 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Teach with Dynamic Loss Functions
Oct 29, 2018
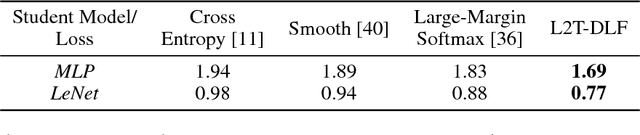
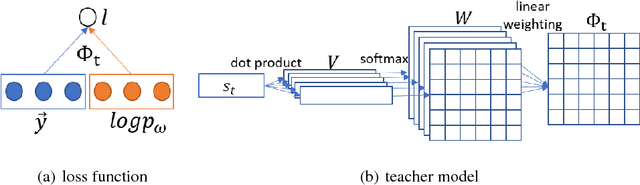
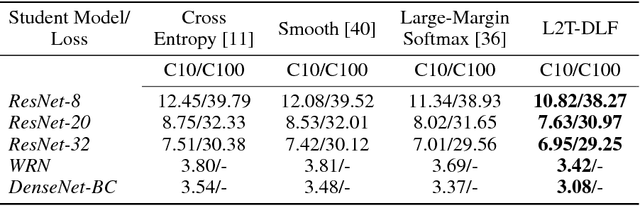
Teaching is critical to human society: it is with teaching that prospective students are educated and human civilization can be inherited and advanced. A good teacher not only provides his/her students with qualified teaching materials (e.g., textbooks), but also sets up appropriate learning objectives (e.g., course projects and exams) considering different situations of a student. When it comes to artificial intelligence, treating machine learning models as students, the loss functions that are optimized act as perfect counterparts of the learning objective set by the teacher. In this work, we explore the possibility of imitating human teaching behaviors by dynamically and automatically outputting appropriate loss functions to train machine learning models. Different from typical learning settings in which the loss function of a machine learning model is predefined and fixed, in our framework, the loss function of a machine learning model (we call it student) is defined by another machine learning model (we call it teacher). The ultimate goal of teacher model is cultivating the student to have better performance measured on development dataset. Towards that end, similar to human teaching, the teacher, a parametric model, dynamically outputs different loss functions that will be used and optimized by its student model at different training stages. We develop an efficient learning method for the teacher model that makes gradient based optimization possible, exempt of the ineffective solutions such as policy optimization. We name our method as "learning to teach with dynamic loss functions" (L2T-DLF for short). Extensive experiments on real world tasks including image classification and neural machine translation demonstrate that our method significantly improves the quality of various student models.
Adversarial Neural Machine Translation
Sep 30, 2018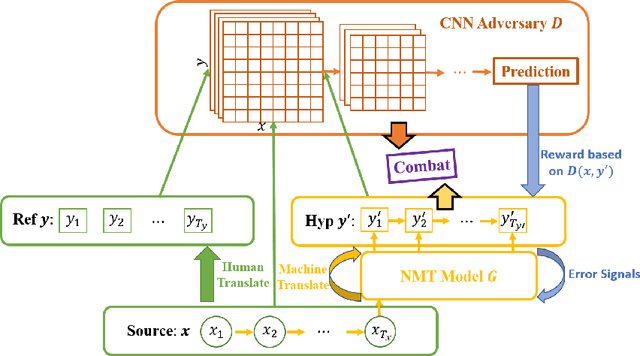
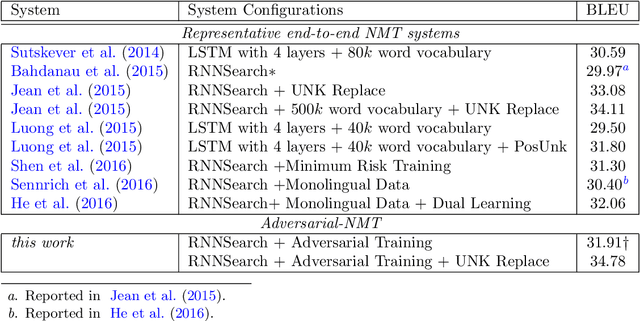
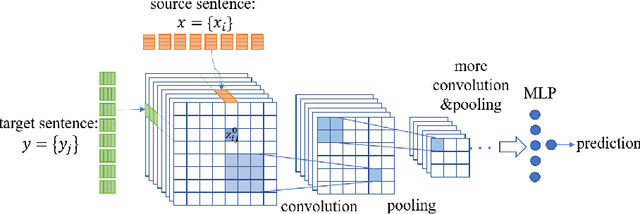
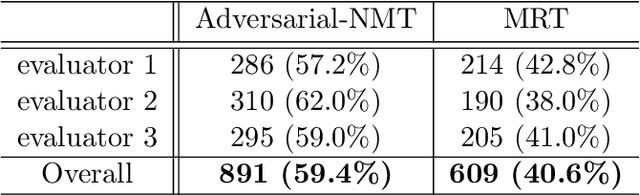
