 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
May 28, 2026Larger models learn tasks smaller models do not. What drives this phenomenon? We develop a simple phenomenological argument that power-law scaling already suggests that a larger model will be able to learn a part of the data distribution that a smaller model fails to learn, even with infinite training data. To validate this claim and identify its causes, we study the effects of model scaling on a synthetic setup consisting of a mixture of tasks that show monotonic scaling curves. The results point to a data-induced competition over resources (neurons). Specifically, smaller models allocate their neurons to high frequency or low complexity tasks, and so they learn solutions that perform poorly on rare and complex tasks. Moreover, this happens even when solutions capable of expressing the desired task exist. We then assess how a larger model circumvents this data-centric bottleneck, finding that it traces to a reduced interference mechanism: larger models can allocate enough resources to common tasks that the gradient updates for those tasks become weak, which means that they do not overwrite rare-task features as they slowly accumulate. Finally, to further validate these claims, we pretrain OLMo models (4M to 4B parameters) on novel tasks of varying frequency and complexity. The results mirror those from our synthetic data experiments: only the larger OLMo models learn the infrequent and complex tasks, and these larger models embed more task features in their representations and show less gradient interference between tasks. Overall, we offer a data-centric account of why larger models learn tasks that smaller models fail to. This helps explain why larger models are better in practice, and it can inform practical questions concerning model sizing and training data mixtures.
Beneath the Surface: Investigating LLMs' Capabilities for Communicating with Subtext
Apr 07, 2026Human communication is fundamentally creative, and often makes use of subtext -- implied meaning that goes beyond the literal content of the text. Here, we systematically study whether language models can use subtext in communicative settings, and introduce four new evaluation suites to assess these capabilities. Our evaluation settings range from writing & interpreting allegories to playing multi-agent and multi-modal games inspired by the rules of board games like Dixit. We find that frontier models generally exhibit a strong bias towards overly literal, explicit communication, and thereby fail to account for nuanced constraints -- even the best performing models generate literal clues 60% of times in one of our environments -- Visual Allusions. However, we find that some models can sometimes make use of common ground with another party to help them communicate with subtext, achieving 30%-50% reduction in overly literal clues; but they struggle at inferring presence of a common ground when not explicitly stated. For allegory understanding, we find paratextual and persona conditions to significantly shift the interpretation of subtext. Overall, our work provides quantifiable measures for an inherently complex and subjective phenomenon like subtext and reveals many weaknesses and idiosyncrasies of current LLMs. We hope this research to inspire future work towards socially grounded creative communication and reasoning.
Context Structure Reshapes the Representational Geometry of Language Models
Jan 29, 2026Large Language Models (LLMs) have been shown to organize the representations of input sequences into straighter neural trajectories in their deep layers, which has been hypothesized to facilitate next-token prediction via linear extrapolation. Language models can also adapt to diverse tasks and learn new structure in context, and recent work has shown that this in-context learning (ICL) can be reflected in representational changes. Here we bring these two lines of research together to explore whether representation straightening occurs \emph{within} a context during ICL. We measure representational straightening in Gemma 2 models across a diverse set of in-context tasks, and uncover a dichotomy in how LLMs' representations change in context. In continual prediction settings (e.g., natural language, grid world traversal tasks) we observe that increasing context increases the straightness of neural sequence trajectories, which is correlated with improvement in model prediction. Conversely, in structured prediction settings (e.g., few-shot tasks), straightening is inconsistent -- it is only present in phases of the task with explicit structure (e.g., repeating a template), but vanishes elsewhere. These results suggest that ICL is not a monolithic process. Instead, we propose that LLMs function like a Swiss Army knife: depending on task structure, the LLM dynamically selects between strategies, only some of which yield representational straightening.
