 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Few-Shot Learning with Frozen Language Models
Jul 03, 2021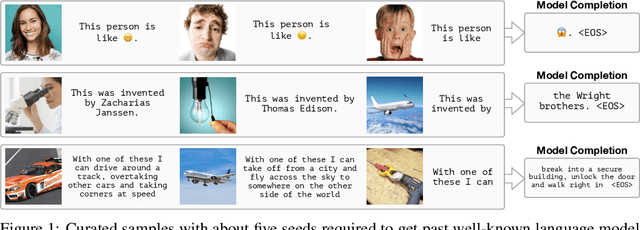
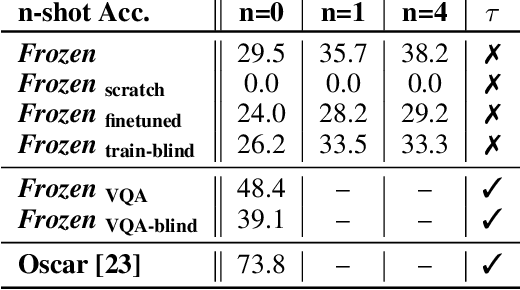
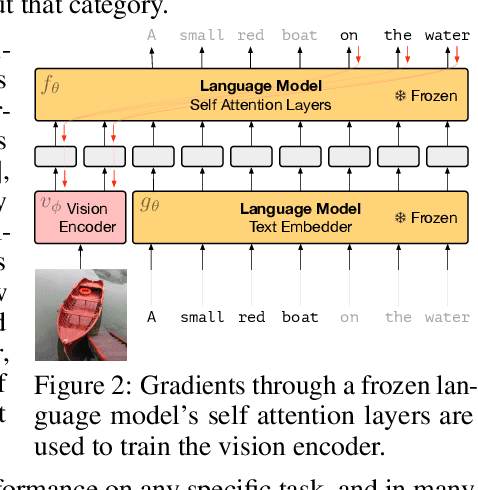
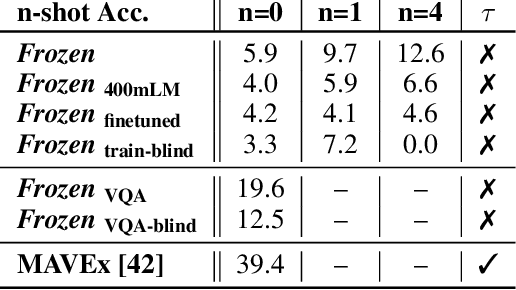
When trained at sufficient scale, auto-regressive language models exhibit the notable ability to learn a new language task after being prompted with just a few examples. Here, we present a simple, yet effective, approach for transferring this few-shot learning ability to a multimodal setting (vision and language). Using aligned image and caption data, we train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained, frozen language model prompted with this prefix generates the appropriate caption. The resulting system is a multimodal few-shot learner, with the surprising ability to learn a variety of new tasks when conditioned on examples, represented as a sequence of multiple interleaved image and text embeddings. We demonstrate that it can rapidly learn words for new objects and novel visual categories, do visual question-answering with only a handful of examples, and make use of outside knowledge, by measuring a single model on a variety of established and new benchmarks.
