 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic-to-Real Domain Bridging for Single-View 3D Reconstruction of Ships for Maritime Monitoring
Jan 29, 2026Three-dimensional (3D) reconstruction of ships is an important part of maritime monitoring, allowing improved visualization, inspection, and decision-making in real-world monitoring environments. However, most state-ofthe-art 3D reconstruction methods require multi-view supervision, annotated 3D ground truth, or are computationally intensive, making them impractical for real-time maritime deployment. In this work, we present an efficient pipeline for single-view 3D reconstruction of real ships by training entirely on synthetic data and requiring only a single view at inference. Our approach uses the Splatter Image network, which represents objects as sparse sets of 3D Gaussians for rapid and accurate reconstruction from single images. The model is first fine-tuned on synthetic ShapeNet vessels and further refined with a diverse custom dataset of 3D ships, bridging the domain gap between synthetic and real-world imagery. We integrate a state-of-the-art segmentation module based on YOLOv8 and custom preprocessing to ensure compatibility with the reconstruction network. Postprocessing steps include real-world scaling, centering, and orientation alignment, followed by georeferenced placement on an interactive web map using AIS metadata and homography-based mapping. Quantitative evaluation on synthetic validation data demonstrates strong reconstruction fidelity, while qualitative results on real maritime images from the ShipSG dataset confirm the potential for transfer to operational maritime settings. The final system provides interactive 3D inspection of real ships without requiring real-world 3D annotations. This pipeline provides an efficient, scalable solution for maritime monitoring and highlights a path toward real-time 3D ship visualization in practical applications. Interactive demo: https://dlr-mi.github.io/ship3d-demo/.
Automatic occlusion removal from 3D maps for maritime situational awareness
Sep 05, 2024We introduce a novel method for updating 3D geospatial models, specifically targeting occlusion removal in large-scale maritime environments. Traditional 3D reconstruction techniques often face problems with dynamic objects, like cars or vessels, that obscure the true environment, leading to inaccurate models or requiring extensive manual editing. Our approach leverages deep learning techniques, including instance segmentation and generative inpainting, to directly modify both the texture and geometry of 3D meshes without the need for costly reprocessing. By selectively targeting occluding objects and preserving static elements, the method enhances both geometric and visual accuracy. This approach not only preserves structural and textural details of map data but also maintains compatibility with current geospatial standards, ensuring robust performance across diverse datasets. The results demonstrate significant improvements in 3D model fidelity, making this method highly applicable for maritime situational awareness and the dynamic display of auxiliary information.
UTrack: Multi-Object Tracking with Uncertain Detections
Aug 30, 2024



The tracking-by-detection paradigm is the mainstream in multi-object tracking, associating tracks to the predictions of an object detector. Although exhibiting uncertainty through a confidence score, these predictions do not capture the entire variability of the inference process. For safety and security critical applications like autonomous driving, surveillance, etc., knowing this predictive uncertainty is essential though. Therefore, we introduce, for the first time, a fast way to obtain the empirical predictive distribution during object detection and incorporate that knowledge in multi-object tracking. Our mechanism can easily be integrated into state-of-the-art trackers, enabling them to fully exploit the uncertainty in the detections. Additionally, novel association methods are introduced that leverage the proposed mechanism. We demonstrate the effectiveness of our contribution on a variety of benchmarks, such as MOT17, MOT20, DanceTrack, and KITTI.
The 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
Deep learning-based denoising streamed from mobile phones improves speech-in-noise understanding for hearing aid users
Aug 22, 2023



The hearing loss of almost half a billion people is commonly treated with hearing aids. However, current hearing aids often do not work well in real-world noisy environments. We present a deep learning based denoising system that runs in real time on iPhone 7 and Samsung Galaxy S10 (25ms algorithmic latency). The denoised audio is streamed to the hearing aid, resulting in a total delay of around 75ms. In tests with hearing aid users having moderate to severe hearing loss, our denoising system improves audio across three tests: 1) listening for subjective audio ratings, 2) listening for objective speech intelligibility, and 3) live conversations in a noisy environment for subjective ratings. Subjective ratings increase by more than 40%, for both the listening test and the live conversation compared to a fitted hearing aid as a baseline. Speech reception thresholds, measuring speech understanding in noise, improve by 1.6 dB SRT. Ours is the first denoising system that is implemented on a mobile device, streamed directly to users' hearing aids using only a single channel as audio input while improving user satisfaction on all tested aspects, including speech intelligibility. This includes overall preference of the denoised and streamed signal over the hearing aid, thereby accepting the higher latency for the significant improvement in speech understanding.
