 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFang Wen
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Nov 29, 2021
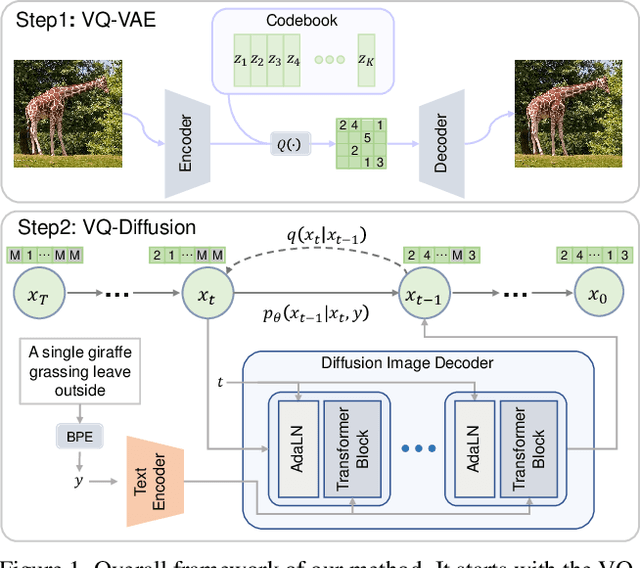
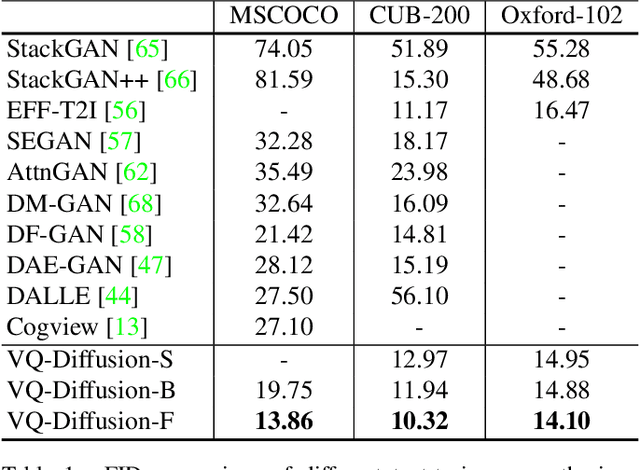

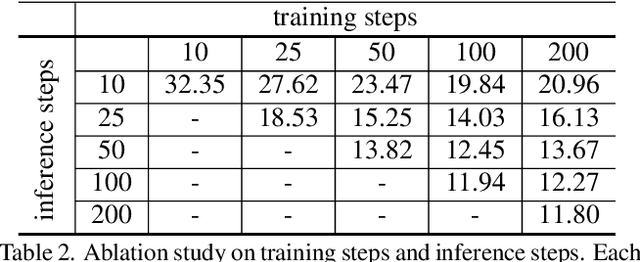
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
Nov 24, 2021
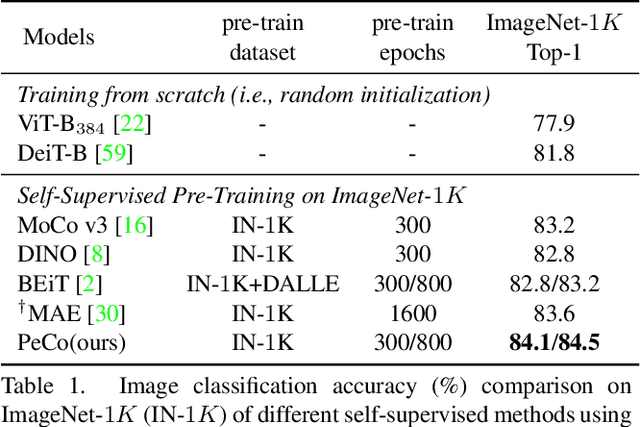
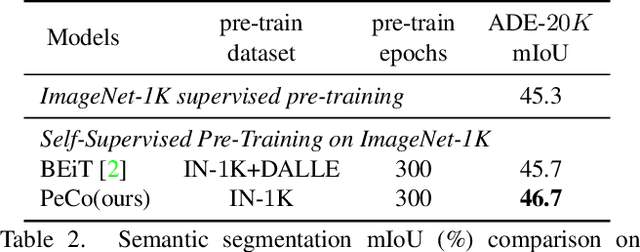

This paper explores a better codebook for BERT pre-training of vision transformers. The recent work BEiT successfully transfers BERT pre-training from NLP to the vision field. It directly adopts one simple discrete VAE as the visual tokenizer, but has not considered the semantic level of the resulting visual tokens. By contrast, the discrete tokens in NLP field are naturally highly semantic. This difference motivates us to learn a perceptual codebook. And we surprisingly find one simple yet effective idea: enforcing perceptual similarity during the dVAE training. We demonstrate that the visual tokens generated by the proposed perceptual codebook do exhibit better semantic meanings, and subsequently help pre-training achieve superior transfer performance in various downstream tasks. For example, we achieve 84.5 Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming the competitive method BEiT by +1.3 with the same pre-training epochs. It can also improve the performance of object detection and segmentation tasks on COCO val by +1.3 box AP and +1.0 mask AP, semantic segmentation on ADE20k by +1.0 mIoU, The code and models will be available at \url{https://github.com/microsoft/PeCo}.