Towards mental time travel: a hierarchical memory for reinforcement learning agents
May 28, 2021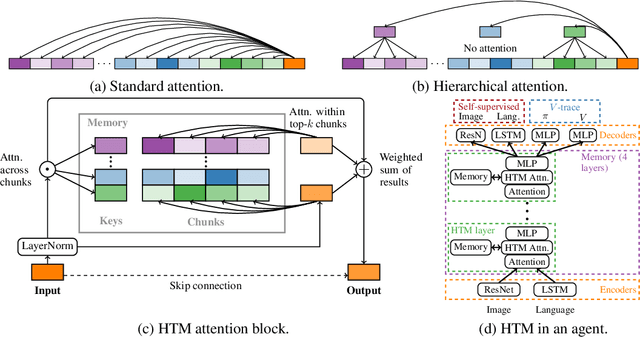
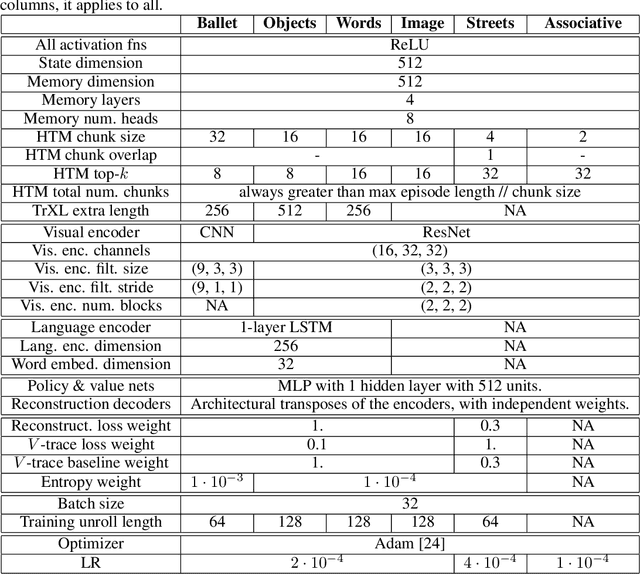
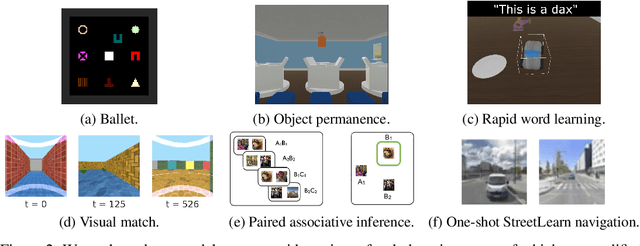

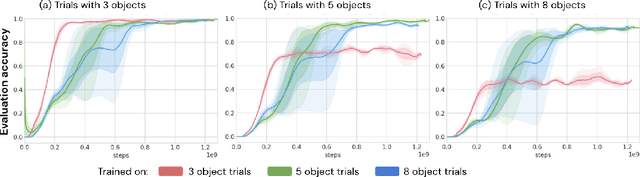
Reinforcement learning agents often forget details of the past, especially after delays or distractor tasks. Agents with common memory architectures struggle to recall and integrate across multiple timesteps of a past event, or even to recall the details of a single timestep that is followed by distractor tasks. To address these limitations, we propose a Hierarchical Transformer Memory (HTM), which helps agents to remember the past in detail. HTM stores memories by dividing the past into chunks, and recalls by first performing high-level attention over coarse summaries of the chunks, and then performing detailed attention within only the most relevant chunks. An agent with HTM can therefore "mentally time-travel" -- remember past events in detail without attending to all intervening events. We show that agents with HTM substantially outperform agents with other memory architectures at tasks requiring long-term recall, retention, or reasoning over memory. These include recalling where an object is hidden in a 3D environment, rapidly learning to navigate efficiently in a new neighborhood, and rapidly learning and retaining new object names. Agents with HTM can extrapolate to task sequences an order of magnitude longer than they were trained on, and can even generalize zero-shot from a meta-learning setting to maintaining knowledge across episodes. HTM improves agent sample efficiency, generalization, and generality (by solving tasks that previously required specialized architectures). Our work is a step towards agents that can learn, interact, and adapt in complex and temporally-extended environments.
