 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftVLM: Efficient Vision-Language Model Inference via Cross-Layer Token Bypass
Feb 03, 2026Visual token pruning is a promising approach for reducing the computational cost of vision-language models (VLMs), and existing methods often rely on early pruning decisions to improve efficiency. While effective on coarse-grained reasoning tasks, they suffer from significant performance degradation on tasks requiring fine-grained visual details. Through layer-wise analysis, we reveal substantial discrepancies in visual token importance across layers, showing that tokens deemed unimportant at shallow layers can later become highly relevant for text-conditioned reasoning. To avoid irreversible critical information loss caused by premature pruning, we introduce a new pruning paradigm, termed bypass, which preserves unselected visual tokens and forwards them to subsequent pruning stages for re-evaluation. Building on this paradigm, we propose SwiftVLM, a simple and training-free method that performs pruning at model-specific layers with strong visual token selection capability, while enabling independent pruning decisions across layers. Experiments across multiple VLMs and benchmarks demonstrate that SwiftVLM consistently outperforms existing pruning strategies, achieving superior accuracy-efficiency trade-offs and more faithful visual token selection behavior.
SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer
Aug 18, 2025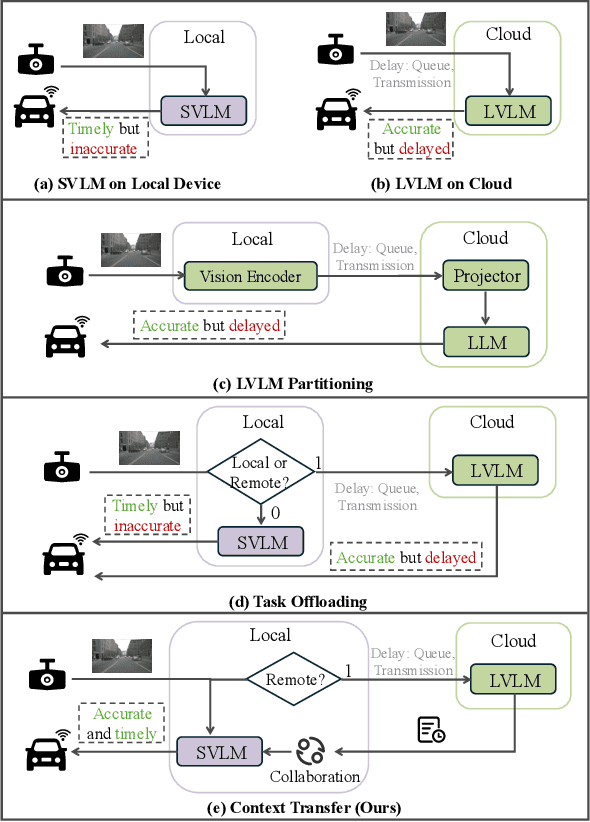
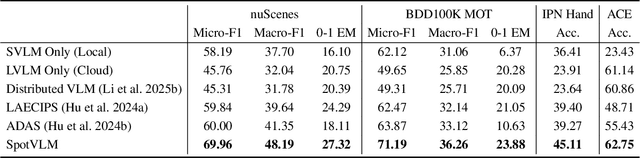
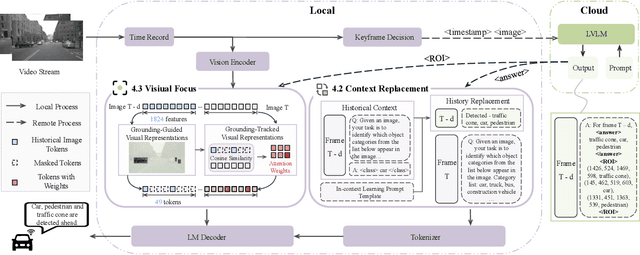
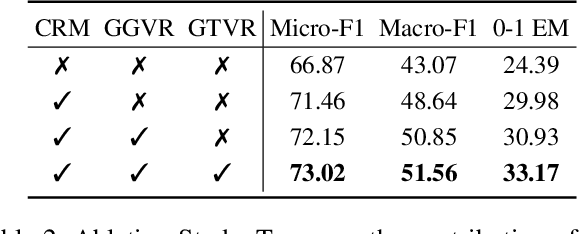
Vision-Language Models (VLMs) are increasingly deployed in real-time applications such as autonomous driving and human-computer interaction, which demand fast and reliable responses based on accurate perception. To meet these requirements, existing systems commonly employ cloud-edge collaborative architectures, such as partitioned Large Vision-Language Models (LVLMs) or task offloading strategies between Large and Small Vision-Language Models (SVLMs). However, these methods fail to accommodate cloud latency fluctuations and overlook the full potential of delayed but accurate LVLM responses. In this work, we propose a novel cloud-edge collaborative paradigm for VLMs, termed Context Transfer, which treats the delayed outputs of LVLMs as historical context to provide real-time guidance for SVLMs inference. Based on this paradigm, we design SpotVLM, which incorporates both context replacement and visual focus modules to refine historical textual input and enhance visual grounding consistency. Extensive experiments on three real-time vision tasks across four datasets demonstrate the effectiveness of the proposed framework. The new paradigm lays the groundwork for more effective and latency-aware collaboration strategies in future VLM systems.
OpenMoCap: Rethinking Optical Motion Capture under Real-world Occlusion
Aug 18, 2025Optical motion capture is a foundational technology driving advancements in cutting-edge fields such as virtual reality and film production. However, system performance suffers severely under large-scale marker occlusions common in real-world applications. An in-depth analysis identifies two primary limitations of current models: (i) the lack of training datasets accurately reflecting realistic marker occlusion patterns, and (ii) the absence of training strategies designed to capture long-range dependencies among markers. To tackle these challenges, we introduce the CMU-Occlu dataset, which incorporates ray tracing techniques to realistically simulate practical marker occlusion patterns. Furthermore, we propose OpenMoCap, a novel motion-solving model designed specifically for robust motion capture in environments with significant occlusions. Leveraging a marker-joint chain inference mechanism, OpenMoCap enables simultaneous optimization and construction of deep constraints between markers and joints. Extensive comparative experiments demonstrate that OpenMoCap consistently outperforms competing methods across diverse scenarios, while the CMU-Occlu dataset opens the door for future studies in robust motion solving. The proposed OpenMoCap is integrated into the MoSen MoCap system for practical deployment. The code is released at: https://github.com/qianchen214/OpenMoCap.
A Dual-domain Regularization Method for Ring Artifact Removal of X-ray CT
Mar 15, 2024



Ring artifacts in computed tomography images, arising from the undesirable responses of detector units, significantly degrade image quality and diagnostic reliability. To address this challenge, we propose a dual-domain regularization model to effectively remove ring artifacts, while maintaining the integrity of the original CT image. The proposed model corrects the vertical stripe artifacts on the sinogram by innovatively updating the response inconsistency compensation coefficients of detector units, which is achieved by employing the group sparse constraint and the projection-view direction sparse constraint on the stripe artifacts. Simultaneously, we apply the sparse constraint on the reconstructed image to further rectified ring artifacts in the image domain. The key advantage of the proposed method lies in considering the relationship between the response inconsistency compensation coefficients of the detector units and the projection views, which enables a more accurate correction of the response of the detector units. An alternating minimization method is designed to solve the model. Comparative experiments on real photon counting detector data demonstrate that the proposed method not only surpasses existing methods in removing ring artifacts but also excels in preserving structural details and image fidelity.