Exploring Temporal Coherence for More General Video Face Forgery Detection
Aug 15, 2021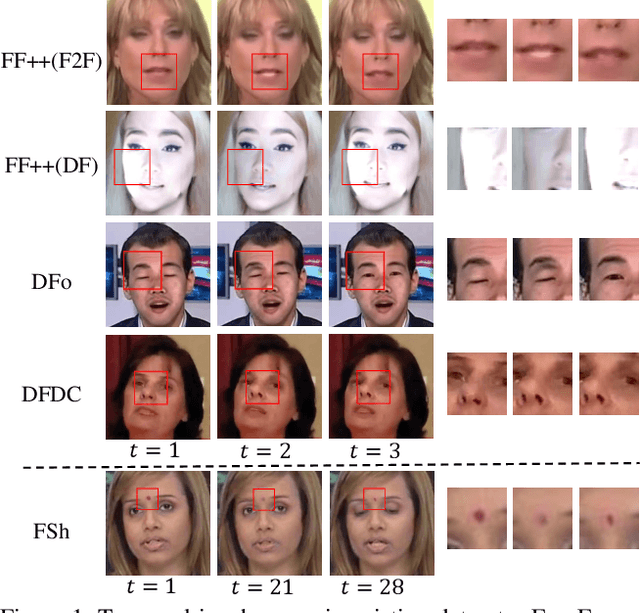
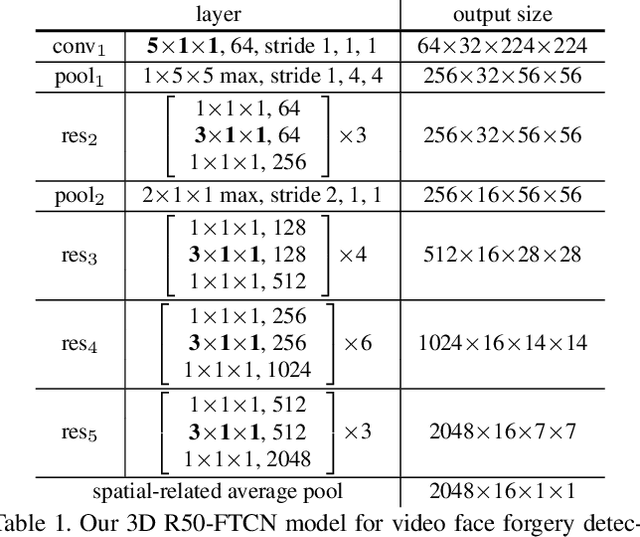
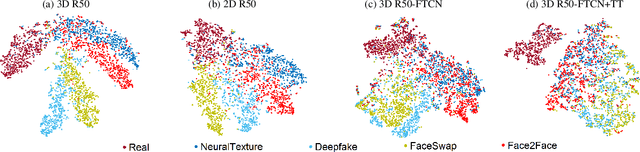
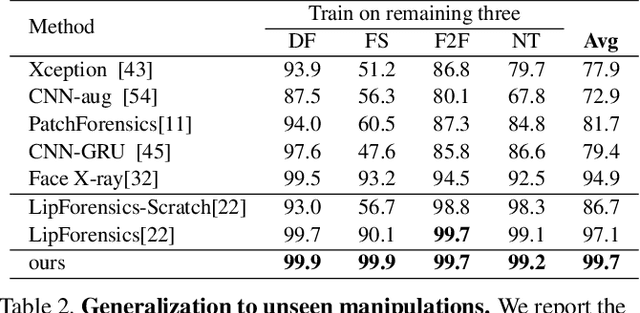
Although current face manipulation techniques achieve impressive performance regarding quality and controllability, they are struggling to generate temporal coherent face videos. In this work, we explore to take full advantage of the temporal coherence for video face forgery detection. To achieve this, we propose a novel end-to-end framework, which consists of two major stages. The first stage is a fully temporal convolution network (FTCN). The key insight of FTCN is to reduce the spatial convolution kernel size to 1, while maintaining the temporal convolution kernel size unchanged. We surprisingly find this special design can benefit the model for extracting the temporal features as well as improve the generalization capability. The second stage is a Temporal Transformer network, which aims to explore the long-term temporal coherence. The proposed framework is general and flexible, which can be directly trained from scratch without any pre-training models or external datasets. Extensive experiments show that our framework outperforms existing methods and remains effective when applied to detect new sorts of face forgery videos.