In this paper, we study a new learning paradigm for Neural Machine Translation (NMT). Instead of maximizing the likelihood of the human translation as in previous works, we minimize the distinction between human translation and the translation given by an NMT model. To achieve this goal, inspired by the recent success of generative adversarial networks (GANs), we employ an adversarial training architecture and name it as Adversarial-NMT. In Adversarial-NMT, the training of the NMT model is assisted by an adversary, which is an elaborately designed Convolutional Neural Network (CNN). The goal of the adversary is to differentiate the translation result generated by the NMT model from that by human. The goal of the NMT model is to produce high quality translations so as to cheat the adversary. A policy gradient method is leveraged to co-train the NMT model and the adversary. Experimental results on English$\rightarrow$French and German$\rightarrow$English translation tasks show that Adversarial-NMT can achieve significantly better translation quality than several strong baselines.
Beyond Error Propagation in Neural Machine Translation: Characteristics of Language Also Matter
Sep 11, 2018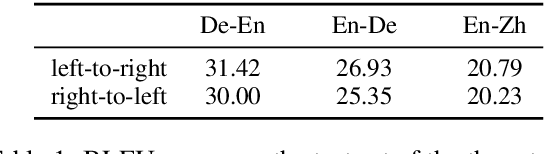
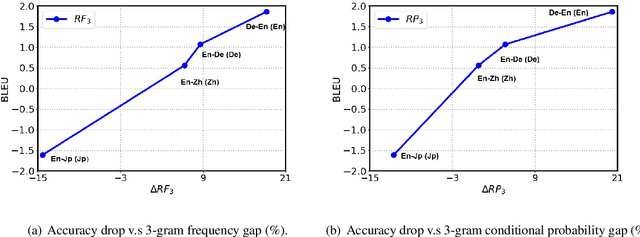
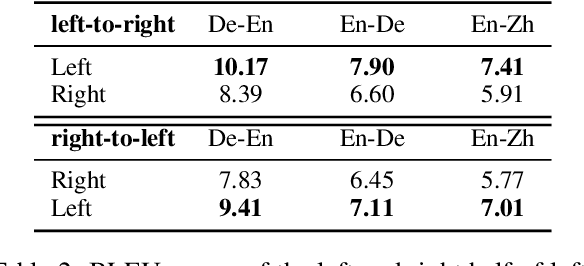
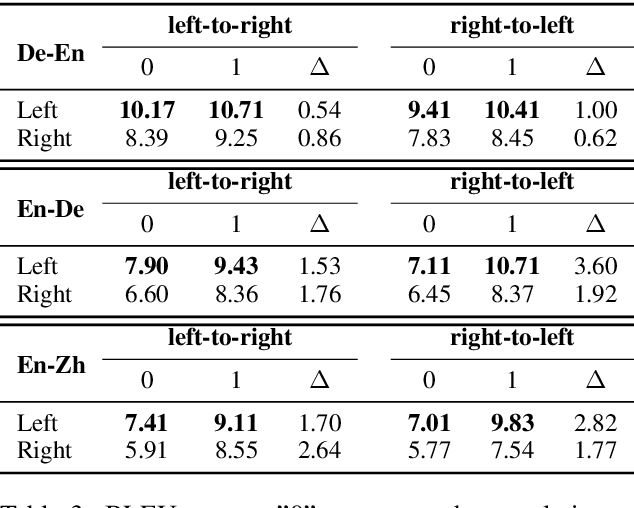
Neural machine translation usually adopts autoregressive models and suffers from exposure bias as well as the consequent error propagation problem. Many previous works have discussed the relationship between error propagation and the \emph{accuracy drop} (i.e., the left part of the translated sentence is often better than its right part in left-to-right decoding models) problem. In this paper, we conduct a series of analyses to deeply understand this problem and get several interesting findings. (1) The role of error propagation on accuracy drop is overstated in the literature, although it indeed contributes to the accuracy drop problem. (2) Characteristics of a language play a more important role in causing the accuracy drop: the left part of the translation result in a right-branching language (e.g., English) is more likely to be more accurate than its right part, while the right part is more accurate for a left-branching language (e.g., Japanese). Our discoveries are confirmed on different model structures including Transformer and RNN, and in other sequence generation tasks such as text summarization.
