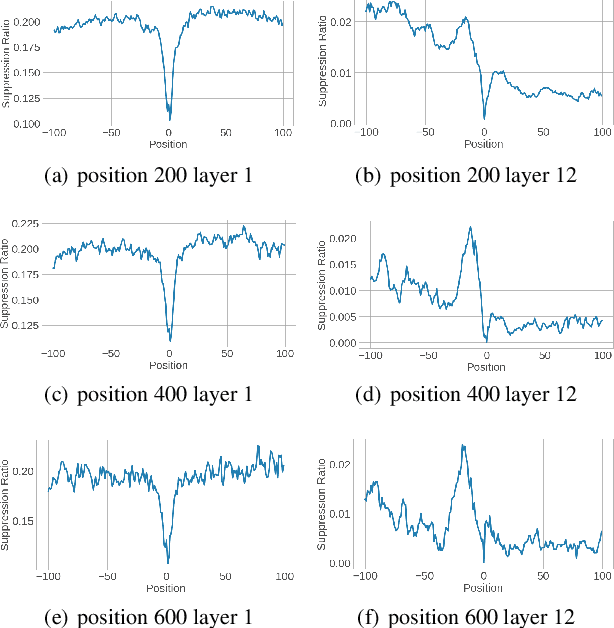
Transformers, originally proposed for natural language processing (NLP) tasks, have recently achieved great success in automatic speech recognition (ASR). However, adjacent acoustic units (i.e., frames) are highly correlated, and long-distance dependencies between them are weak, unlike text units. It suggests that ASR will likely benefit from sparse and localized attention. In this paper, we propose Weak-Attention Suppression (WAS), a method that dynamically induces sparsity in attention probabilities. We demonstrate that WAS leads to consistent Word Error Rate (WER) improvement over strong transformer baselines. On the widely used LibriSpeech benchmark, our proposed method reduced WER by 10%$ on test-clean and 5% on test-other for streamable transformers, resulting in a new state-of-the-art among streaming models. Further analysis shows that WAS learns to suppress attention of non-critical and redundant continuous acoustic frames, and is more likely to suppress past frames rather than future ones. It indicates the importance of lookahead in attention-based ASR models.
Streaming Transformer-based Acoustic Models Using Self-attention with Augmented Memory
May 16, 2020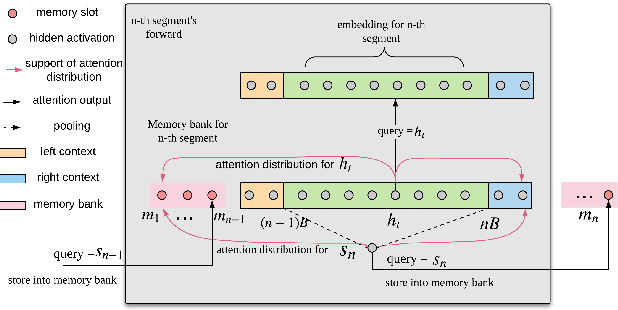
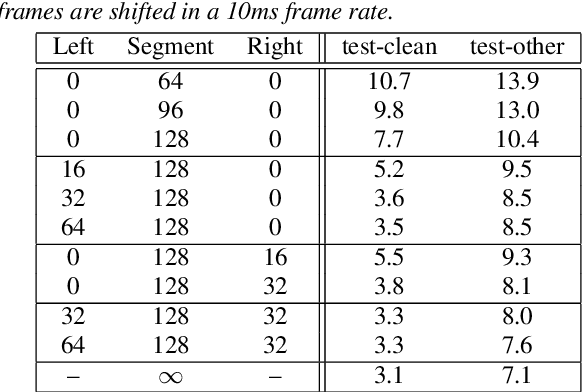
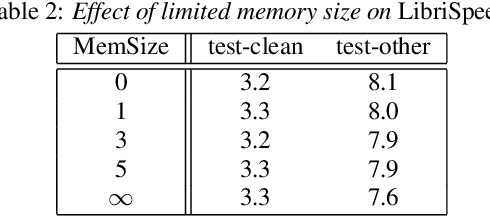
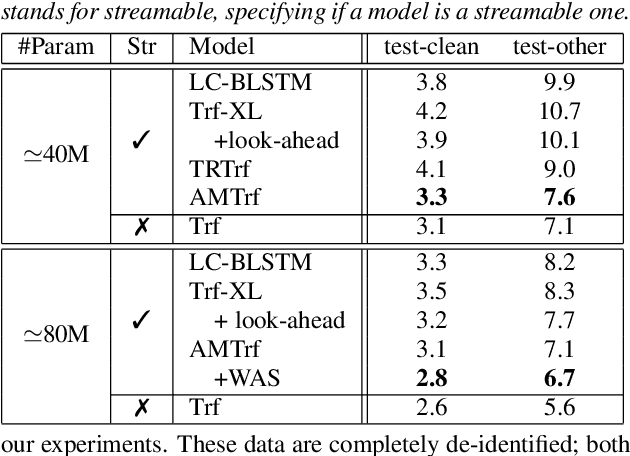
Transformer-based acoustic modeling has achieved great suc-cess for both hybrid and sequence-to-sequence speech recogni-tion. However, it requires access to the full sequence, and thecomputational cost grows quadratically with respect to the in-put sequence length. These factors limit its adoption for stream-ing applications. In this work, we proposed a novel augmentedmemory self-attention, which attends on a short segment of theinput sequence and a bank of memories. The memory bankstores the embedding information for all the processed seg-ments. On the librispeech benchmark, our proposed methodoutperforms all the existing streamable transformer methods bya large margin and achieved over 15% relative error reduction,compared with the widely used LC-BLSTM baseline. Our find-ings are also confirmed on some large internal datasets.
