 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill Video Datasets into Images
Dec 16, 2025



Dataset distillation aims to synthesize compact yet informative datasets that allow models trained on them to achieve performance comparable to training on the full dataset. While this approach has shown promising results for image data, extending dataset distillation methods to video data has proven challenging and often leads to suboptimal performance. In this work, we first identify the core challenge in video set distillation as the substantial increase in learnable parameters introduced by the temporal dimension of video, which complicates optimization and hinders convergence. To address this issue, we observe that a single frame is often sufficient to capture the discriminative semantics of a video. Leveraging this insight, we propose Single-Frame Video set Distillation (SFVD), a framework that distills videos into highly informative frames for each class. Using differentiable interpolation, these frames are transformed into video sequences and matched with the original dataset, while updates are restricted to the frames themselves for improved optimization efficiency. To further incorporate temporal information, the distilled frames are combined with sampled real videos from real videos during the matching process through a channel reshaping layer. Extensive experiments on multiple benchmarks demonstrate that SFVD substantially outperforms prior methods, achieving improvements of up to 5.3% on MiniUCF, thereby offering a more effective solution.
Consistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025



We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
From Particles to Fields: Reframing Photon Mapping with Continuous Gaussian Photon Fields
Dec 13, 2025Accurately modeling light transport is essential for realistic image synthesis. Photon mapping provides physically grounded estimates of complex global illumination effects such as caustics and specular-diffuse interactions, yet its per-view radiance estimation remains computationally inefficient when rendering multiple views of the same scene. The inefficiency arises from independent photon tracing and stochastic kernel estimation at each viewpoint, leading to inevitable redundant computation. To accelerate multi-view rendering, we reformulate photon mapping as a continuous and reusable radiance function. Specifically, we introduce the Gaussian Photon Field (GPF), a learnable representation that encodes photon distributions as anisotropic 3D Gaussian primitives parameterized by position, rotation, scale, and spectrum. GPF is initialized from physically traced photons in the first SPPM iteration and optimized using multi-view supervision of final radiance, distilling photon-based light transport into a continuous field. Once trained, the field enables differentiable radiance evaluation along camera rays without repeated photon tracing or iterative refinement. Extensive experiments on scenes with complex light transport, such as caustics and specular-diffuse interactions, demonstrate that GPF attains photon-level accuracy while reducing computation by orders of magnitude, unifying the physical rigor of photon-based rendering with the efficiency of neural scene representations.
Efficient Multimodal Dataset Distillation via Generative Models
Sep 18, 2025Dataset distillation aims to synthesize a small dataset from a large dataset, enabling the model trained on it to perform well on the original dataset. With the blooming of large language models and multimodal large language models, the importance of multimodal datasets, particularly image-text datasets, has grown significantly. However, existing multimodal dataset distillation methods are constrained by the Matching Training Trajectories algorithm, which significantly increases the computing resource requirement, and takes days to process the distillation. In this work, we introduce EDGE, a generative distillation method for efficient multimodal dataset distillation. Specifically, we identify two key challenges of distilling multimodal datasets with generative models: 1) The lack of correlation between generated images and captions. 2) The lack of diversity among generated samples. To address the aforementioned issues, we propose a novel generative model training workflow with a bi-directional contrastive loss and a diversity loss. Furthermore, we propose a caption synthesis strategy to further improve text-to-image retrieval performance by introducing more text information. Our method is evaluated on Flickr30K, COCO, and CC3M datasets, demonstrating superior performance and efficiency compared to existing approaches. Notably, our method achieves results 18x faster than the state-of-the-art method.
Distilling Long-tailed Datasets
Aug 24, 2024



Dataset distillation (DD) aims to distill a small, information-rich dataset from a larger one for efficient neural network training. However, existing DD methods struggle with long-tailed datasets, which are prevalent in real-world scenarios. By investigating the reasons behind this unexpected result, we identified two main causes: 1) Expert networks trained on imbalanced data develop biased gradients, leading to the synthesis of similarly imbalanced distilled datasets. Parameter matching, a common technique in DD, involves aligning the learning parameters of the distilled dataset with that of the original dataset. However, in the context of long-tailed datasets, matching biased experts leads to inheriting the imbalance present in the original data, causing the distilled dataset to inadequately represent tail classes. 2) The experts trained on such datasets perform suboptimally on tail classes, resulting in misguided distillation supervision and poor-quality soft-label initialization. To address these issues, we propose a novel long-tailed dataset distillation method, Long-tailed Aware Dataset distillation (LAD). Specifically, we propose Weight Mismatch Avoidance to avoid directly matching the biased expert trajectories. It reduces the distance between the student and the biased expert trajectories and prevents the tail class bias from being distilled to the synthetic dataset. Moreover, we propose Adaptive Decoupled Matching, which jointly matches the decoupled backbone and classifier to improve the tail class performance and initialize reliable soft labels. This work pioneers the field of long-tailed dataset distillation (LTDD), marking the first effective effort to distill long-tailed datasets.
Dataset Quantization with Active Learning based Adaptive Sampling
Jul 09, 2024