Dual Path Learning for Domain Adaptation of Semantic Segmentation
Aug 13, 2021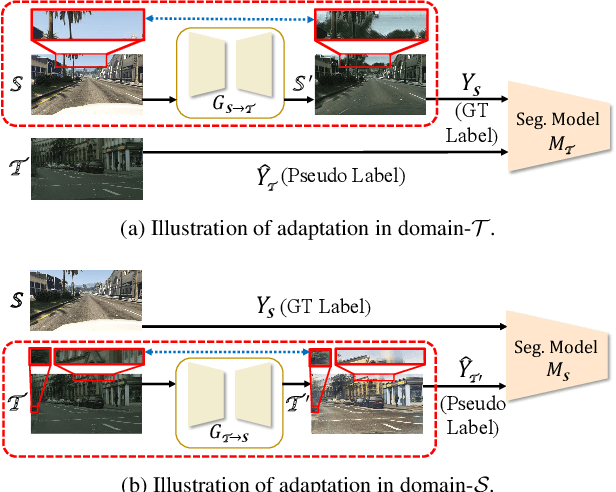
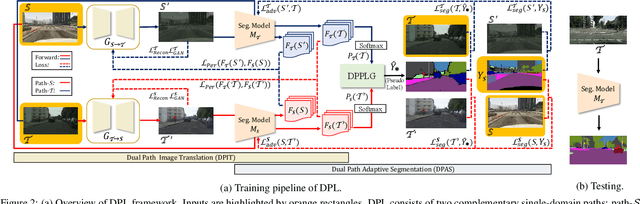
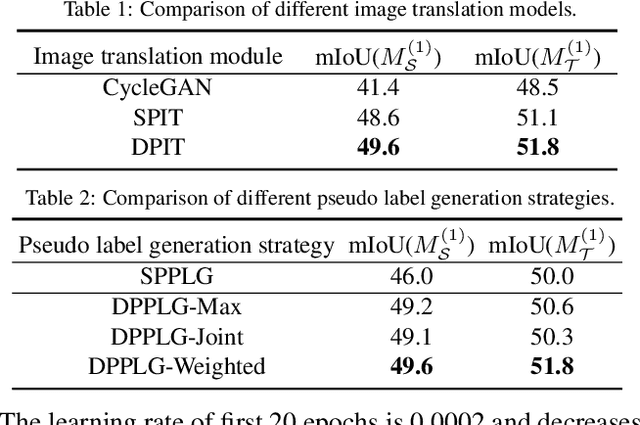
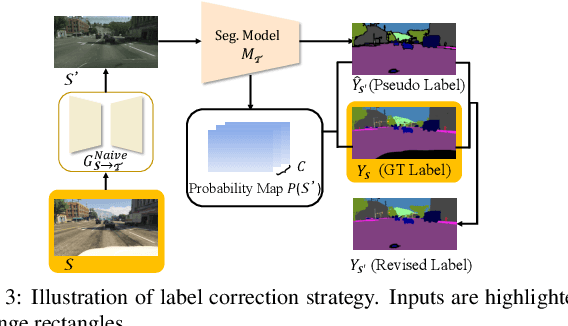
Domain adaptation for semantic segmentation enables to alleviate the need for large-scale pixel-wise annotations. Recently, self-supervised learning (SSL) with a combination of image-to-image translation shows great effectiveness in adaptive segmentation. The most common practice is to perform SSL along with image translation to well align a single domain (the source or target). However, in this single-domain paradigm, unavoidable visual inconsistency raised by image translation may affect subsequent learning. In this paper, based on the observation that domain adaptation frameworks performed in the source and target domain are almost complementary in terms of image translation and SSL, we propose a novel dual path learning (DPL) framework to alleviate visual inconsistency. Concretely, DPL contains two complementary and interactive single-domain adaptation pipelines aligned in source and target domain respectively. The inference of DPL is extremely simple, only one segmentation model in the target domain is employed. Novel technologies such as dual path image translation and dual path adaptive segmentation are proposed to make two paths promote each other in an interactive manner. Experiments on GTA5$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes scenarios demonstrate the superiority of our DPL model over the state-of-the-art methods. The code and models are available at: \url{https://github.com/royee182/DPL}
