 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization Techniques in Training DNNs: Methodology, Analysis and Application
Sep 27, 2020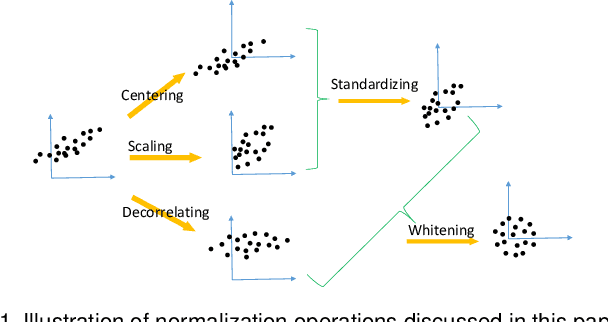
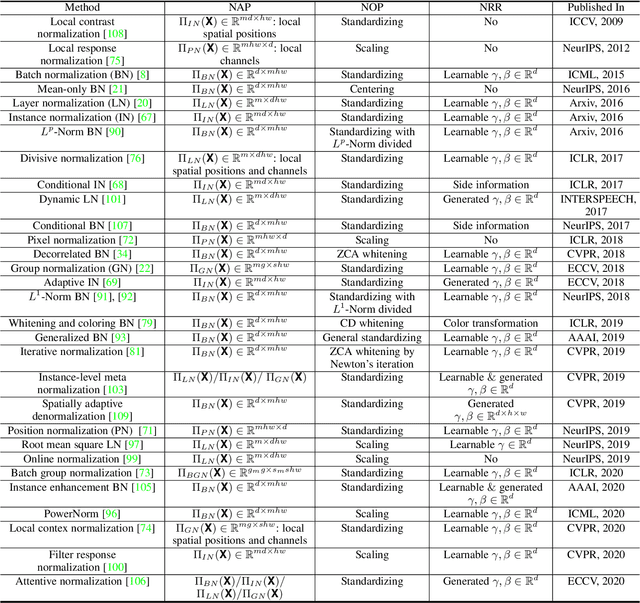
Normalization techniques are essential for accelerating the training and improving the generalization of deep neural networks (DNNs), and have successfully been used in various applications. This paper reviews and comments on the past, present and future of normalization methods in the context of DNN training. We provide a unified picture of the main motivation behind different approaches from the perspective of optimization, and present a taxonomy for understanding the similarities and differences between them. Specifically, we decompose the pipeline of the most representative normalizing activation methods into three components: the normalization area partitioning, normalization operation and normalization representation recovery. In doing so, we provide insight for designing new normalization technique. Finally, we discuss the current progress in understanding normalization methods, and provide a comprehensive review of the applications of normalization for particular tasks, in which it can effectively solve the key issues.
Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
Jun 20, 2020
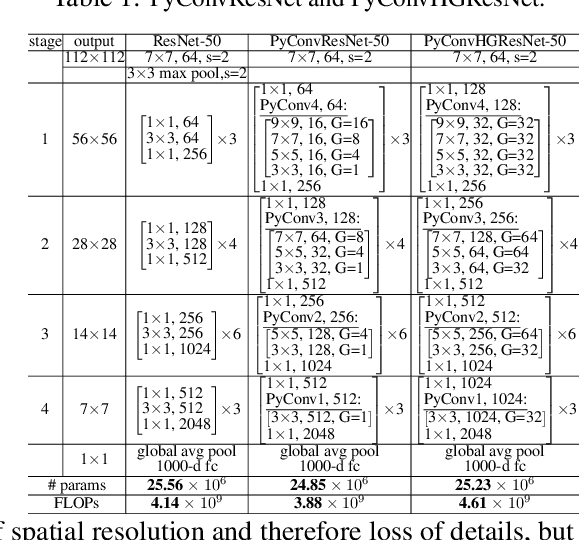
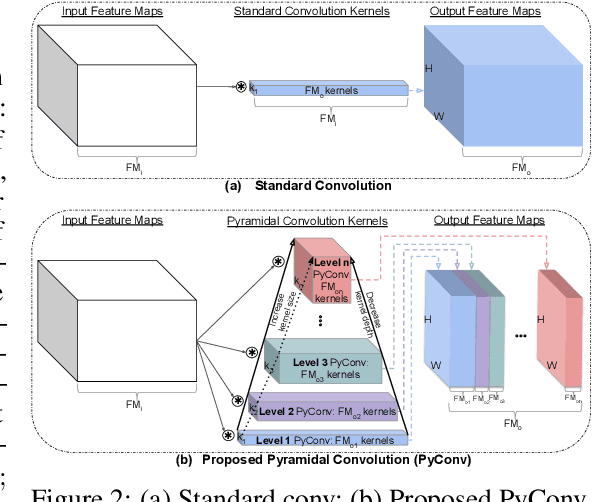

This work introduces pyramidal convolution (PyConv), which is capable of processing the input at multiple filter scales. PyConv contains a pyramid of kernels, where each level involves different types of filters with varying size and depth, which are able to capture different levels of details in the scene. On top of these improved recognition capabilities, PyConv is also efficient and, with our formulation, it does not increase the computational cost and parameters compared to standard convolution. Moreover, it is very flexible and extensible, providing a large space of potential network architectures for different