Imitating Interactive Intelligence
Jan 21, 2021
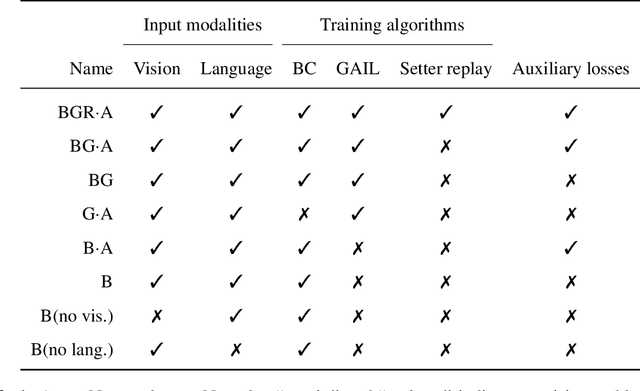
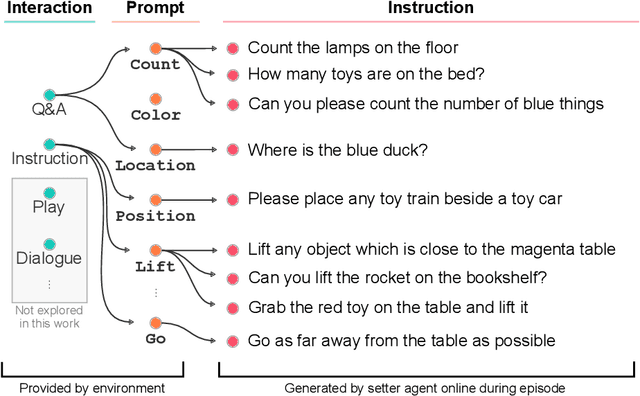
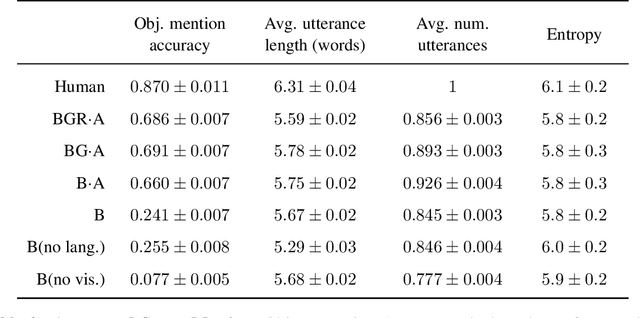
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.
Object-based attention for spatio-temporal reasoning: Outperforming neuro-symbolic models with flexible distributed architectures
Dec 15, 2020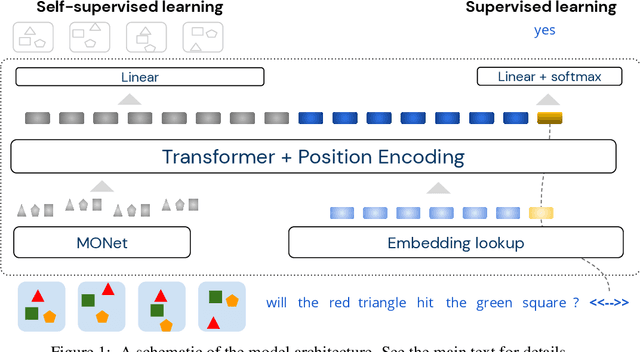
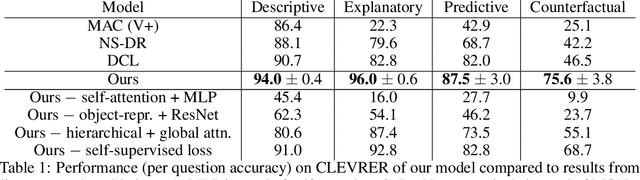
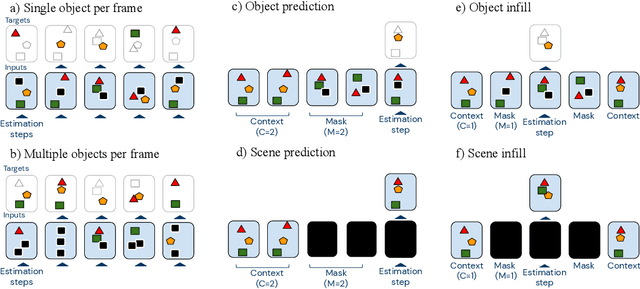
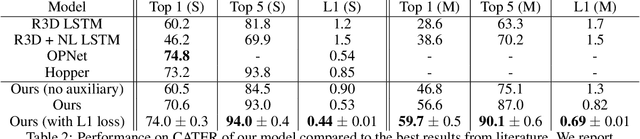
Neural networks have achieved success in a wide array of perceptual tasks, but it is often stated that they are incapable of solving tasks that require higher-level reasoning. Two new task domains, CLEVRER and CATER, have recently been developed to focus on reasoning, as opposed to perception, in the context of spatio-temporal interactions between objects. Initial experiments on these domains found that neuro-symbolic approaches, which couple a logic engine and language parser with a neural perceptual front-end, substantially outperform fully-learned distributed networks, a finding that was taken to support the above thesis. Here, we show on the contrary that a fully-learned neural network with the right inductive biases can perform substantially better than all previous neural-symbolic models on both of these tasks, particularly on questions that most emphasize reasoning over perception. Our model makes critical use of both self-attention and learned "soft" object-centric representations, as well as BERT-style semi-supervised predictive losses. These flexible biases allow our model to surpass the previous neuro-symbolic state-of-the-art using less than 60% of available labelled data. Together, these results refute the neuro-symbolic thesis laid out by previous work involving these datasets, and they provide evidence that neural networks can indeed learn to reason effectively about the causal, dynamic structure of physical events.