Contextualizing ASR Lattice Rescoring with Hybrid Pointer Network Language Model
May 15, 2020
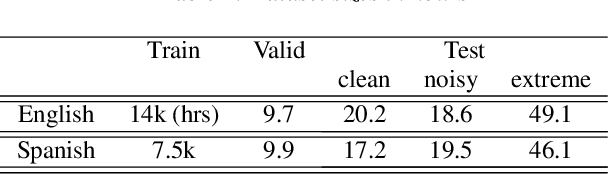
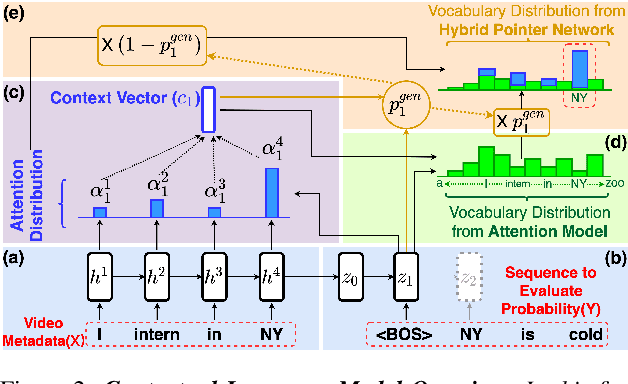
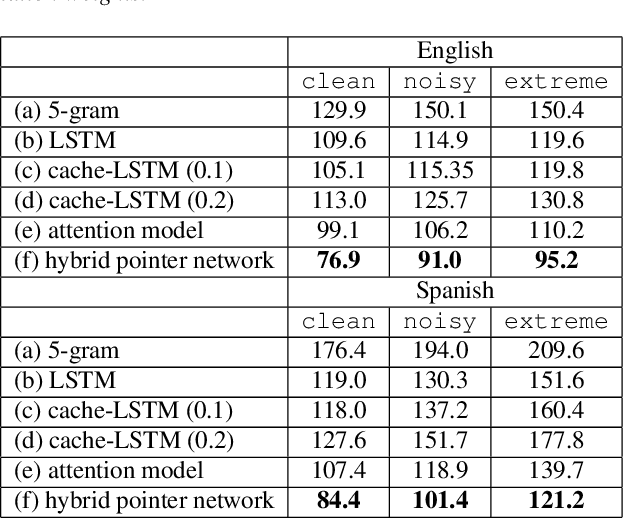
Videos uploaded on social media are often accompanied with textual descriptions. In building automatic speech recognition (ASR) systems for videos, we can exploit the contextual information provided by such video metadata. In this paper, we explore ASR lattice rescoring by selectively attending to the video descriptions. We first use an attention based method to extract contextual vector representations of video metadata, and use these representations as part of the inputs to a neural language model during lattice rescoring. Secondly, we propose a hybrid pointer network approach to explicitly interpolate the word probabilities of the word occurrences in metadata. We perform experimental evaluations on both language modeling and ASR tasks, and demonstrate that both proposed methods provide performance improvements by selectively leveraging the video metadata.