applications. PyConv has the potential to impact nearly every computer vision task and, in this work, we present different architectures based on PyConv for four main tasks on visual recognition: image classification, video action classification/recognition, object detection and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baselines. For instance, on image recognition, our 50-layers network outperforms in terms of recognition performance on ImageNet dataset its counterpart baseline ResNet with 152 layers, while having 2.39 times less parameters, 2.52 times lower computational complexity and more than 3 times less layers. On image segmentation, our novel framework sets a new state-of-the-art on the challenging ADE20K benchmark for scene parsing. Code is available at: https://github.com/iduta/pyconv
Improved Residual Networks for Image and Video Recognition
Apr 10, 2020
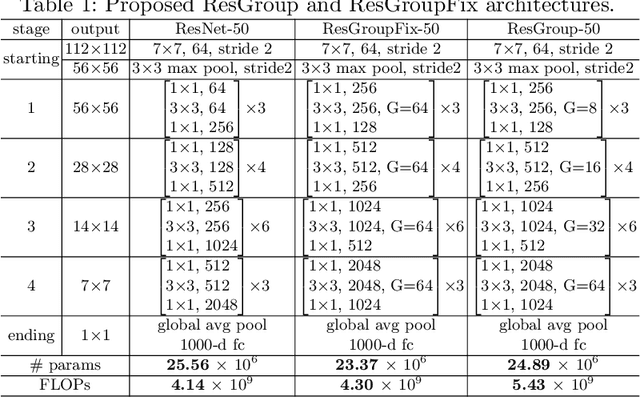
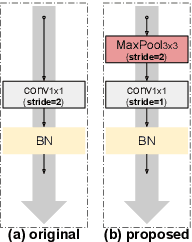
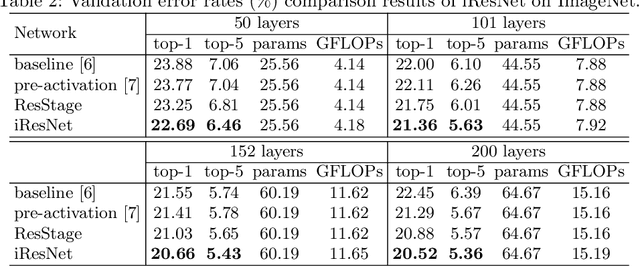
Residual networks (ResNets) represent a powerful type of convolutional neural network (CNN) architecture, widely adopted and used in various tasks. In this work we propose an improved version of ResNets. Our proposed improvements address all three main components of a ResNet: the flow of information through the network layers, the residual building block, and the projection shortcut. We are able to show consistent improvements in accuracy and learning convergence over the baseline. For instance, on ImageNet dataset, using the ResNet with 50 layers, for top-1 accuracy we can report a 1.19% improvement over the baseline in one setting and around 2% boost in another. Importantly, these improvements are obtained without increasing the model complexity. Our proposed approach allows us to train extremely deep networks, while the baseline shows severe optimization issues. We report results on three tasks over six datasets: image classification (ImageNet, CIFAR-10 and CIFAR-100), object detection (COCO) and video action recognition (Kinetics-400 and Something-Something-v2). In the deep learning era, we establish a new milestone for the depth of a CNN. We successfully train a 404-layer deep CNN on the ImageNet dataset and a 3002-layer network on CIFAR-10 and CIFAR-100, while the baseline is not able to converge at such extreme depths. Code is available at: https://github.com/iduta/iresnet
Controllable Orthogonalization in Training DNNs
Apr 02, 2020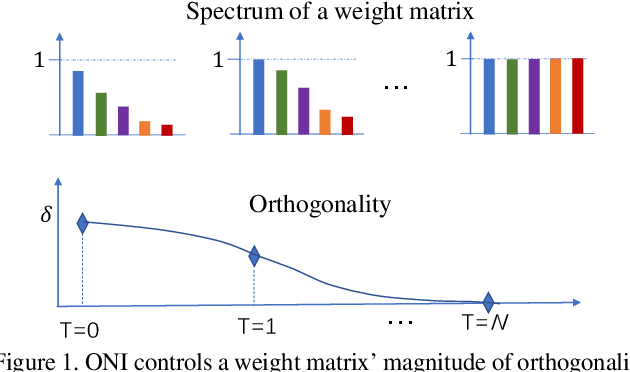
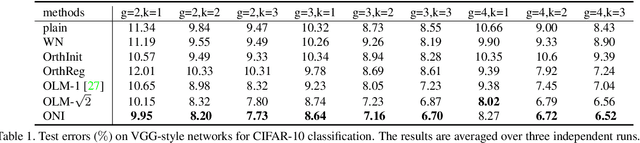
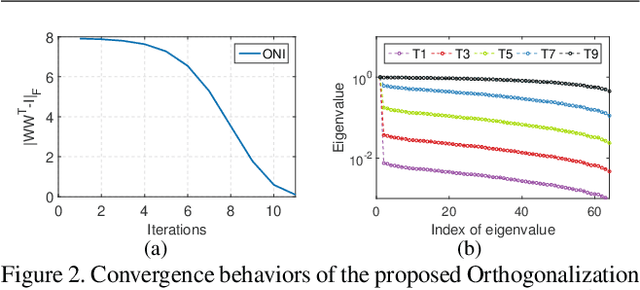

Orthogonality is widely used for training deep neural networks (DNNs) due to its ability to maintain all singular values of the Jacobian close to 1 and reduce redundancy in representation. This paper proposes a computationally efficient and numerically stable orthogonalization method using Newton's iteration (ONI), to learn a layer-wise orthogonal weight matrix in DNNs. ONI works by iteratively stretching the singular values of a weight matrix towards 1. This property enables it to control the orthogonality of a weight matrix by its number of iterations. We show that our method improves the performance of image classification networks by effectively controlling the orthogonality to provide an optimal tradeoff between optimization benefits and representational capacity reduction. We also show that ONI stabilizes the training of generative adversarial networks (GANs) by maintaining the Lipschitz continuity of a network, similar to spectral normalization (SN), and further outperforms SN by providing controllable orthogonality.
An Investigation into the Stochasticity of Batch Whitening
Mar 27, 2020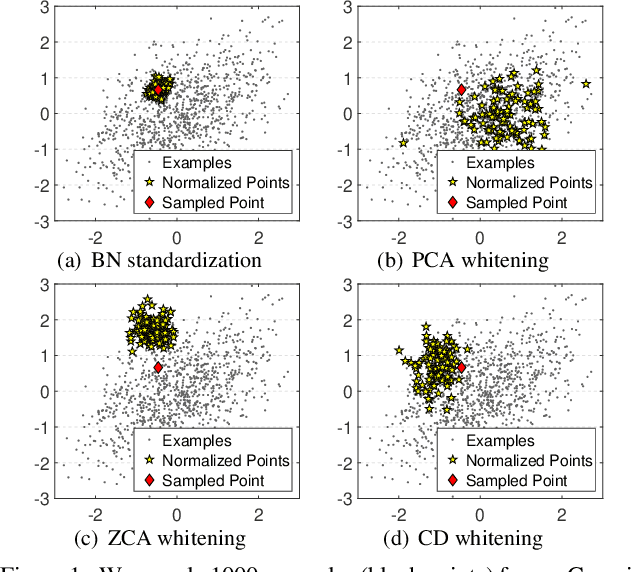
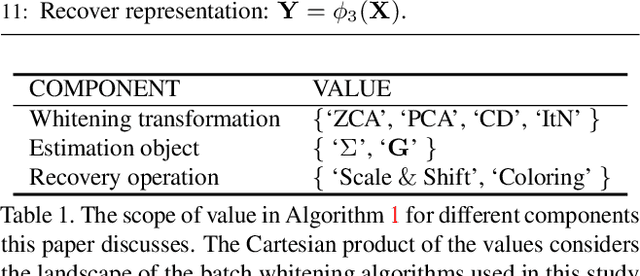
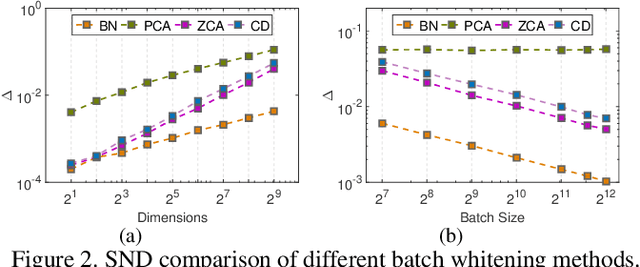
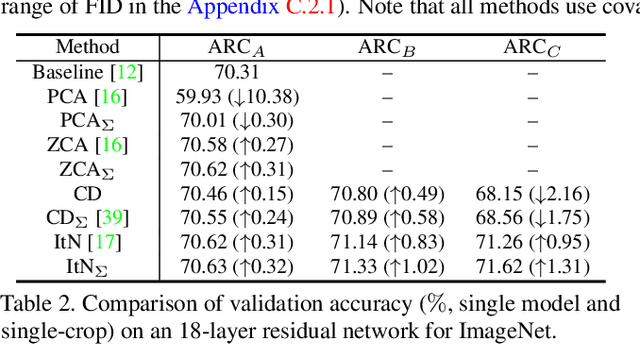