Robust Mutual Learning for Semi-supervised Semantic Segmentation
Jun 01, 2021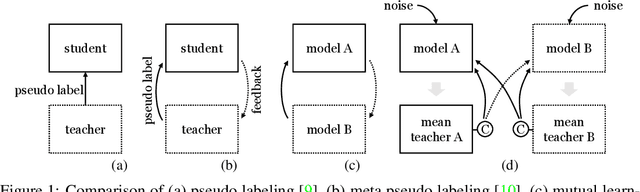
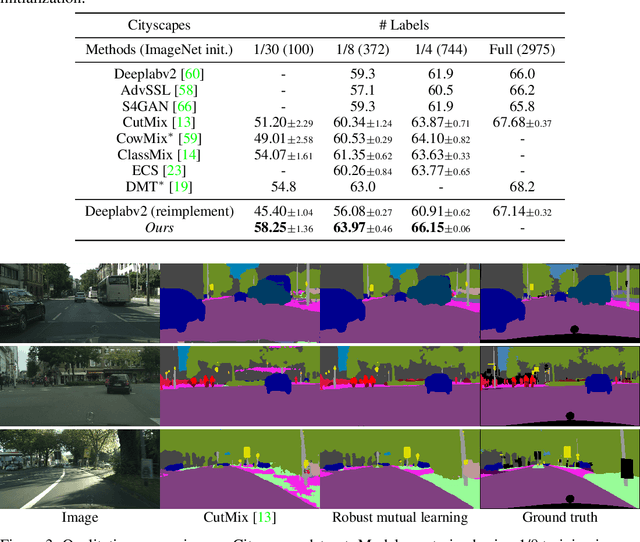
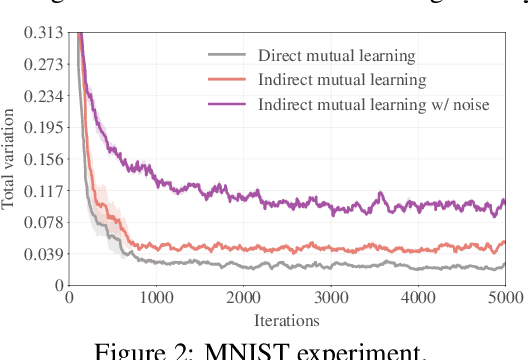
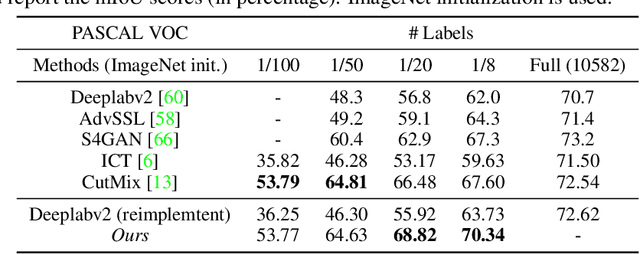
Recent semi-supervised learning (SSL) methods are commonly based on pseudo labeling. Since the SSL performance is greatly influenced by the quality of pseudo labels, mutual learning has been proposed to effectively suppress the noises in the pseudo supervision. In this work, we propose robust mutual learning that improves the prior approach in two aspects. First, the vanilla mutual learners suffer from the coupling issue that models may converge to learn homogeneous knowledge. We resolve this issue by introducing mean teachers to generate mutual supervisions so that there is no direct interaction between the two students. We also show that strong data augmentations, model noises and heterogeneous network architectures are essential to alleviate the model coupling. Second, we notice that mutual learning fails to leverage the network's own ability for pseudo label refinement. Therefore, we introduce self-rectification that leverages the internal knowledge and explicitly rectifies the pseudo labels before the mutual teaching. Such self-rectification and mutual teaching collaboratively improve the pseudo label accuracy throughout the learning. The proposed robust mutual learning demonstrates state-of-the-art performance on semantic segmentation in low-data regime.