Grounded Language Learning Fast and Slow
Sep 15, 2020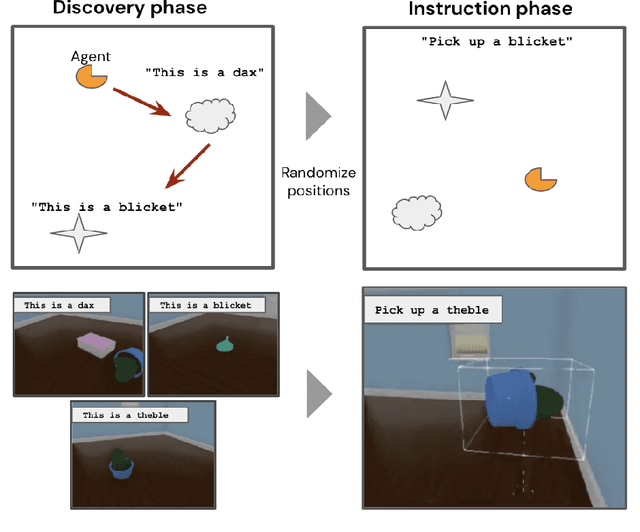
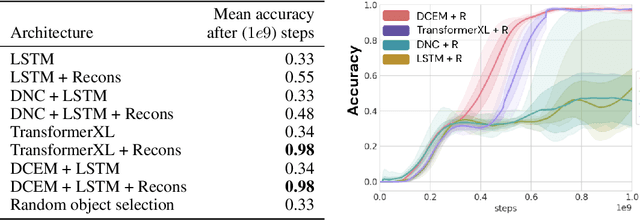
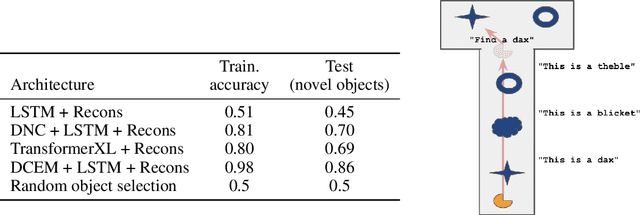
Recent work has shown that large text-based neural language models, trained with conventional supervised learning objectives, acquire a surprising propensity for few- and one-shot learning. Here, we show that an embodied agent situated in a simulated 3D world, and endowed with a novel dual-coding external memory, can exhibit similar one-shot word learning when trained with conventional reinforcement learning algorithms. After a single introduction to a novel object via continuous visual perception and a language prompt ("This is a dax"), the agent can re-identify the object and manipulate it as instructed ("Put the dax on the bed"). In doing so, it seamlessly integrates short-term, within-episode knowledge of the appropriate referent for the word "dax" with long-term lexical and motor knowledge acquired across episodes (i.e. "bed" and "putting"). We find that, under certain training conditions and with a particular memory writing mechanism, the agent's one-shot word-object binding generalizes to novel exemplars within the same ShapeNet category, and is effective in settings with unfamiliar numbers of objects. We further show how dual-coding memory can be exploited as a signal for intrinsic motivation, stimulating the agent to seek names for objects that may be useful for later executing instructions. Together, the results demonstrate that deep neural networks can exploit meta-learning, episodic memory and an explicitly multi-modal environment to account for 'fast-mapping', a fundamental pillar of human cognitive development and a potentially transformative capacity for agents that interact with human users.