Batch Normalization (BN) is extensively employed in various network architectures by performing standardization within mini-batches. A full understanding of the process has been a central target in the deep learning communities. Unlike existing works, which usually only analyze the standardization operation, this paper investigates the more general Batch Whitening (BW). Our work originates from the observation that while various whitening transformations equivalently improve the conditioning, they show significantly different behaviors in discriminative scenarios and training Generative Adversarial Networks (GANs). We attribute this phenomenon to the stochasticity that BW introduces. We quantitatively investigate the stochasticity of different whitening transformations and show that it correlates well with the optimization behaviors during training. We also investigate how stochasticity relates to the estimation of population statistics during inference. Based on our analysis, we provide a framework for designing and comparing BW algorithms in different scenarios. Our proposed BW algorithm improves the residual networks by a significant margin on ImageNet classification. Besides, we show that the stochasticity of BW can improve the GAN's performance with, however, the sacrifice of the training stability.
Auto-Encoding Twin-Bottleneck Hashing
Mar 16, 2020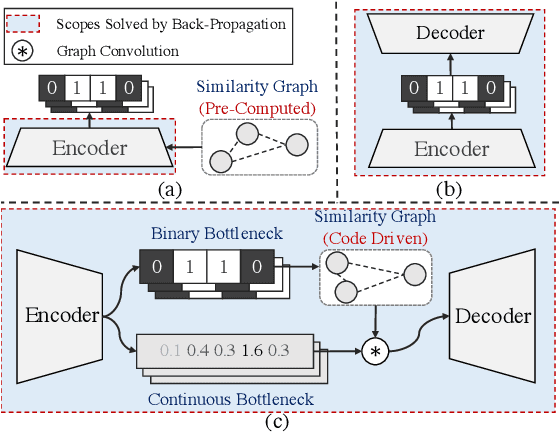
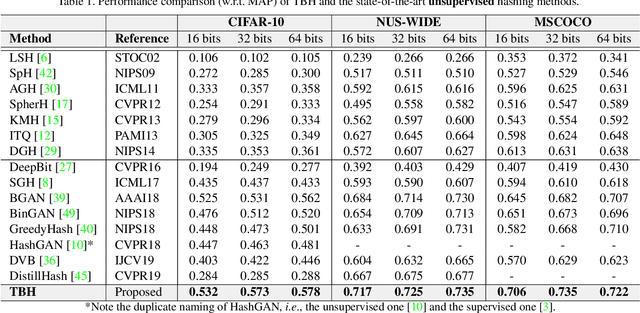
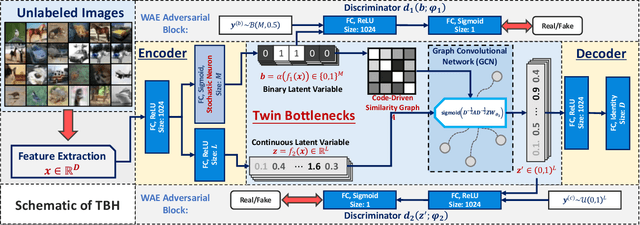
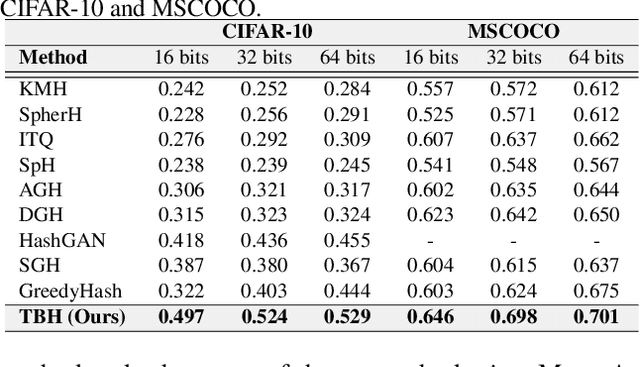
Conventional unsupervised hashing methods usually take advantage of similarity graphs, which are either pre-computed in the high-dimensional space or obtained from random anchor points. On the one hand, existing methods uncouple the procedures of hash function learning and graph construction. On the other hand, graphs empirically built upon original data could introduce biased prior knowledge of data relevance, leading to sub-optimal retrieval performance. In this paper, we tackle the above problems by proposing an efficient and adaptive code-driven graph, which is updated by decoding in the context of an auto-encoder. Specifically, we introduce into our framework twin bottlenecks (i.e., latent variables) that exchange crucial