High-Fidelity and Arbitrary Face Editing
Mar 29, 2021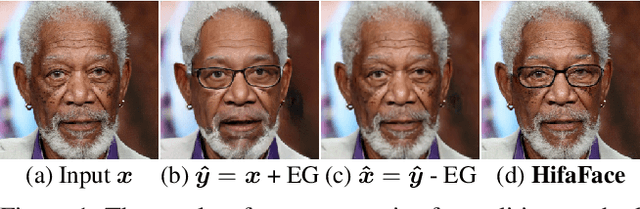
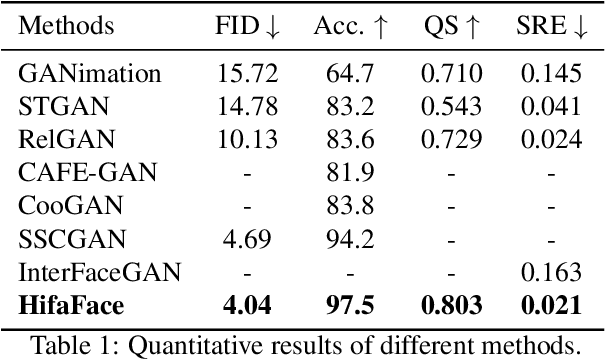


Cycle consistency is widely used for face editing. However, we observe that the generator tends to find a tricky way to hide information from the original image to satisfy the constraint of cycle consistency, making it impossible to maintain the rich details (e.g., wrinkles and moles) of non-editing areas. In this work, we propose a simple yet effective method named HifaFace to address the above-mentioned problem from two perspectives. First, we relieve the pressure of the generator to synthesize rich details by directly feeding the high-frequency information of the input image into the end of the generator. Second, we adopt an additional discriminator to encourage the generator to synthesize rich details. Specifically, we apply wavelet transformation to transform the image into multi-frequency domains, among which the high-frequency parts can be used to recover the rich details. We also notice that a fine-grained and wider-range control for the attribute is of great importance for face editing. To achieve this goal, we propose a novel attribute regression loss. Powered by the proposed framework, we achieve high-fidelity and arbitrary face editing, outperforming other state-of-the-art approaches.
Style-based Point Generator with Adversarial Rendering for Point Cloud Completion
Mar 26, 2021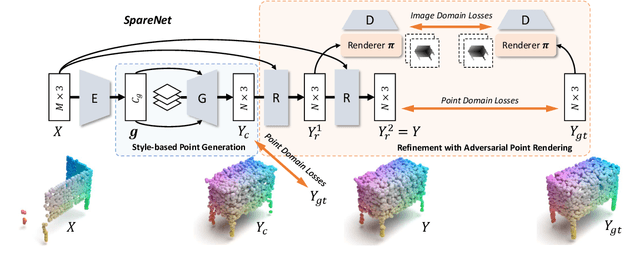
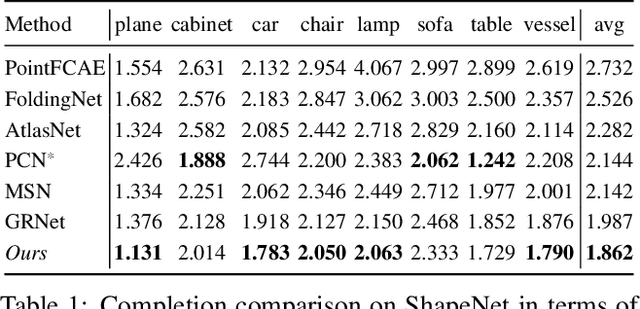
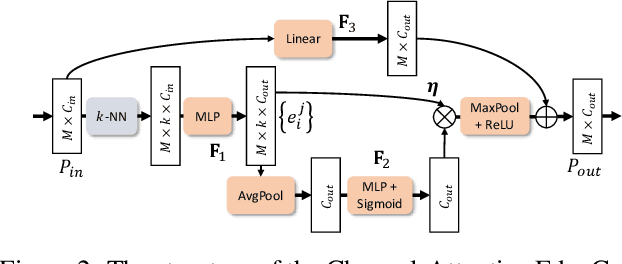
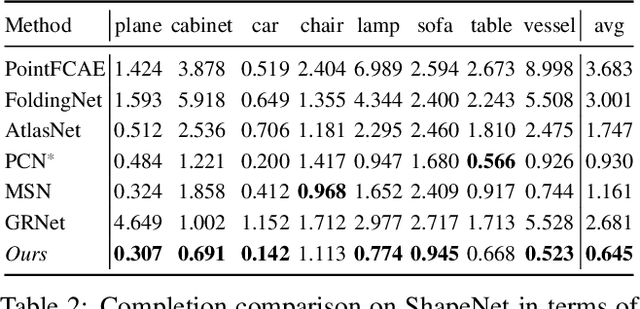
In this paper, we proposed a novel Style-based Point Generator with Adversarial Rendering (SpareNet) for point cloud completion. Firstly, we present the channel-attentive EdgeConv to fully exploit the local structures as well as the global shape in point features. Secondly, we observe that the concatenation manner used by vanilla foldings limits its potential of generating a complex and faithful shape. Enlightened by the success of StyleGAN, we regard the shape feature as style code