 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayMap3R: Inference-Time RayMap for Dynamic 3D Reconstruction
Mar 21, 2026Streaming feed-forward 3D reconstruction enables real-time joint estimation of scene geometry and camera poses from RGB images. However, without explicit dynamic reasoning, streaming models can be affected by moving objects, causing artifacts and drift. In this work, we propose RayMap3R, a training-free streaming framework for dynamic scene reconstruction. We observe that RayMap-based predictions exhibit a static-scene bias, providing an internal cue for dynamic identification. Based on this observation, we construct a dual-branch inference scheme that identifies dynamic regions by contrasting RayMap and image predictions, suppressing their interference during memory updates. We further introduce reset metric alignment and state-aware smoothing to preserve metric consistency and stabilize predicted trajectories. Our method achieves state-of-the-art performance among streaming approaches on dynamic scene reconstruction across multiple benchmarks.
CogniMap3D: Cognitive 3D Mapping and Rapid Retrieval
Jan 13, 2026We present CogniMap3D, a bioinspired framework for dynamic 3D scene understanding and reconstruction that emulates human cognitive processes. Our approach maintains a persistent memory bank of static scenes, enabling efficient spatial knowledge storage and rapid retrieval. CogniMap3D integrates three core capabilities: a multi-stage motion cue framework for identifying dynamic objects, a cognitive mapping system for storing, recalling, and updating static scenes across multiple visits, and a factor graph optimization strategy for refining camera poses. Given an image stream, our model identifies dynamic regions through motion cues with depth and camera pose priors, then matches static elements against its memory bank. When revisiting familiar locations, CogniMap3D retrieves stored scenes, relocates cameras, and updates memory with new observations. Evaluations on video depth estimation, camera pose reconstruction, and 3D mapping tasks demonstrate its state-of-the-art performance, while effectively supporting continuous scene understanding across extended sequences and multiple visits.
Consistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025



We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
From Particles to Fields: Reframing Photon Mapping with Continuous Gaussian Photon Fields
Dec 13, 2025Accurately modeling light transport is essential for realistic image synthesis. Photon mapping provides physically grounded estimates of complex global illumination effects such as caustics and specular-diffuse interactions, yet its per-view radiance estimation remains computationally inefficient when rendering multiple views of the same scene. The inefficiency arises from independent photon tracing and stochastic kernel estimation at each viewpoint, leading to inevitable redundant computation. To accelerate multi-view rendering, we reformulate photon mapping as a continuous and reusable radiance function. Specifically, we introduce the Gaussian Photon Field (GPF), a learnable representation that encodes photon distributions as anisotropic 3D Gaussian primitives parameterized by position, rotation, scale, and spectrum. GPF is initialized from physically traced photons in the first SPPM iteration and optimized using multi-view supervision of final radiance, distilling photon-based light transport into a continuous field. Once trained, the field enables differentiable radiance evaluation along camera rays without repeated photon tracing or iterative refinement. Extensive experiments on scenes with complex light transport, such as caustics and specular-diffuse interactions, demonstrate that GPF attains photon-level accuracy while reducing computation by orders of magnitude, unifying the physical rigor of photon-based rendering with the efficiency of neural scene representations.
X-Field: A Physically Grounded Representation for 3D X-ray Reconstruction
Mar 11, 2025X-ray imaging is indispensable in medical diagnostics, yet its use is tightly regulated due to potential health risks. To mitigate radiation exposure, recent research focuses on generating novel views from sparse inputs and reconstructing Computed Tomography (CT) volumes, borrowing representations from the 3D reconstruction area. However, these representations originally target visible light imaging that emphasizes reflection and scattering effects, while neglecting penetration and attenuation properties of X-ray imaging. In this paper, we introduce X-Field, the first 3D representation specifically designed for X-ray imaging, rooted in the energy absorption rates across different materials. To accurately model diverse materials within internal structures, we employ 3D ellipsoids with distinct attenuation coefficients. To estimate each material's energy absorption of X-rays, we devise an efficient path partitioning algorithm accounting for complex ellipsoid intersections. We further propose hybrid progressive initialization to refine the geometric accuracy of X-Filed and incorporate material-based optimization to enhance model fitting along material boundaries. Experiments show that X-Field achieves superior visual fidelity on both real-world human organ and synthetic object datasets, outperforming state-of-the-art methods in X-ray Novel View Synthesis and CT Reconstruction.