information collaboratively. One bottleneck (i.e., binary codes) conveys the high-level intrinsic data structure captured by the code-driven graph to the other (i.e., continuous variables for low-level detail information), which in turn propagates the updated network feedback for the encoder to learn more discriminative binary codes. The auto-encoding learning objective literally rewards the code-driven graph to learn an optimal encoder. Moreover, the proposed model can be simply optimized by gradient descent without violating the binary constraints. Experiments on benchmarked datasets clearly show the superiority of our framework over the state-of-the-art hashing methods. Our source code can be found at https://github.com/ymcidence/TBH.
Layer-wise Conditioning Analysis in Exploring the Learning Dynamics of DNNs
Mar 11, 2020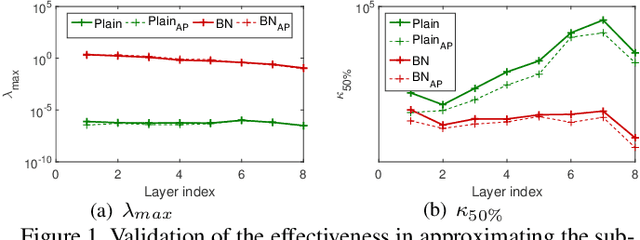

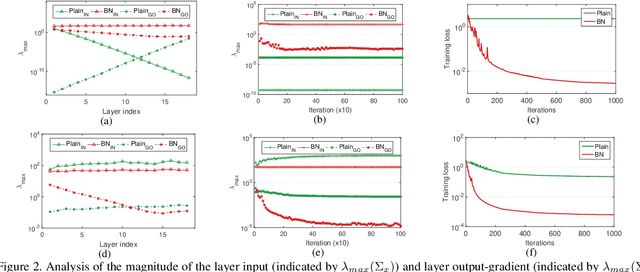

Conditioning analysis uncovers the landscape of an optimization objective by exploring the spectrum of its curvature matrix. This has been well explored theoretically for linear models. We extend this analysis to deep neural networks (DNNs) in order to investigate their learning dynamics. To this end, we propose layer-wise conditioning analysis, which explores the optimization landscape with respect to each layer independently. Such an analysis is theoretically supported under mild assumptions that approximately hold in practice. Based on our analysis, we show that batch normalization (BN) can stabilize the training, but sometimes result in the false impression of a local minimum, which has detrimental effects on the learning. Besides, we experimentally observe that BN can improve the layer-wise conditioning of the optimization problem. Finally, we find that the last linear layer of a very deep residual network displays ill-conditioned behavior. We solve this problem by only adding one BN layer before the last linear layer, which achieves improved performance over the original and pre-activation residual networks.