A Study of Reinforcement Learning for Neural Machine Translation
Aug 27, 2018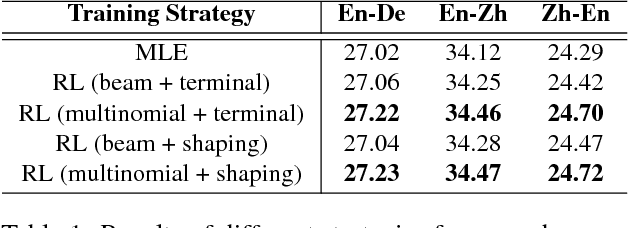
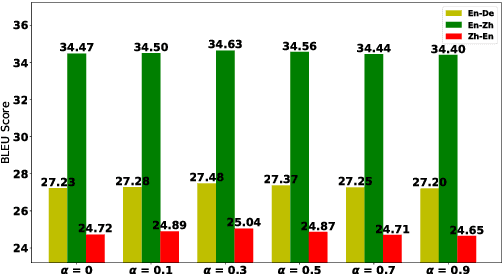

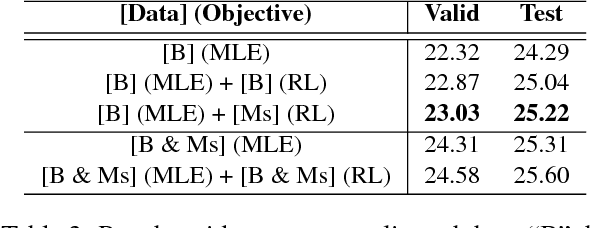
Recent studies have shown that reinforcement learning (RL) is an effective approach for improving the performance of neural machine translation (NMT) system. However, due to its instability, successfully RL training is challenging, especially in real-world systems where deep models and large datasets are leveraged. In this paper, taking several large-scale translation tasks as testbeds, we conduct a systematic study on how to train better NMT models using reinforcement learning. We provide a comprehensive comparison of several important factors (e.g., baseline reward, reward shaping) in RL training. Furthermore, to fill in the gap that it remains unclear whether RL is still beneficial when monolingual data is used, we propose a new method to leverage RL to further boost the performance of NMT systems trained with source/target monolingual data. By integrating all our findings, we obtain competitive results on WMT14 English- German, WMT17 English-Chinese, and WMT17 Chinese-English translation tasks, especially setting a state-of-the-art performance on WMT17 Chinese-English translation task.
Achieving Human Parity on Automatic Chinese to English News Translation
Jun 29, 2018


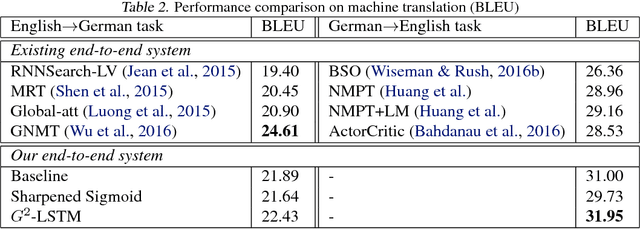
Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.
