 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Deep Learning Embeddings for Speech Emotion Recognition by Predicting Interpretable Acoustic Features
Sep 14, 2024Pre-trained deep learning embeddings have consistently shown superior performance over handcrafted acoustic features in speech emotion recognition (SER). However, unlike acoustic features with clear physical meaning, these embeddings lack clear interpretability. Explaining these embeddings is crucial for building trust in healthcare and security applications and advancing the scientific understanding of the acoustic information that is encoded in them. This paper proposes a modified probing approach to explain deep learning embeddings in the SER space. We predict interpretable acoustic features (e.g., f0, loudness) from (i) the complete set of embeddings and (ii) a subset of the embedding dimensions identified as most important for predicting each emotion. If the subset of the most important dimensions better predicts a given emotion than all dimensions and also predicts specific acoustic features more accurately, we infer those acoustic features are important for the embedding model for the given task. We conducted experiments using the WavLM embeddings and eGeMAPS acoustic features as audio representations, applying our method to the RAVDESS and SAVEE emotional speech datasets. Based on this evaluation, we demonstrate that Energy, Frequency, Spectral, and Temporal categories of acoustic features provide diminishing information to SER in that order, demonstrating the utility of the probing classifier method to relate embeddings to interpretable acoustic features.
Higher-order Comparisons of Sentence Encoder Representations
Sep 05, 2019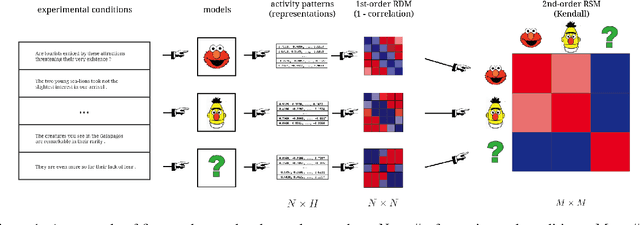
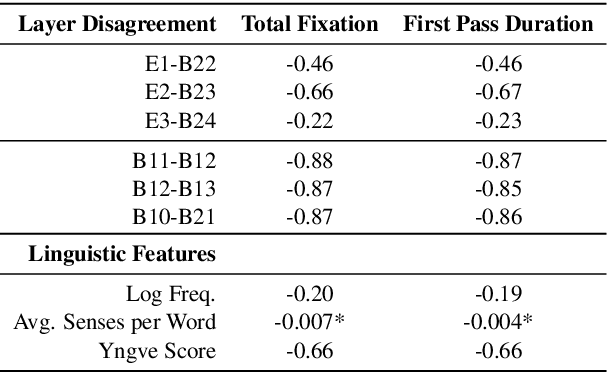
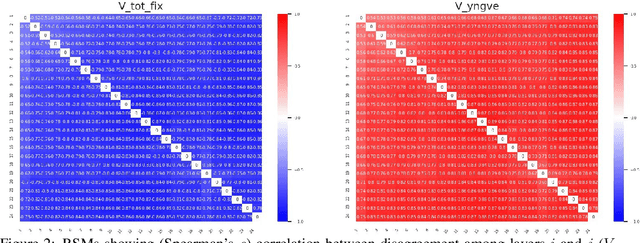
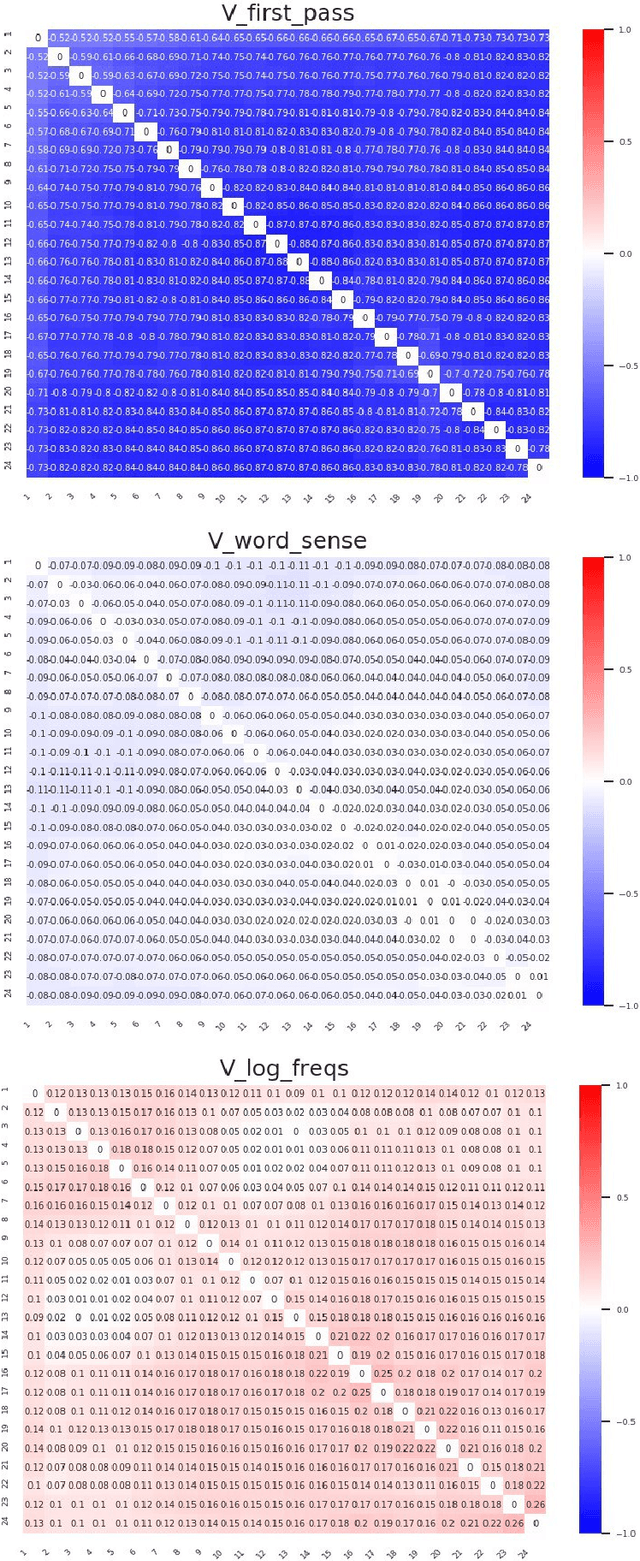
Representational Similarity Analysis (RSA) is a technique developed by neuroscientists for comparing activity patterns of different measurement modalities (e.g., fMRI, electrophysiology, behavior). As a framework, RSA has several advantages over existing approaches to interpretation of language encoders based on probing or diagnostic classification: namely, it does not require large training samples, is not prone to overfitting, and it enables a more transparent comparison between the representational geometries of different models and modalities. We demonstrate the utility of RSA by establishing a previously unknown correspondence between widely-employed pretrained language encoders and human processing difficulty via eye-tracking data, showcasing its potential in the interpretability toolbox for neural models