 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer
Paper and Code
Aug 18, 2025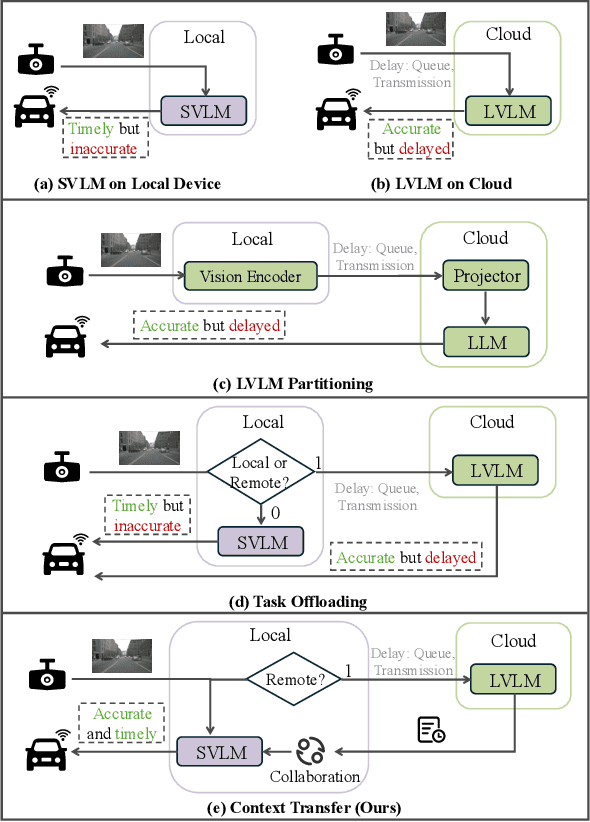
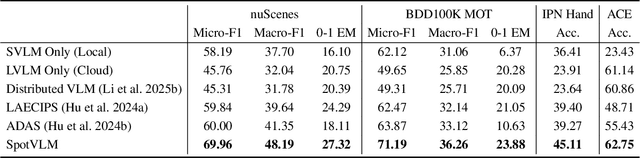
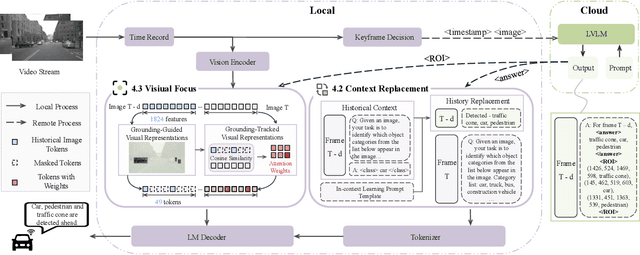
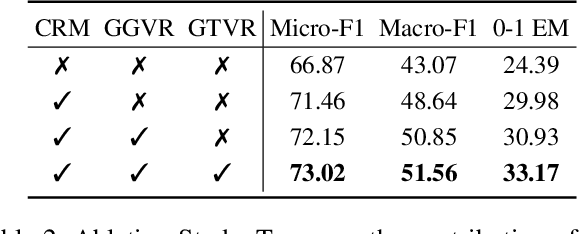
Vision-Language Models (VLMs) are increasingly deployed in real-time applications such as autonomous driving and human-computer interaction, which demand fast and reliable responses based on accurate perception. To meet these requirements, existing systems commonly employ cloud-edge collaborative architectures, such as partitioned Large Vision-Language Models (LVLMs) or task offloading strategies between Large and Small Vision-Language Models (SVLMs). However, these methods fail to accommodate cloud latency fluctuations and overlook the full potential of delayed but accurate LVLM responses. In this work, we propose a novel cloud-edge collaborative paradigm for VLMs, termed Context Transfer, which treats the delayed outputs of LVLMs as historical context to provide real-time guidance for SVLMs inference. Based on this paradigm, we design SpotVLM, which incorporates both context replacement and visual focus modules to refine historical textual input and enhance visual grounding consistency. Extensive experiments on three real-time vision tasks across four datasets demonstrate the effectiveness of the proposed framework. The new paradigm lays the groundwork for more effective and latency-aware collaboration strategies in future VLM systems.