Bi-stable thin soft robot for in-plane locomotion in narrow space
Sep 30, 2024



Dielectric elastomer actuators (DEAs), also recognized as artificial muscle, have been widely developed for the soft locomotion robot. With the complaint skeleton and miniaturized dimension, they are well suited for the narrow space inspection. In this work, we propose a novel low profile (1.1mm) and lightweight (1.8g) bi-stable in-plane DEA (Bi-DEA) constructed by supporting a dielectric elastomer onto a flat bi-stable mechanism. It has an amplified displacement and output force compared with the in-plane DEA (I-DEA) without the bi-stable mechanism. Then, the Bi-DEA is applied to a thin soft robot, using three electrostatic adhesive pads (EA-Pads) as anchoring elements. This robot is capable of crawling and climbing to access millimetre-scale narrow gaps. A theoretical model of the bi-stable mechanism and the DEA are presented. The enhanced performance of the Bi-DEA induced by the mechanism is experimentally validated. EA-Pad provides the adhesion between the actuator and the locomotion substrate, allowing crawling and climbing on various surfaces, i.e., paper and acrylic. The thin soft robot has been demonstrated to be capable of crawling through a 4mm narrow gap with a speed up to 3.3mm/s (0.07 body length per second and 2.78 body thickness per second).
Incremental Knowledge Base Construction Using DeepDive
Jun 15, 2015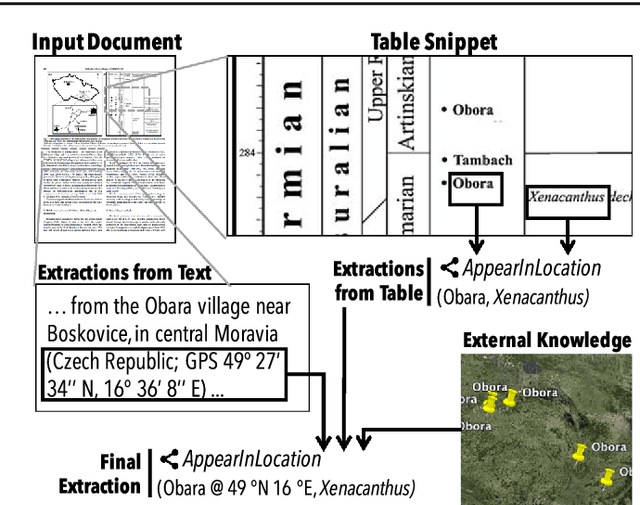
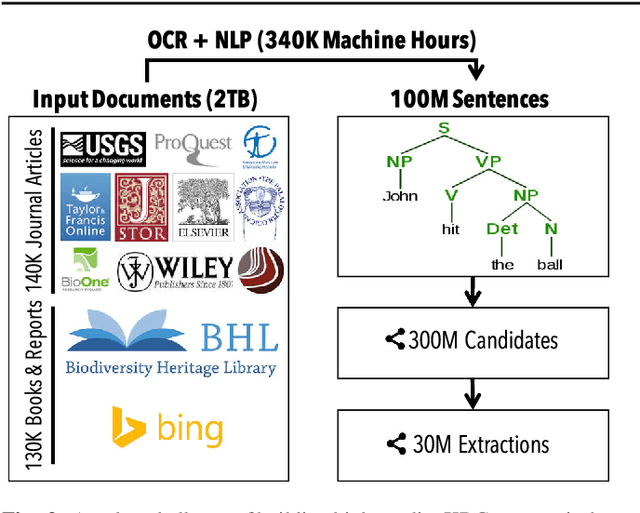
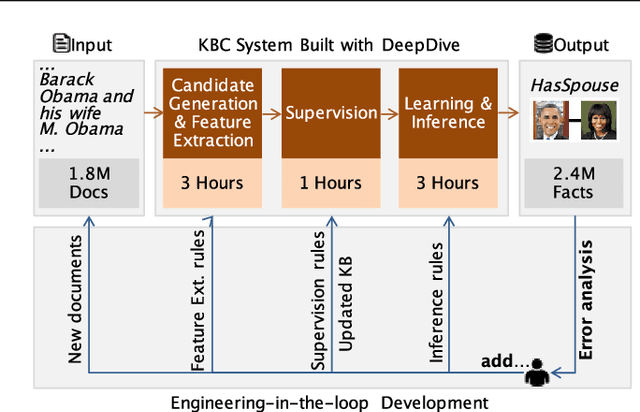
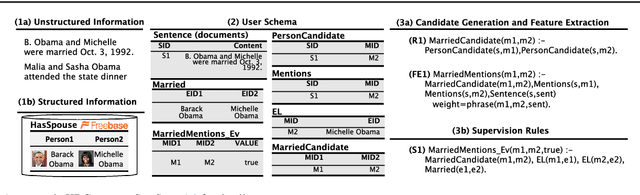
Populating a database with unstructured information is a long-standing problem in industry and research that encompasses problems of extraction, cleaning, and integration. Recent names used for this problem include dealing with dark data and knowledge base construction (KBC). In this work, we describe DeepDive, a system that combines database and machine learning ideas to help develop KBC systems, and we present techniques to make the KBC process more efficient. We observe that the KBC process is iterative, and we develop techniques to incrementally produce