Reward-Based 1-bit Compressed Federated Distillation on Blockchain
Jun 27, 2021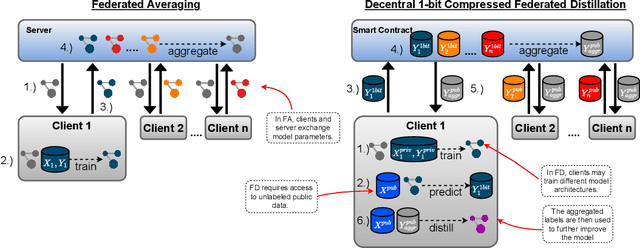
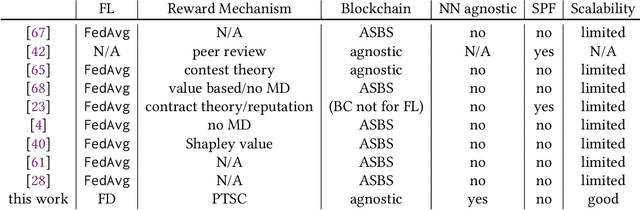

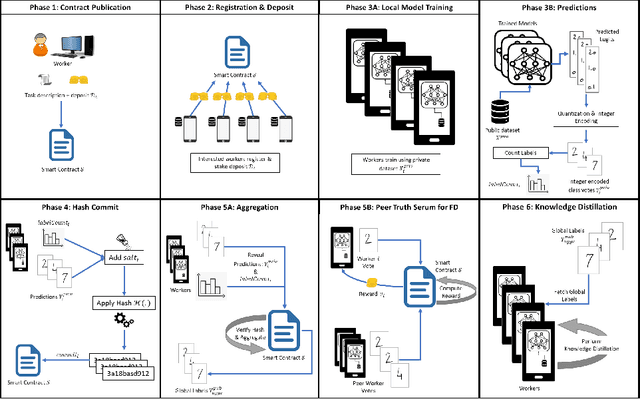
The recent advent of various forms of Federated Knowledge Distillation (FD) paves the way for a new generation of robust and communication-efficient Federated Learning (FL), where mere soft-labels are aggregated, rather than whole gradients of Deep Neural Networks (DNN) as done in previous FL schemes. This security-per-design approach in combination with increasingly performant Internet of Things (IoT) and mobile devices opens up a new realm of possibilities to utilize private data from industries as well as from individuals as input for artificial intelligence model training. Yet in previous FL systems, lack of trust due to the imbalance of power between workers and a central authority, the assumption of altruistic worker participation and the inability to correctly measure and compare contributions of workers hinder this technology from scaling beyond small groups of already entrusted entities towards mass adoption. This work aims to mitigate the aforementioned issues by introducing a novel decentralized federated learning framework where heavily compressed 1-bit soft-labels, resembling 1-hot label predictions, are aggregated on a smart contract. In a context where workers' contributions are now easily comparable, we modify the Peer Truth Serum for Crowdsourcing mechanism (PTSC) for FD to reward honest participation based on peer consistency in an incentive compatible fashion. Due to heavy reductions of both computational complexity and storage, our framework is a fully on-blockchain FL system that is feasible on simple smart contracts and therefore blockchain agnostic. We experimentally test our new framework and validate its theoretical properties.
FedAUX: Leveraging Unlabeled Auxiliary Data in Federated Learning
Feb 04, 2021



Federated Distillation (FD) is a popular novel algorithmic paradigm for Federated Learning, which achieves training performance competitive to prior parameter averaging based methods, while additionally allowing the clients to train different model architectures, by distilling the client predictions on an unlabeled auxiliary set of data into a student model. In this work we propose FedAUX, an extension to FD, which, under the same set of assumptions, drastically improves performance by deriving maximum utility from the unlabeled auxiliary data. FedAUX modifies the FD training procedure in two ways: First, unsupervised pre-training on the auxiliary data is performed to find a model initialization for the distributed training. Second, $(\varepsilon, \delta)$-differentially private certainty scoring is used to weight the ensemble predictions on the auxiliary data according to the certainty of each client model. Experiments on large-scale convolutional neural networks and transformer models demonstrate, that the training performance of FedAUX exceeds SOTA FL baseline methods by a substantial margin in both the iid and non-iid regime, further closing the gap to centralized training performance. Code is available at github.com/fedl-repo/fedaux.