Probing Emergent Semantics in Predictive Agents via Question Answering
Jun 01, 2020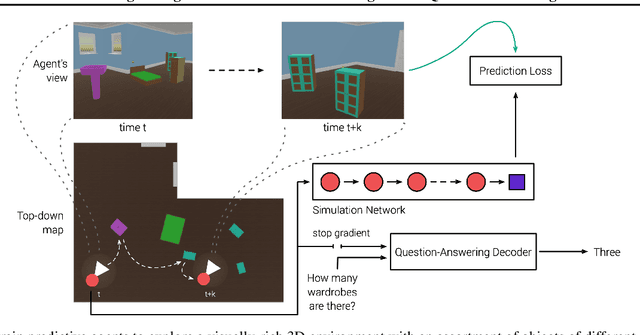

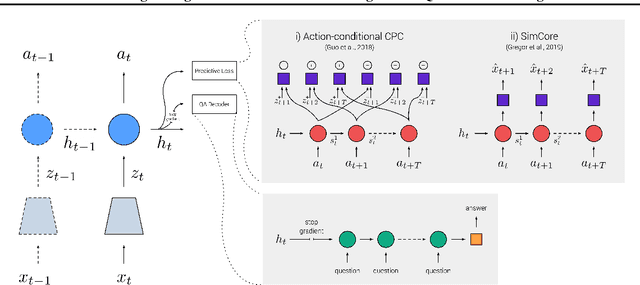
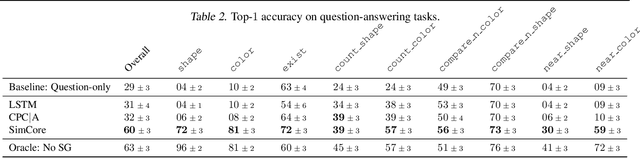
Recent work has shown how predictive modeling can endow agents with rich knowledge of their surroundings, improving their ability to act in complex environments. We propose question-answering as a general paradigm to decode and understand the representations that such agents develop, applying our method to two recent approaches to predictive modeling -action-conditional CPC (Guo et al., 2018) and SimCore (Gregor et al., 2019). After training agents with these predictive objectives in a visually-rich, 3D environment with an assortment of objects, colors, shapes, and spatial configurations, we probe their internal state representations with synthetic (English) questions, without backpropagating gradients from the question-answering decoder into the agent. The performance of different agents when probed this way reveals that they learn to encode factual, and seemingly compositional, information about objects, properties and spatial relations from their physical environment. Our approach is intuitive, i.e. humans can easily interpret responses of the model as opposed to inspecting continuous vectors, and model-agnostic, i.e. applicable to any modeling approach. By revealing the implicit knowledge of objects, quantities, properties and relations acquired by agents as they learn, question-conditional agent probing can stimulate the design and development of stronger predictive learning objectives.
Human Instruction-Following with Deep Reinforcement Learning via Transfer-Learning from Text
May 19, 2020
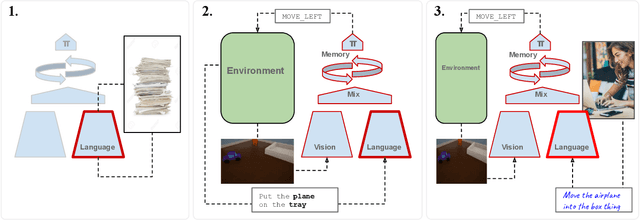
Recent work has described neural-network-based agents that are trained with reinforcement learning (RL) to execute language-like commands in simulated worlds, as a step towards an intelligent agent or robot that can be instructed by human users. However, the optimisation of multi-goal motor policies via deep RL from scratch requires many episodes of experience. Consequently, instruction-following with deep RL typically involves language generated from templates (by an environment simulator), which does not reflect the varied or ambiguous expressions of real users. Here, we propose a conceptually simple method for training instruction-following agents with deep RL that are robust to natural human instructions. By applying our method with a state-of-the-art pre-trained text-based language model (BERT), on tasks requiring agents to identify and position everyday objects relative to other objects in a naturalistic 3D simulated room, we demonstrate substantially-above-chance zero-shot transfer from synthetic template commands to natural instructions given by humans. Our approach is a general recipe for training any deep RL-based system to interface with human users, and bridges the gap between two research directions of notable recent success: agent-centric motor behavior and text-based representation learning.