Linear representations in language models can change dramatically over a conversation
Jan 28, 2026Language model representations often contain linear directions that correspond to high-level concepts. Here, we study the dynamics of these representations: how representations evolve along these dimensions within the context of (simulated) conversations. We find that linear representations can change dramatically over a conversation; for example, information that is represented as factual at the beginning of a conversation can be represented as non-factual at the end and vice versa. These changes are content-dependent; while representations of conversation-relevant information may change, generic information is generally preserved. These changes are robust even for dimensions that disentangle factuality from more superficial response patterns, and occur across different model families and layers of the model. These representation changes do not require on-policy conversations; even replaying a conversation script written by an entirely different model can produce similar changes. However, adaptation is much weaker from simply having a sci-fi story in context that is framed more explicitly as such. We also show that steering along a representational direction can have dramatically different effects at different points in a conversation. These results are consistent with the idea that representations may evolve in response to the model playing a particular role that is cued by a conversation. Our findings may pose challenges for interpretability and steering -- in particular, they imply that it may be misleading to use static interpretations of features or directions, or probes that assume a particular range of features consistently corresponds to a particular ground-truth value. However, these types of representational dynamics also point to exciting new research directions for understanding how models adapt to context.
Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
Sep 19, 2025When do machine learning systems fail to generalize, and what mechanisms could improve their generalization? Here, we draw inspiration from cognitive science to argue that one weakness of machine learning systems is their failure to exhibit latent learning -- learning information that is not relevant to the task at hand, but that might be useful in a future task. We show how this perspective links failures ranging from the reversal curse in language modeling to new findings on agent-based navigation. We then highlight how cognitive science points to episodic memory as a potential part of the solution to these issues. Correspondingly, we show that a system with an oracle retrieval mechanism can use learning experiences more flexibly to generalize better across many of these challenges. We also identify some of the essential components for effectively using retrieval, including the importance of within-example in-context learning for acquiring the ability to use information across retrieved examples. In summary, our results illustrate one possible contributor to the relative data inefficiency of current machine learning systems compared to natural intelligence, and help to understand how retrieval methods can complement parametric learning to improve generalization.
Representation biases: will we achieve complete understanding by analyzing representations?
Jul 29, 2025



A common approach in neuroscience is to study neural representations as a means to understand a system -- increasingly, by relating the neural representations to the internal representations learned by computational models. However, a recent work in machine learning (Lampinen, 2024) shows that learned feature representations may be biased to over-represent certain features, and represent others more weakly and less-consistently. For example, simple (linear) features may be more strongly and more consistently represented than complex (highly nonlinear) features. These biases could pose challenges for achieving full understanding of a system through representational analysis. In this perspective, we illustrate these challenges -- showing how feature representation biases can lead to strongly biased inferences from common analyses like PCA, regression, and RSA. We also present homomorphic encryption as a simple case study of the potential for strong dissociation between patterns of representation and computation. We discuss the implications of these results for representational comparisons between systems, and for neuroscience more generally.
The broader spectrum of in-context learning
Dec 05, 2024

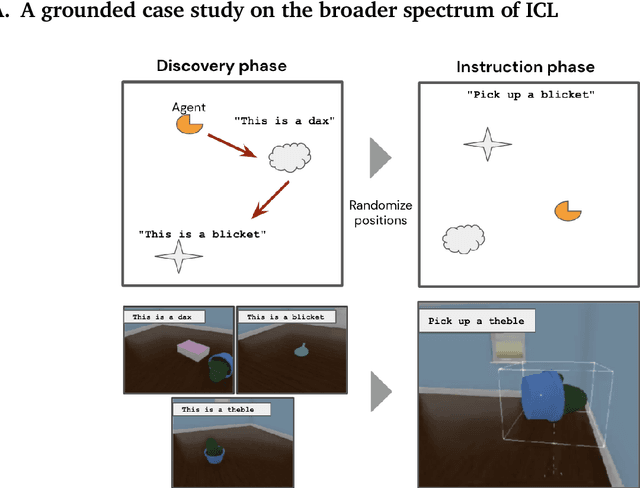
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning within a much broader spectrum of meta-learned in-context learning. Indeed, we suggest that any distribution of sequences in which context non-trivially decreases loss on subsequent predictions can be interpreted as eliciting a kind of in-context learning. We suggest that this perspective helps to unify the broad set of in-context abilities that language models exhibit $\unicode{x2014}$ such as adapting to tasks from instructions or role play, or extrapolating time series. This perspective also sheds light on potential roots of in-context learning in lower-level processing of linguistic dependencies (e.g. coreference or parallel structures). Finally, taking this perspective highlights the importance of generalization, which we suggest can be studied along several dimensions: not only the ability to learn something novel, but also flexibility in learning from different presentations, and in applying what is learned. We discuss broader connections to past literature in meta-learning and goal-conditioned agents, and other perspectives on learning and adaptation. We close by suggesting that research on in-context learning should consider this broader spectrum of in-context capabilities and types of generalization.