DR-GAN: Conditional Generative Adversarial Network for Fine-Grained Lesion Synthesis on Diabetic Retinopathy Images
Dec 10, 2019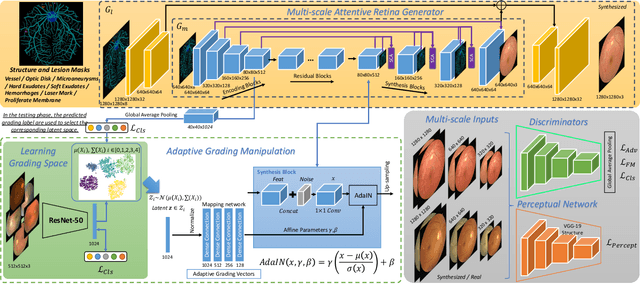
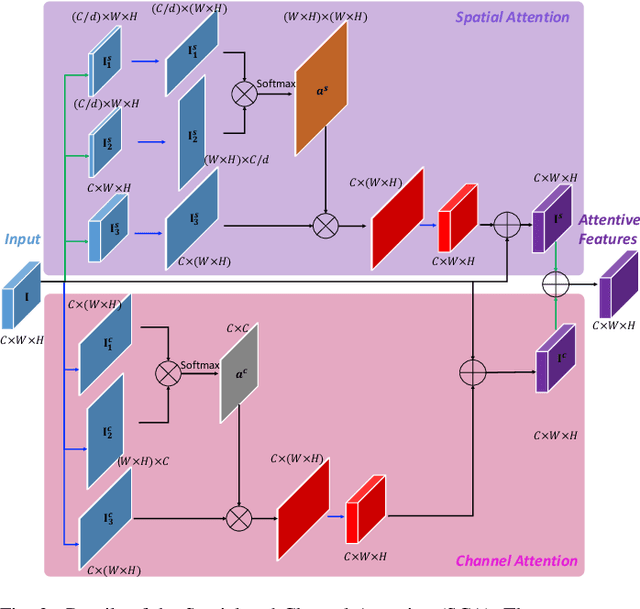
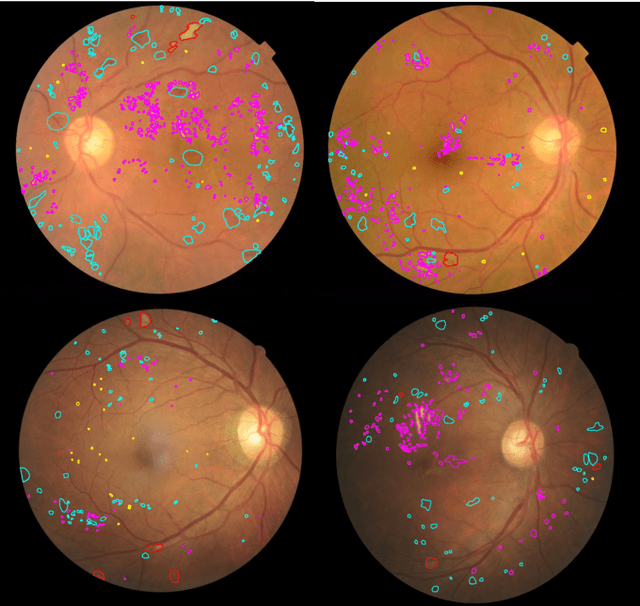
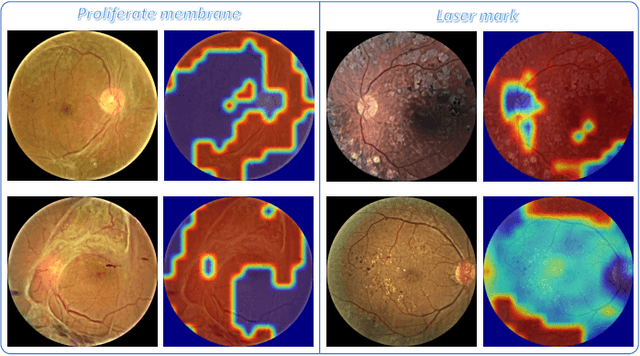
Diabetic retinopathy (DR) is a complication of diabetes that severely affects eyes. It can be graded into five levels of severity according to international protocol. However, optimizing a grading model to have strong generalizability requires a large amount of balanced training data, which is difficult to collect particularly for the high severity levels. Typical data augmentation methods, including random flipping and rotation, cannot generate data with high diversity. In this paper, we propose a diabetic retinopathy generative adversarial network (DR-GAN) to synthesize high-resolution fundus images which can be manipulated with arbitrary grading and lesion information. Thus, large-scale generated data can be used for more meaningful augmentation to train a DR grading and lesion segmentation model. The proposed retina generator is conditioned on the structural and lesion masks, as well as adaptive grading vectors sampled from the latent grading space, which can be adopted to control the synthesized grading severity. Moreover, a multi-scale spatial and channel attention module is devised to improve the generation ability to synthesize details. Multi-scale discriminators are designed to operate from large to small receptive fields, and joint adversarial losses are adopted to optimize the whole network in an end-to-end manner. With extensive experiments evaluated on the EyePACS dataset connected to Kaggle, as well as our private dataset (SKA - will be released once get official permission), we validate the effectiveness of our method, which can both synthesize highly realistic (1280 x 1280) controllable fundus images and contribute to the DR grading task.