Training ASR models by Generation of Contextual Information
Oct 27, 2019
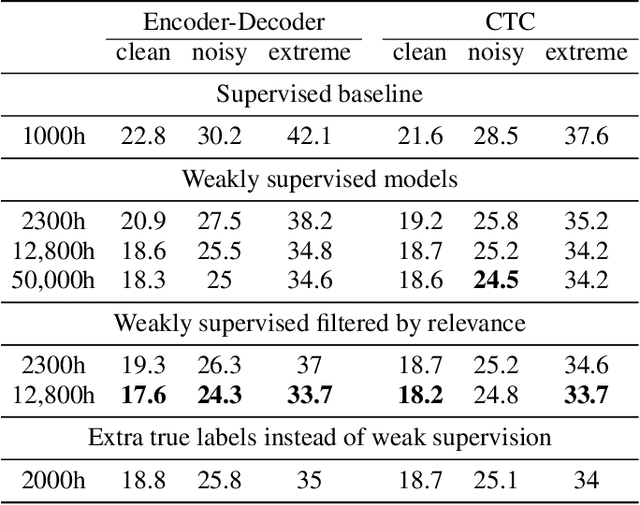
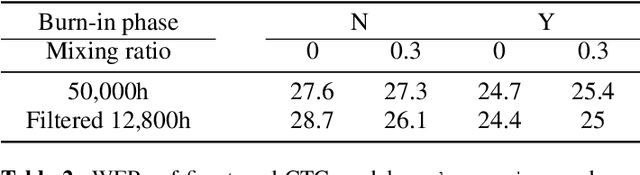

Supervised ASR models have reached unprecedented levels of accuracy, thanks in part to ever-increasing amounts of labelled training data. However, in many applications and locales, only moderate amounts of data are available, which has led to a surge in semi- and weakly-supervised learning research. In this paper, we conduct a large-scale study evaluating the effectiveness of weakly-supervised learning for speech recognition by using loosely related contextual information as a surrogate for ground-truth labels. For weakly supervised training, we use 50k hours of public English social media videos along with their respective titles and post text to train an encoder-decoder transformer model. Our best encoder-decoder models achieve an average of 20.8% WER reduction over a 1000 hours supervised baseline, and an average of 13.4% WER reduction when using only the weakly supervised encoder for CTC fine-tuning. Our results show that our setup for weak supervision improved both the encoder acoustic representations as well as the decoder language generation abilities.
Deja-vu: Double Feature Presentation in Deep Transformer Networks
Oct 23, 2019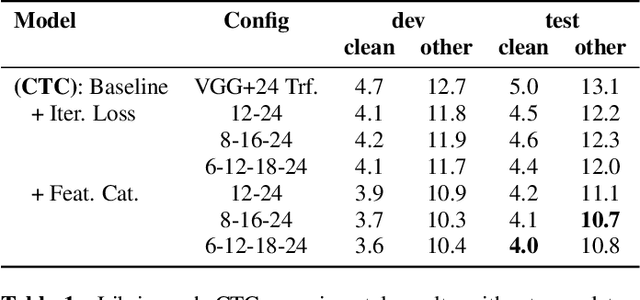
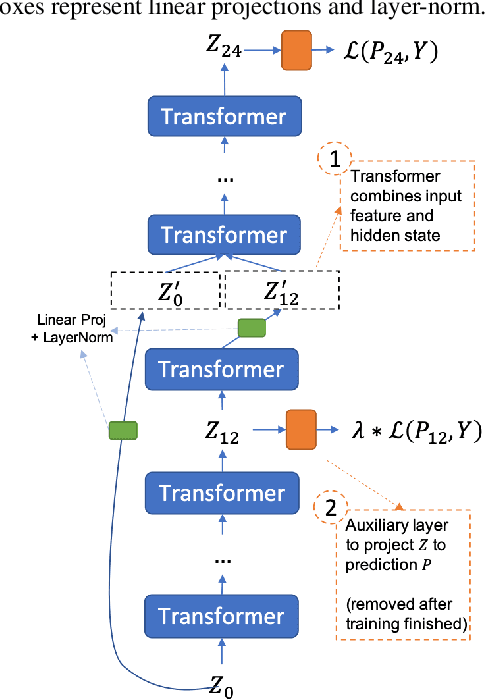
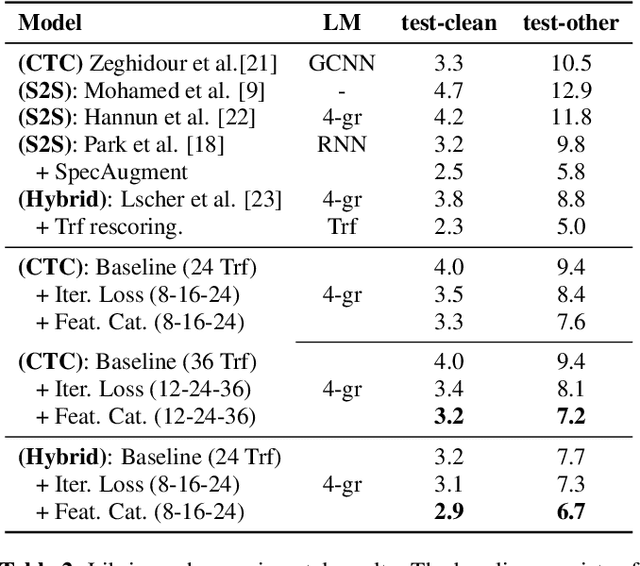
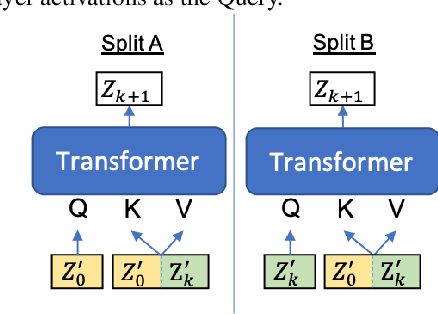
Deep acoustic models typically receive features in the first layer of the network, and process increasingly abstract representations in the subsequent layers. Here, we propose to feed the input features at multiple depths in the acoustic model. As our motivation is to allow acoustic