Understanding Visual Feature Reliance through the Lens of Complexity
Jul 08, 2024



Recent studies suggest that deep learning models inductive bias towards favoring simpler features may be one of the sources of shortcut learning. Yet, there has been limited focus on understanding the complexity of the myriad features that models learn. In this work, we introduce a new metric for quantifying feature complexity, based on $\mathscr{V}$-information and capturing whether a feature requires complex computational transformations to be extracted. Using this $\mathscr{V}$-information metric, we analyze the complexities of 10,000 features, represented as directions in the penultimate layer, that were extracted from a standard ImageNet-trained vision model. Our study addresses four key questions: First, we ask what features look like as a function of complexity and find a spectrum of simple to complex features present within the model. Second, we ask when features are learned during training. We find that simpler features dominate early in training, and more complex features emerge gradually. Third, we investigate where within the network simple and complex features flow, and find that simpler features tend to bypass the visual hierarchy via residual connections. Fourth, we explore the connection between features complexity and their importance in driving the networks decision. We find that complex features tend to be less important. Surprisingly, important features become accessible at earlier layers during training, like a sedimentation process, allowing the model to build upon these foundational elements.
Learned feature representations are biased by complexity, learning order, position, and more
May 09, 2024



Representation learning, and interpreting learned representations, are key areas of focus in machine learning and neuroscience. Both fields generally use representations as a means to understand or improve a system's computations. In this work, however, we explore surprising dissociations between representation and computation that may pose challenges for such efforts. We create datasets in which we attempt to match the computational role that different features play, while manipulating other properties of the features or the data. We train various deep learning architectures to compute these multiple abstract features about their inputs. We find that their learned feature representations are systematically biased towards representing some features more strongly than others, depending upon extraneous properties such as feature complexity, the order in which features are learned, and the distribution of features over the inputs. For example, features that are simpler to compute or learned first tend to be represented more strongly and densely than features that are more complex or learned later, even if all features are learned equally well. We also explore how these biases are affected by architectures, optimizers, and training regimes (e.g., in transformers, features decoded earlier in the output sequence also tend to be represented more strongly). Our results help to characterize the inductive biases of gradient-based representation learning. These results also highlight a key challenge for interpretability $-$ or for comparing the representations of models and brains $-$ disentangling extraneous biases from the computationally important aspects of a system's internal representations.
Combining Behaviors with the Successor Features Keyboard
Oct 24, 2023The Option Keyboard (OK) was recently proposed as a method for transferring behavioral knowledge across tasks. OK transfers knowledge by adaptively combining subsets of known behaviors using Successor Features (SFs) and Generalized Policy Improvement (GPI). However, it relies on hand-designed state-features and task encodings which are cumbersome to design for every new environment. In this work, we propose the "Successor Features Keyboard" (SFK), which enables transfer with discovered state-features and task encodings. To enable discovery, we propose the "Categorical Successor Feature Approximator" (CSFA), a novel learning algorithm for estimating SFs while jointly discovering state-features and task encodings. With SFK and CSFA, we achieve the first demonstration of transfer with SFs in a challenging 3D environment where all the necessary representations are discovered. We first compare CSFA against other methods for approximating SFs and show that only CSFA discovers representations compatible with SF&GPI at this scale. We then compare SFK against transfer learning baselines and show that it transfers most quickly to long-horizon tasks.