Deep learning has made remarkable progress recently, largely due to the availability of large, well-labeled datasets. However, the training on such datasets elevates costs and computational demands. To address this, various techniques like coreset selection, dataset distillation, and dataset quantization have been explored in the literature. Unlike traditional techniques that depend on uniform sample distributions across different classes, our research demonstrates that maintaining performance is feasible even with uneven distributions. We find that for certain classes, the variation in sample quantity has a minimal impact on performance. Inspired by this observation, an intuitive idea is to reduce the number of samples for stable classes and increase the number of samples for sensitive classes to achieve a better performance with the same sampling ratio. Then the question arises: how can we adaptively select samples from a dataset to achieve optimal performance? In this paper, we propose a novel active learning based adaptive sampling strategy, Dataset Quantization with Active Learning based Adaptive Sampling (DQAS), to optimize the sample selection. In addition, we introduce a novel pipeline for dataset quantization, utilizing feature space from the final stage of dataset quantization to generate more precise dataset bins. Our comprehensive evaluations on the multiple datasets show that our approach outperforms the state-of-the-art dataset compression methods.
Supplementing Missing Visions via Dialog for Scene Graph Generations
Apr 23, 2022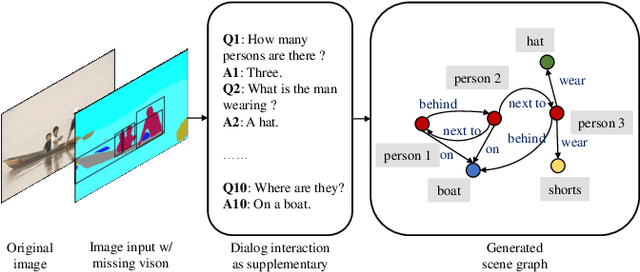
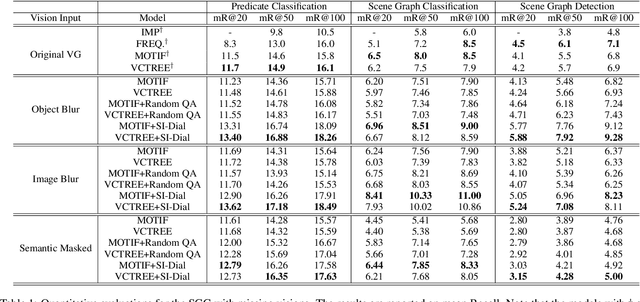
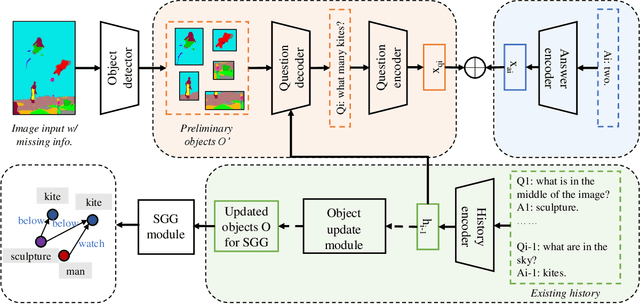
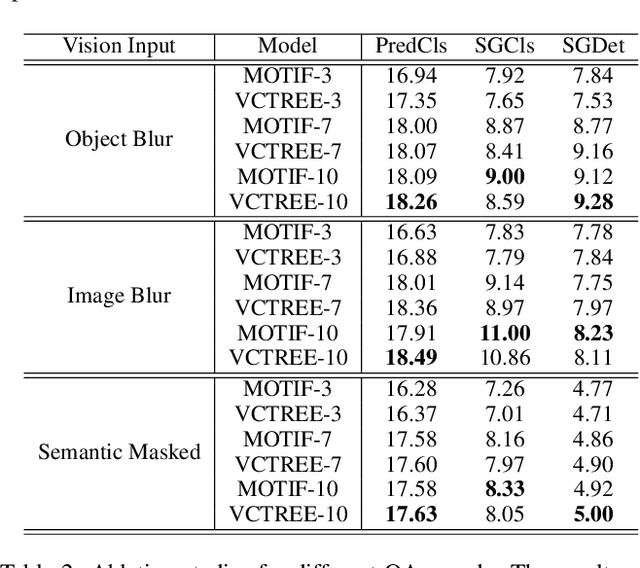
Most current AI systems rely on the premise that the input visual data are sufficient to achieve competitive performance in various computer vision tasks. However, the classic task setup rarely considers the challenging, yet common practical situations where the complete visual data may be inaccessible due to various reasons (e.g., restricted view range and occlusions). To this end, we investigate a computer vision task setting with incomplete visual input data. Specifically, we exploit the Scene Graph Generation (SGG) task with various levels of visual data missingness as input. While insufficient visual input intuitively leads to performance drop, we propose to supplement the missing visions via the natural language dialog interactions to better accomplish the task objective. We design a model-agnostic Supplementary Interactive Dialog (SI-Dial) framework that can be jointly learned with most existing models, endowing the current AI systems with the ability of question-answer interactions in natural language. We demonstrate the feasibility of such a task setting with missing visual input and the effectiveness of our proposed dialog module as the supplementary information source through extensive experiments and analysis, by achieving promising performance improvement over multiple baselines.