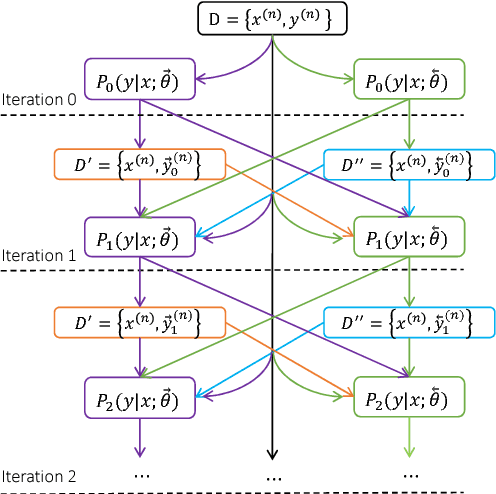
Towards Binary-Valued Gates for Robust LSTM Training
Jun 08, 2018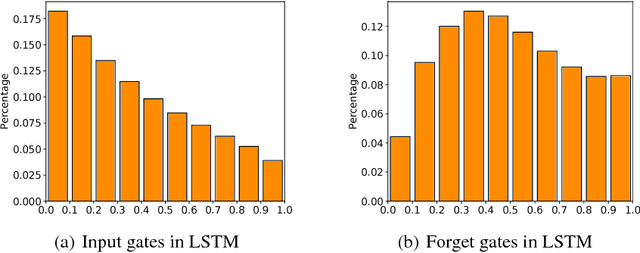
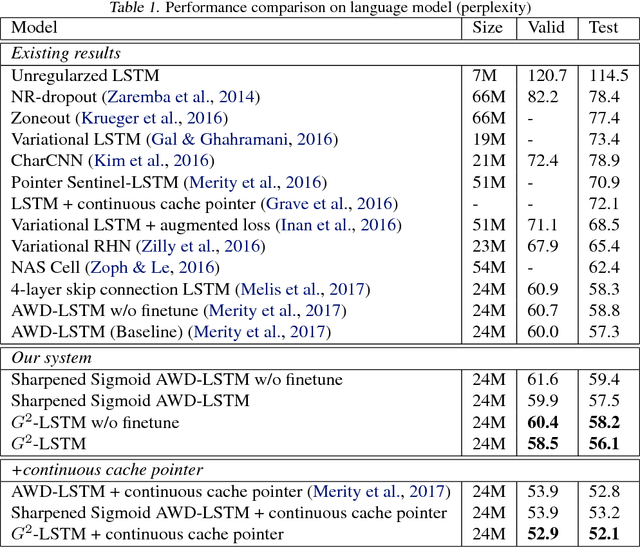
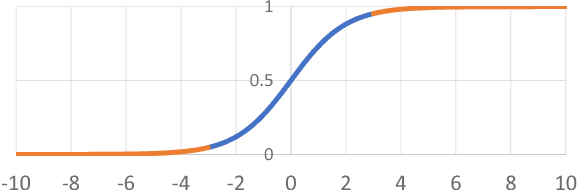
Long Short-Term Memory (LSTM) is one of the most widely used recurrent structures in sequence modeling. It aims to use gates to control information flow (e.g., whether to skip some information or not) in the recurrent computations, although its practical implementation based on soft gates only partially achieves this goal. In this paper, we propose a new way for LSTM training, which pushes the output values of the gates towards 0 or 1. By doing so, we can better control the information flow: the gates are mostly open or closed, instead of in a middle state, which makes the results more interpretable. Empirical studies show that (1) Although it seems that we restrict the model capacity, there is no performance drop: we achieve better or comparable performances due to its better generalization ability; (2) The outputs of gates are not sensitive to their inputs: we can easily compress the LSTM unit in multiple ways, e.g., low-rank approximation and low-precision approximation. The compressed models are even better than the baseline models without compression.