inference results for KBC systems. We propose two methods for incremental inference, based respectively on sampling and variational techniques. We also study the tradeoff space of these methods and develop a simple rule-based optimizer. DeepDive includes all of these contributions, and we evaluate DeepDive on five KBC systems, showing that it can speed up KBC inference tasks by up to two orders of magnitude with negligible impact on quality.
Feature Engineering for Knowledge Base Construction
Sep 18, 2014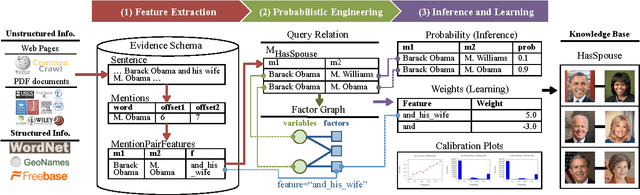
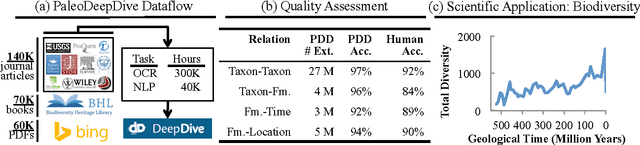

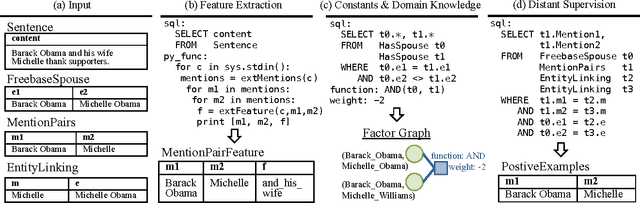
Knowledge base construction (KBC) is the process of populating a knowledge base, i.e., a relational database together with inference rules, with information extracted from documents and structured sources. KBC blurs the distinction between two traditional database problems, information extraction and information integration. For the last several years, our group has been building knowledge bases with scientific collaborators. Using our approach, we have built knowledge bases that have comparable and sometimes better quality than those constructed by human volunteers. In contrast to these knowledge bases, which took experts a decade or more human years to construct, many of our projects are constructed by a single graduate student. Our approach to KBC is based on joint probabilistic inference and learning, but we do not see inference as either a panacea or a magic bullet: inference is a tool that allows us to be systematic in how we construct, debug, and improve the quality of such systems. In addition, inference allows us to construct these systems in a more loosely coupled way than traditional approaches. To support this idea, we have built the DeepDive system, which has the design goal of letting the user "think about features---not algorithms." We think of DeepDive as declarative in that one specifies what they want but not how to get it. We describe our approach with a focus on feature engineering, which we argue is an understudied problem relative to its importance to end-to-end quality.