Extending Machine Language Models toward Human-Level Language Understanding
Dec 12, 2019
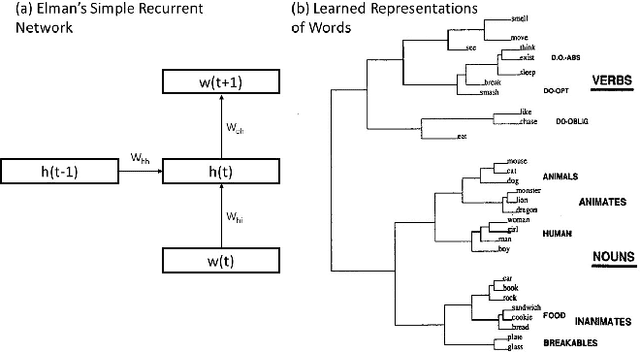
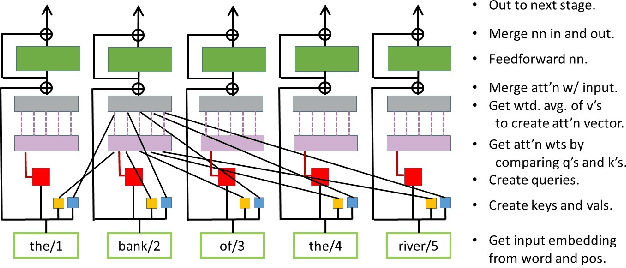
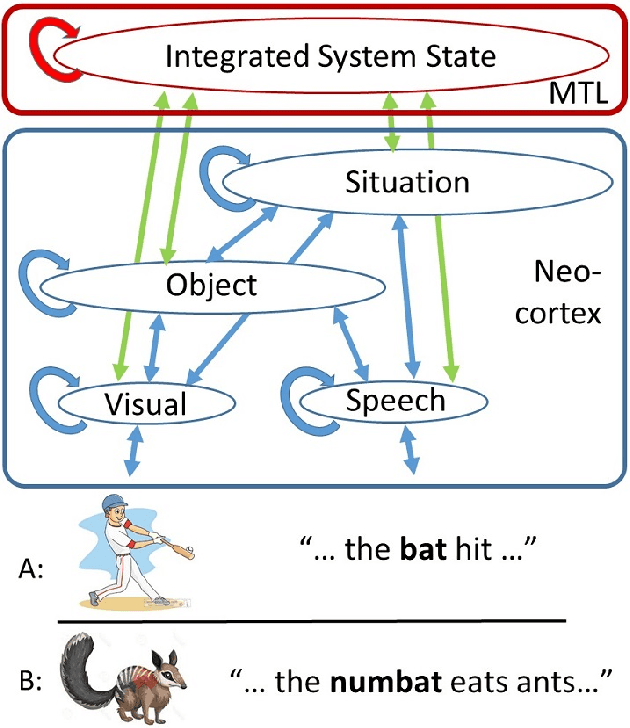
Language is central to human intelligence. We review recent breakthroughs in machine language processing and consider what remains to be achieved. Recent approaches rely on domain general principles of learning and representation captured in artificial neural networks. Most current models, however, focus too closely on language itself. In humans, language is part of a larger system for acquiring, representing, and communicating about objects and situations in the physical and social world, and future machine language models should emulate such a system. We describe existing machine models linking language to concrete situations, and point toward extensions to address more abstract cases. Human language processing exploits complementary learning systems, including a deep neural network-like learning system that learns gradually as machine systems do, as well as a fast-learning system that supports learning new information quickly. Adding such a system to machine language models will be an important further step toward truly human-like language understanding.