Fast Large-Scale Discrete Optimization Based on Principal Coordinate Descent
Sep 16, 2019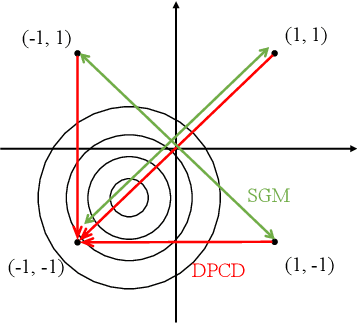
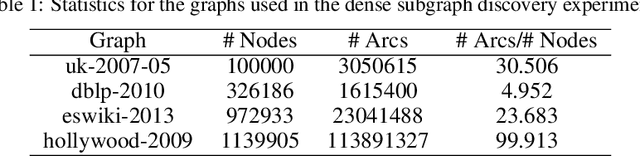
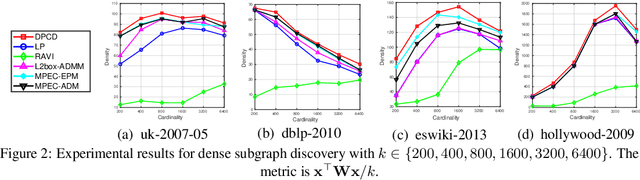
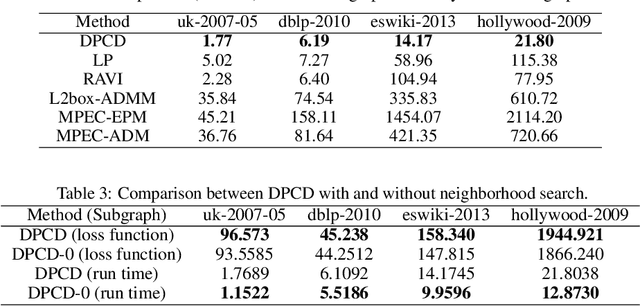
Binary optimization, a representative subclass of discrete optimization, plays an important role in mathematical optimization and has various applications in computer vision and machine learning. Usually, binary optimization problems are NP-hard and difficult to solve due to the binary constraints, especially when the number of variables is very large. Existing methods often suffer from high computational costs or large accumulated quantization errors, or are only designed for specific tasks. In this paper, we propose a fast algorithm to find effective approximate solutions for general binary optimization problems. The proposed algorithm iteratively solves minimization problems related to the linear surrogates of loss functions, which leads to the updating of some binary variables most impacting the value of loss functions in each step. Our method supports a wide class of empirical objective functions with/without restrictions on the numbers of $1$s and $-1$s in the binary variables. Furthermore, the theoretical convergence of our algorithm is proven, and the explicit convergence rates are derived, for objective functions with Lipschitz continuous gradients, which are commonly adopted in practice. Extensive experiments on several binary optimization tasks and large-scale datasets demonstrate the superiority of the proposed algorithm over several state-of-the-art methods in terms of both effectiveness and efficiency.