Communication-Efficient Federated Distillation
Dec 01, 2020Communication constraints are one of the major challenges preventing the wide-spread adoption of Federated Learning systems. Recently, Federated Distillation (FD), a new algorithmic paradigm for Federated Learning with fundamentally different communication properties, emerged. FD methods leverage ensemble distillation techniques and exchange model outputs, presented as soft labels on an unlabeled public data set, between the central server and the participating clients. While for conventional Federated Learning algorithms, like Federated Averaging (FA), communication scales with the size of the jointly trained model, in FD communication scales with the distillation data set size, resulting in advantageous communication properties, especially when large models are trained. In this work, we investigate FD from the perspective of communication efficiency by analyzing the effects of active distillation-data curation, soft-label quantization and delta-coding techniques. Based on the insights gathered from this analysis, we present Compressed Federated Distillation (CFD), an efficient Federated Distillation method. Extensive experiments on Federated image classification and language modeling problems demonstrate that our method can reduce the amount of communication necessary to achieve fixed performance targets by more than two orders of magnitude, when compared to FD and by more than four orders of magnitude when compared with FA.
Risk Estimation of SARS-CoV-2 Transmission from Bluetooth Low Energy Measurements
Apr 22, 2020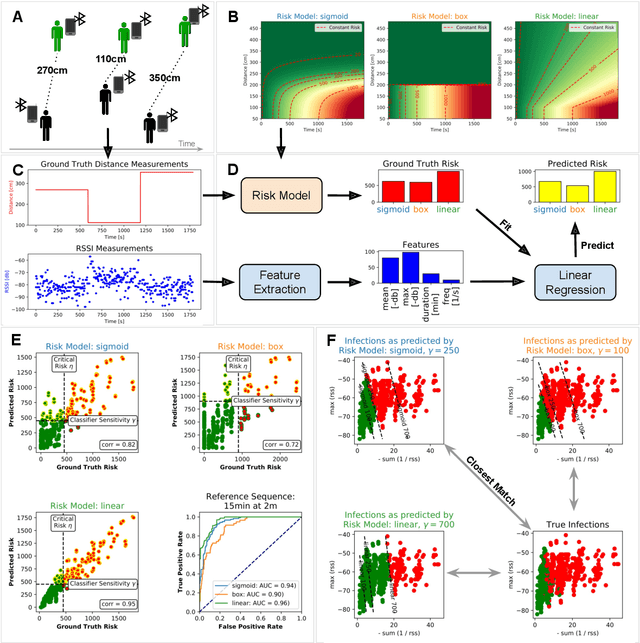
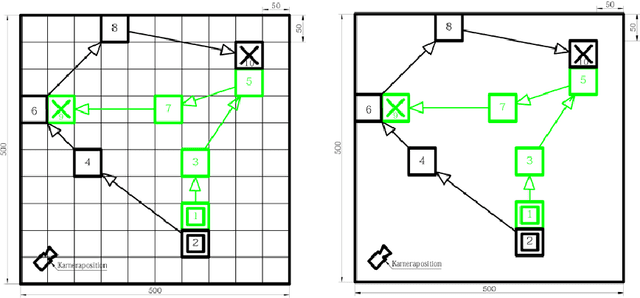
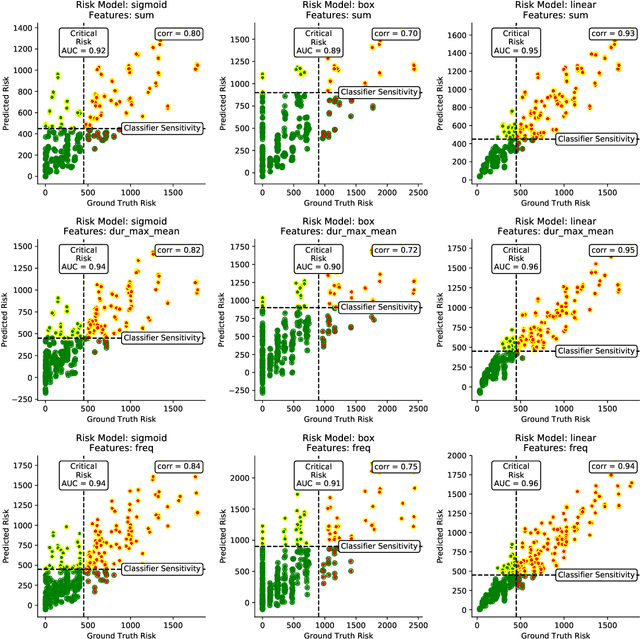