Learning to Teach
May 09, 2018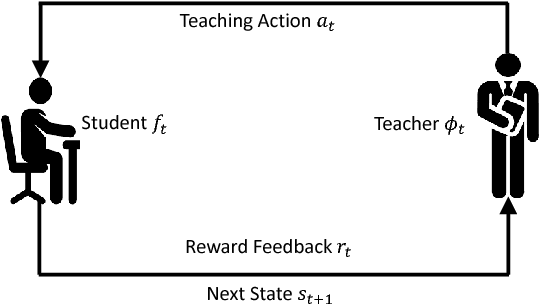

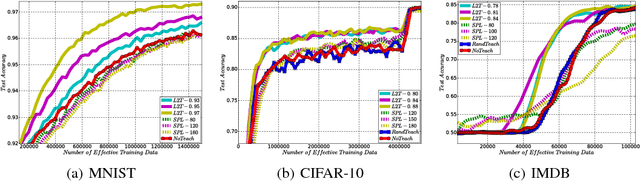
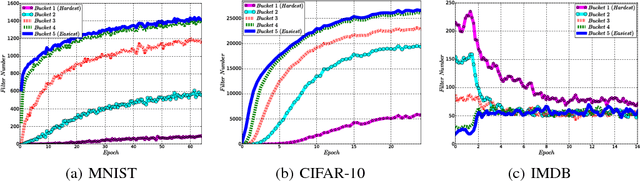
Teaching plays a very important role in our society, by spreading human knowledge and educating our next generations. A good teacher will select appropriate teaching materials, impact suitable methodologies, and set up targeted examinations, according to the learning behaviors of the students. In the field of artificial intelligence, however, one has not fully explored the role of teaching, and pays most attention to machine \emph{learning}. In this paper, we argue that equal attention, if not more, should be paid to teaching, and furthermore, an optimization framework (instead of heuristics) should be used to obtain good teaching strategies. We call this approach `learning to teach'. In the approach, two intelligent agents interact with each other: a student model (which corresponds to the learner in traditional machine learning algorithms), and a teacher model (which determines the appropriate data, loss function, and hypothesis space to facilitate the training of the student model). The teacher model leverages the feedback from the student model to optimize its own teaching strategies by means of reinforcement learning, so as to achieve teacher-student co-evolution. To demonstrate the practical value of our proposed approach, we take the training of deep neural networks (DNN) as an example, and show that by using the learning to teach techniques, we are able to use much less training data and fewer iterations to achieve almost the same accuracy for different kinds of DNN models (e.g., multi-layer perceptron, convolutional neural networks and recurrent neural networks) under various machine learning tasks (e.g., image classification and text understanding).
Learning What Data to Learn
Feb 28, 2017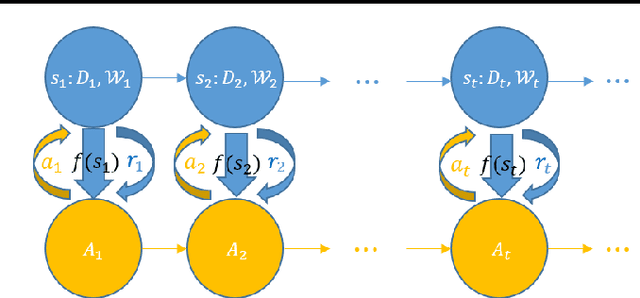
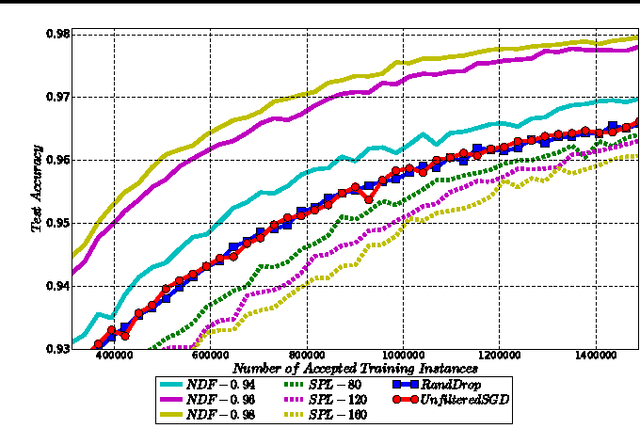
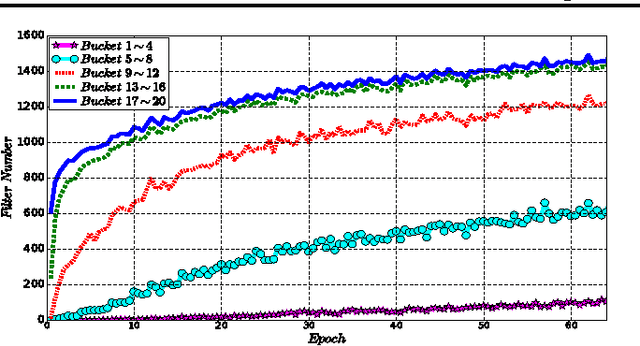
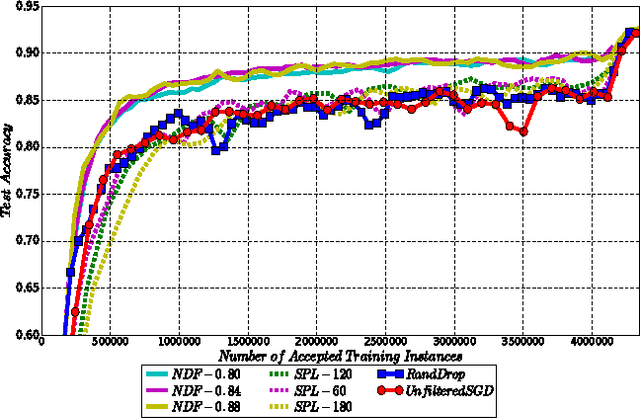
Machine learning is essentially the sciences of playing with data. An adaptive data selection strategy, enabling to dynamically choose different data at various training stages, can reach a more effective model in a more efficient way. In this paper, we propose a deep reinforcement learning framework, which we call \emph{\textbf{N}eural \textbf{D}ata \textbf{F}ilter} (\textbf{NDF}), to explore automatic and adaptive data selection in the training process. In particular, NDF takes advantage of a deep neural network to adaptively select and filter important data instances from a sequential stream of training data, such that the future accumulative