models to re-examine their input features in light of partial hypotheses we introduce intermediate model heads and loss function. We study this architecture in the context of deep Transformer networks, and we use an attention mechanism over both the previous layer activations and the input features. To train this model's intermediate output hypothesis, we apply the objective function at each layer right before feature re-use. We find that the use of such intermediate losses significantly improves performance by itself, as well as enabling input feature re-use. We present results on both Librispeech, and a large scale video dataset, with relative improvements of 10 - 20% for Librispeech and 3.2 - 13% for videos.
Transformer-based Acoustic Modeling for Hybrid Speech Recognition
Oct 22, 2019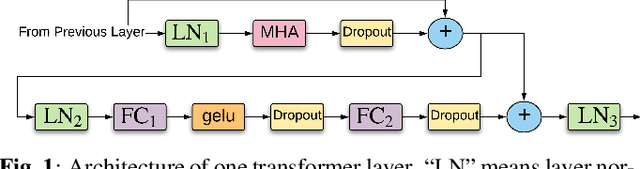
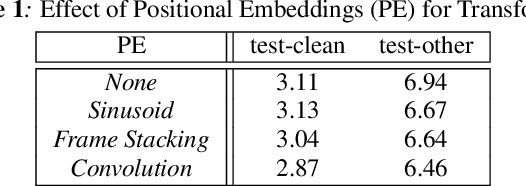
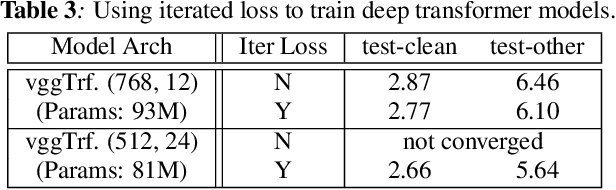
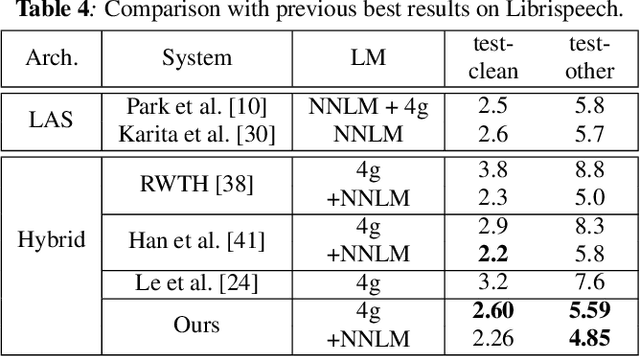
We propose and evaluate transformer-based acoustic models (AMs) for hybrid speech recognition. Several modeling choices are discussed in this work, including various positional embedding methods and an iterated loss to enable training deep transformers. We also present a preliminary study of using limited right context in transformer models, which makes it possible for streaming applications. We demonstrate that on the widely used Librispeech benchmark, our transformer-based AM outperforms the best published hybrid result by 19% to 26% relative when the standard n-gram language model (LM) is used. Combined with neural network LM for rescoring, our proposed approach achieves state-of-the-art results on Librispeech. Our findings are also confirmed on a much larger internal dataset.