Emergent Systematic Generalization in a Situated Agent
Oct 28, 2019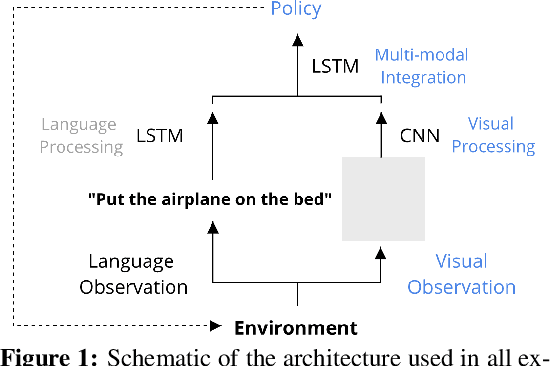
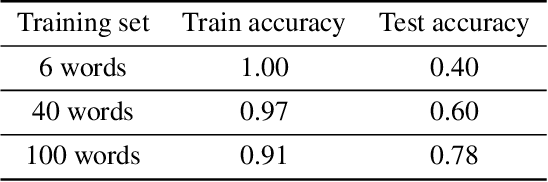
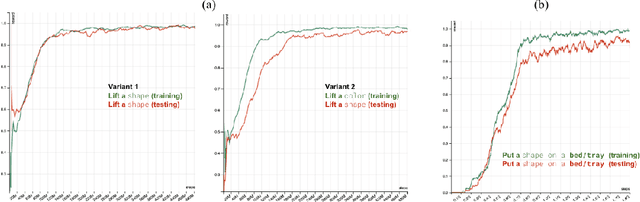
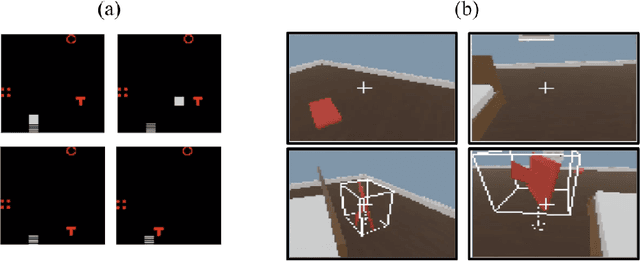
The question of whether deep neural networks are good at generalising beyond their immediate training experience is of critical importance for learning-based approaches to AI. Here, we demonstrate strong emergent systematic generalisation in a neural network agent and isolate the factors that support this ability. In environments ranging from a grid-world to a rich interactive 3D Unity room, we show that an agent can correctly exploit the compositional nature of a symbolic language to interpret never-seen-before instructions. We observe this capacity not only when instructions refer to object properties (colors and shapes) but also verb-like motor skills (lifting and putting) and abstract modifying operations (negation). We identify three factors that can contribute to this facility for systematic generalisation: (a) the number of object/word experiences in the training set; (b) the invariances afforded by a first-person, egocentric perspective; and (c) the variety of visual input experienced by an agent that perceives the world actively over time. Thus, while neural nets trained in