reward (e.g., the convergence speed) is maximized. In contrast to previous studies in data selection that is mainly based on heuristic strategies, NDF is quite generic and thus can be widely suitable for many machine learning tasks. Taking neural network training with stochastic gradient descent (SGD) as an example, comprehensive experiments with respect to various neural network modeling (e.g., multi-layer perceptron networks, convolutional neural networks and recurrent neural networks) and several applications (e.g., image classification and text understanding) demonstrate that NDF powered SGD can achieve comparable accuracy with standard SGD process by using less data and fewer iterations.
Solving Verbal Comprehension Questions in IQ Test by Knowledge-Powered Word Embedding
Apr 26, 2016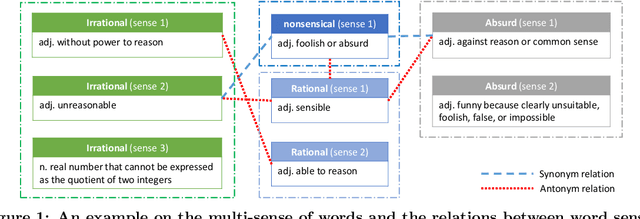
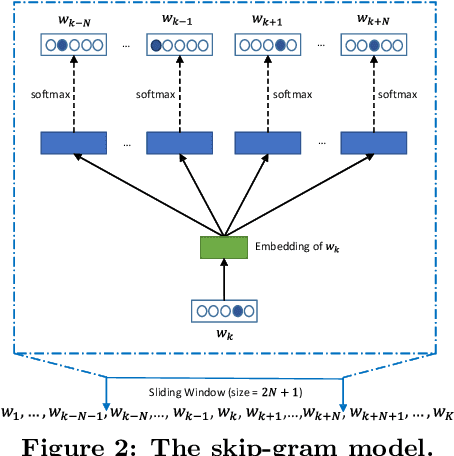
Intelligence Quotient (IQ) Test is a set of standardized questions designed to evaluate human intelligence. Verbal comprehension questions appear very frequently in IQ tests, which measure human's verbal ability including the understanding of the words with multiple senses, the synonyms and antonyms, and the analogies among words. In this work, we explore whether such tests can be solved automatically by artificial intelligence technologies, especially the deep learning technologies that are recently developed and successfully applied in a number of fields. However, we found that the task was quite challenging, and simply applying existing technologies (e.g., word embedding) could not achieve a good performance, mainly due to the multiple senses of words and the complex relations among words. To tackle these challenges, we propose a novel framework consisting of three components. First, we build a classifier to recognize the specific type of a verbal question (e.g., analogy, classification, synonym, or antonym). Second, we obtain distributed representations of words and relations by leveraging a novel word embedding method that considers the multi-sense nature of words and the relational knowledge among words (or their senses) contained in dictionaries. Third, for each type of questions, we propose a specific solver based on the obtained distributed word representations and relation representations. Experimental results have shown that the proposed framework can not only outperform existing methods for solving verbal comprehension questions but also exceed the average performance of the Amazon Mechanical Turk workers involved in the study. The results indicate that with appropriate uses of the deep learning technologies we might be a further step closer to the human intelligence.