that modulates the normalization layers during the folding, which considerably enhances its capability. Thirdly, we realize that existing point supervisions, e.g., Chamfer Distance or Earth Mover's Distance, cannot faithfully reflect the perceptual quality of the reconstructed points. To address this, we propose to project the completed points to depth maps with a differentiable renderer and apply adversarial training to advocate the perceptual realism under different viewpoints. Comprehensive experiments on ShapeNet and KITTI prove the effectiveness of our method, which achieves state-of-the-art quantitative performance while offering superior visual quality. Code is available at https://github.com/microsoft/SpareNet.
Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
Jan 28, 2021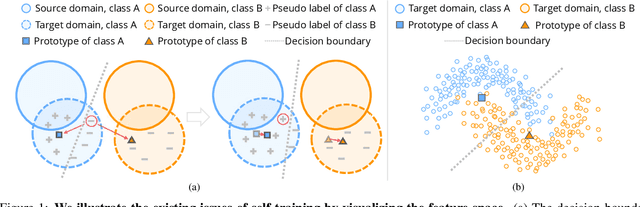
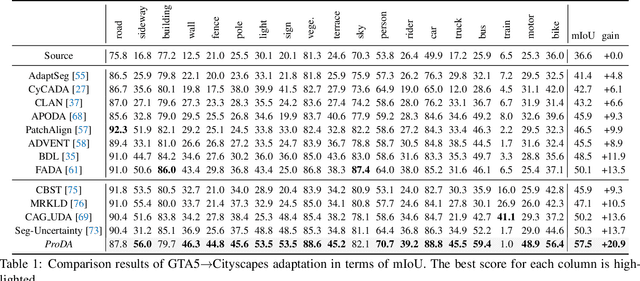
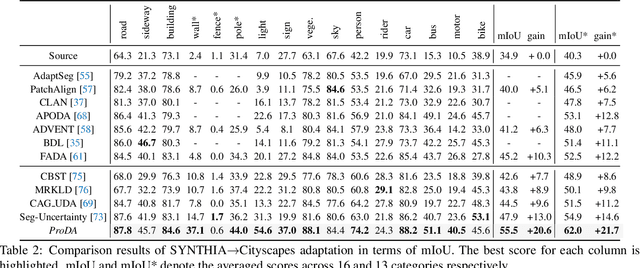
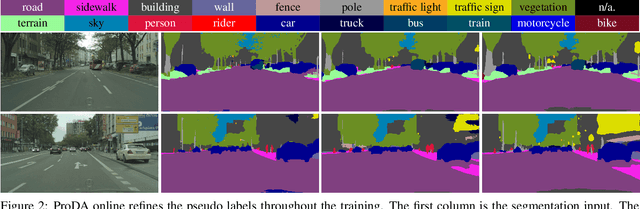
Self-training is a competitive approach in domain adaptive segmentation, which trains the network with the pseudo labels on the target domain. However inevitably, the pseudo labels are noisy and the target features are dispersed due to the discrepancy between source and target domains. In this paper, we rely on representative prototypes, the feature centroids of classes, to address the two issues for unsupervised domain adaptation. In particular, we take one step further and exploit the feature distances from prototypes that provide richer information than mere prototypes. Specifically, we use it to estimate the likelihood of pseudo labels to facilitate online correction in the course of training. Meanwhile, we align the prototypical assignments based on relative feature distances for two different views of the same target, producing a more compact target feature space. Moreover, we find that distilling the already learned knowledge to a self-supervised pretrained model further boosts the performance. Our method shows tremendous performance advantage over state-of-the-art methods. We will make the code publicly available.