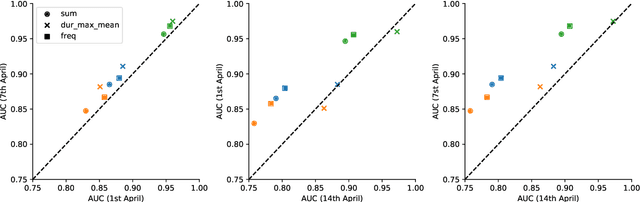
Digital contact tracing approaches based on Bluetooth low energy (BLE) have the potential to efficiently contain and delay outbreaks of infectious diseases such as the ongoing SARS-CoV-2 pandemic. In this work we propose a novel machine learning based approach to reliably detect subjects that have spent enough time in close proximity to be at risk of being infected. Our study is an important proof of concept that will aid the battery of epidemiological policies aiming to slow down the rapid spread of COVID-19.
Trends and Advancements in Deep Neural Network Communication
Mar 06, 2020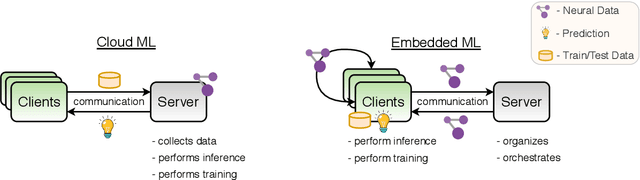
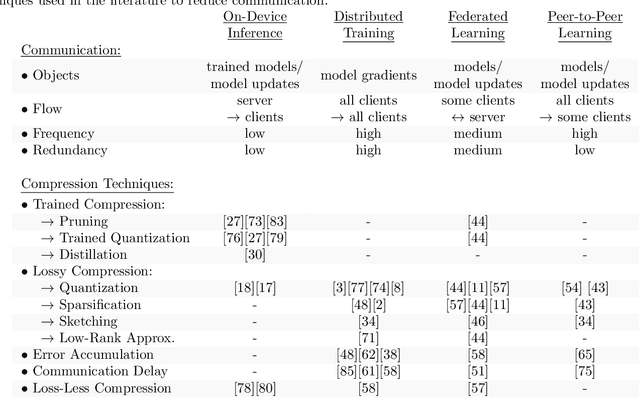
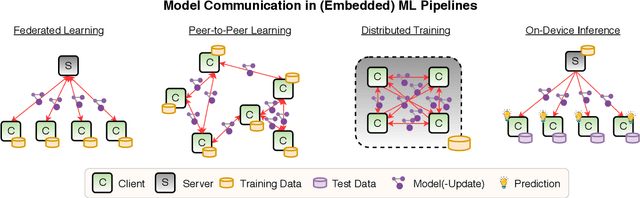
Due to their great performance and scalability properties neural networks have become ubiquitous building blocks of many applications. With the rise of mobile and IoT, these models now are also being increasingly applied in distributed settings, where the owners of the data are separated by limited communication channels and privacy constraints. To address the challenges of these distributed environments, a wide range of training and evaluation schemes have been developed, which require the communication of neural network parametrizations. These novel approaches, which bring the "intelligence to the data" have many advantages over traditional cloud solutions such as privacy-preservation, increased security and device autonomy, communication efficiency and high training speed. This paper gives an overview over the recent advancements and challenges in this new field of research at the intersection of machine learning and communications.