idealised or reduced situations may fail to exhibit a compositional or systematic understanding of their experience, this competence can readily emerge when, like human learners, they have access to many examples of richly varying, multi-modal observations as they learn.
Higher-order Comparisons of Sentence Encoder Representations
Sep 05, 2019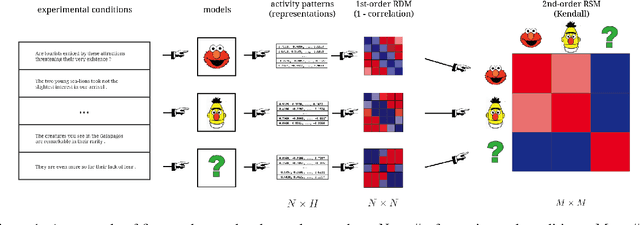
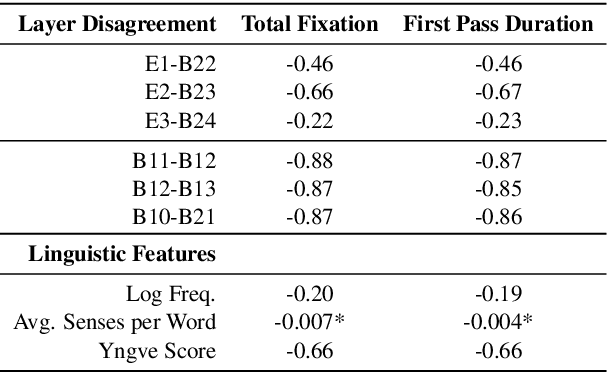
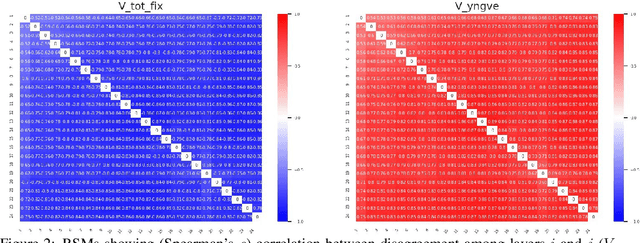
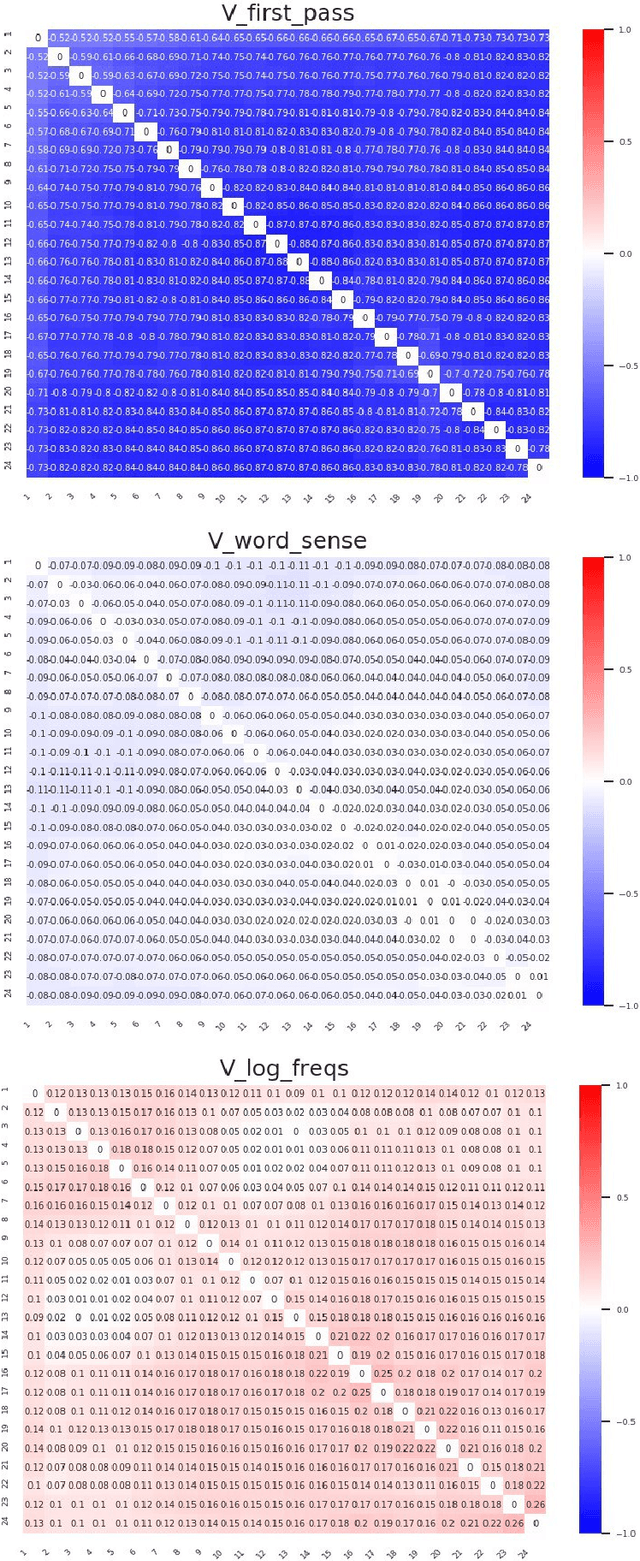
Representational Similarity Analysis (RSA) is a technique developed by neuroscientists for comparing activity patterns of different measurement modalities (e.g., fMRI, electrophysiology, behavior). As a framework, RSA has several advantages over existing approaches to interpretation of language encoders based on probing or diagnostic classification: namely, it does not require large training samples, is not prone to overfitting, and it enables a more transparent comparison between the representational geometries of different models and modalities. We demonstrate the utility of RSA by establishing a previously unknown correspondence between widely-employed pretrained language encoders and human processing difficulty via eye-tracking data, showcasing its potential in the interpretability toolbox for neural models