RANet: Ranking Attention Network for Fast Video Object Segmentation
Sep 08, 2019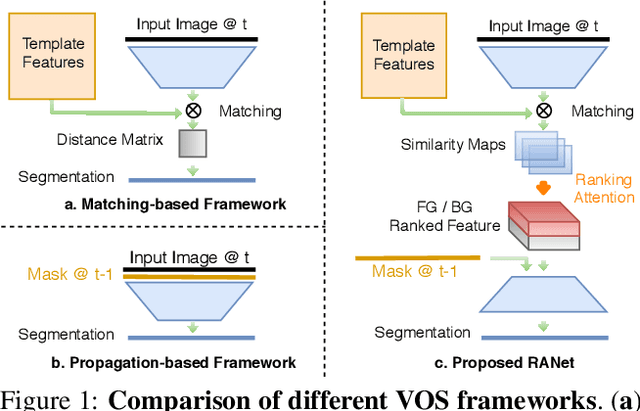
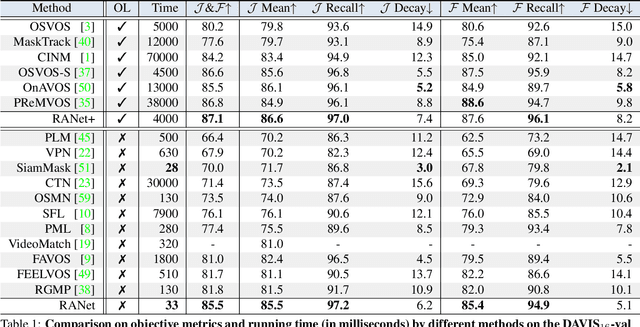
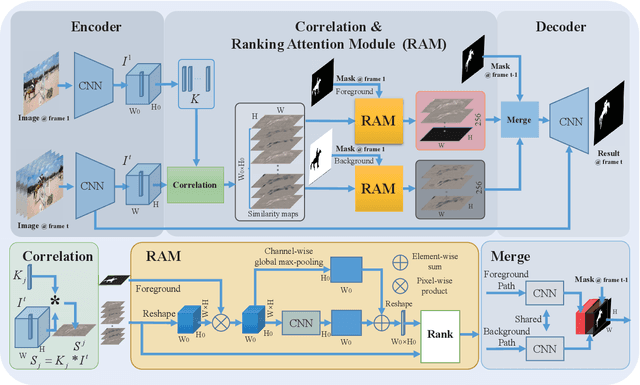
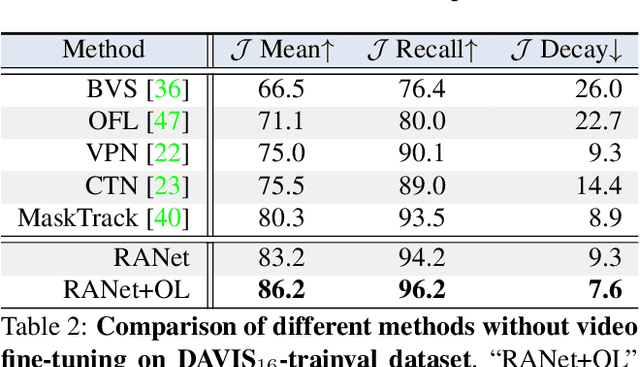
Despite online learning (OL) techniques have boosted the performance of semi-supervised video object segmentation (VOS) methods, the huge time costs of OL greatly restrict their practicality. Matching based and propagation based methods run at a faster speed by avoiding OL techniques. However, they are limited by sub-optimal accuracy, due to mismatching and drifting problems. In this paper, we develop a real-time yet very accurate Ranking Attention Network (RANet) for VOS. Specifically, to integrate the insights of matching based and propagation based methods, we employ an encoder-decoder framework to learn pixel-level similarity and segmentation in an end-to-end manner. To better utilize the similarity maps, we propose a novel ranking attention module, which automatically ranks and selects these maps for fine-grained VOS performance. Experiments on DAVIS-16 and DAVIS-17 datasets show that our RANet achieves the best speed-accuracy trade-off, e.g., with 33 milliseconds per frame and J&F=85.5% on DAVIS-16. With OL, our RANet reaches J&F=87.1% on DAVIS-16, exceeding state-of-the-art VOS methods. The code can be found at https://github.com/Storife/RANet.