Sentence Level Recurrent Topic Model: Letting Topics Speak for Themselves
Apr 08, 2016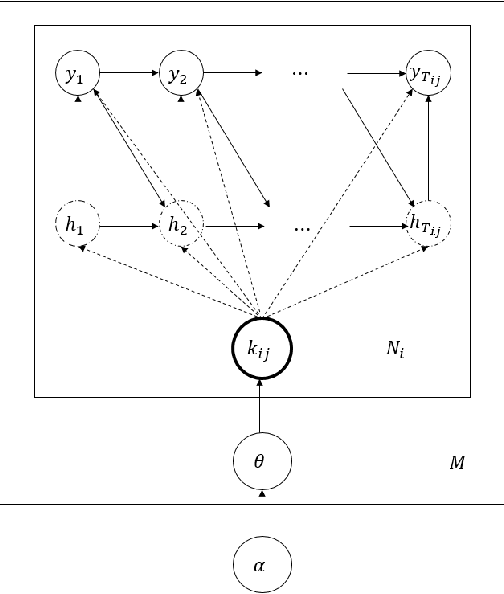
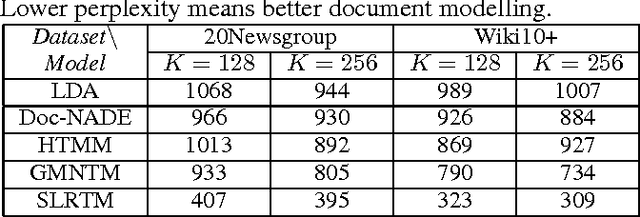
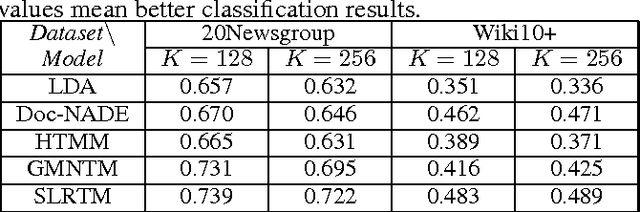
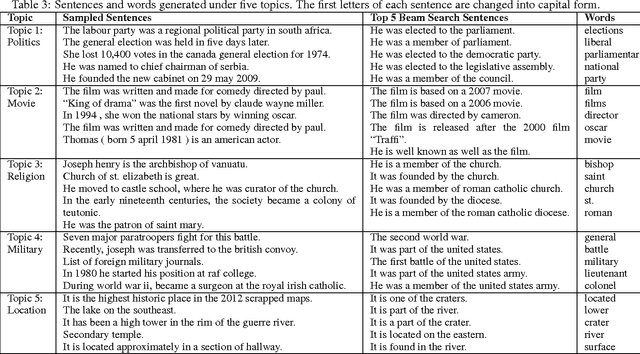
We propose Sentence Level Recurrent Topic Model (SLRTM), a new topic model that assumes the generation of each word within a sentence to depend on both the topic of the sentence and the whole history of its preceding words in the sentence. Different from conventional topic models that largely ignore the sequential order of words or their topic coherence, SLRTM gives full characterization to them by using a Recurrent Neural Networks (RNN) based framework. Experimental results have shown that SLRTM outperforms several strong baselines on various tasks. Furthermore, SLRTM can automatically generate sentences given a topic (i.e., topics to sentences), which is a key technology for real world applications such as personalized short text conversation.