 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOPHY: Generating Simulation-Ready Objects with Physical Materials
Apr 17, 2025We present SOPHY, a generative model for 3D physics-aware shape synthesis. Unlike existing 3D generative models that focus solely on static geometry or 4D models that produce physics-agnostic animations, our approach jointly synthesizes shape, texture, and material properties related to physics-grounded dynamics, making the generated objects ready for simulations and interactive, dynamic environments. To train our model, we introduce a dataset of 3D objects annotated with detailed physical material attributes, along with an annotation pipeline for efficient material annotation. Our method enables applications such as text-driven generation of interactive, physics-aware 3D objects and single-image reconstruction of physically plausible shapes. Furthermore, our experiments demonstrate that jointly modeling shape and material properties enhances the realism and fidelity of generated shapes, improving performance on generative geometry evaluation metrics.
Mean-Shift Distillation for Diffusion Mode Seeking
Feb 21, 2025We present mean-shift distillation, a novel diffusion distillation technique that provides a provably good proxy for the gradient of the diffusion output distribution. This is derived directly from mean-shift mode seeking on the distribution, and we show that its extrema are aligned with the modes. We further derive an efficient product distribution sampling procedure to evaluate the gradient. Our method is formulated as a drop-in replacement for score distillation sampling (SDS), requiring neither model retraining nor extensive modification of the sampling procedure. We show that it exhibits superior mode alignment as well as improved convergence in both synthetic and practical setups, yielding higher-fidelity results when applied to both text-to-image and text-to-3D applications with Stable Diffusion.
ShapeWords: Guiding Text-to-Image Synthesis with 3D Shape-Aware Prompts
Dec 03, 2024



We introduce ShapeWords, an approach for synthesizing images based on 3D shape guidance and text prompts. ShapeWords incorporates target 3D shape information within specialized tokens embedded together with the input text, effectively blending 3D shape awareness with textual context to guide the image synthesis process. Unlike conventional shape guidance methods that rely on depth maps restricted to fixed viewpoints and often overlook full 3D structure or textual context, ShapeWords generates diverse yet consistent images that reflect both the target shape's geometry and the textual description. Experimental results show that ShapeWords produces images that are more text-compliant, aesthetically plausible, while also maintaining 3D shape awareness.
DELTA: Dense Efficient Long-range 3D Tracking for any video
Oct 31, 2024Tracking dense 3D motion from monocular videos remains challenging, particularly when aiming for pixel-level precision over long sequences. We introduce \Approach, a novel method that efficiently tracks every pixel in 3D space, enabling accurate motion estimation across entire videos. Our approach leverages a joint global-local attention mechanism for reduced-resolution tracking, followed by a transformer-based upsampler to achieve high-resolution predictions. Unlike existing methods, which are limited by computational inefficiency or sparse tracking, \Approach delivers dense 3D tracking at scale, running over 8x faster than previous methods while achieving state-of-the-art accuracy. Furthermore, we explore the impact of depth representation on tracking performance and identify log-depth as the optimal choice. Extensive experiments demonstrate the superiority of \Approach on multiple benchmarks, achieving new state-of-the-art results in both 2D and 3D dense tracking tasks. Our method provides a robust solution for applications requiring fine-grained, long-term motion tracking in 3D space.
NIVeL: Neural Implicit Vector Layers for Text-to-Vector Generation
May 24, 2024



The success of denoising diffusion models in representing rich data distributions over 2D raster images has prompted research on extending them to other data representations, such as vector graphics. Unfortunately due to their variable structure and scarcity of vector training data, directly applying diffusion models on this domain remains a challenging problem. Using workarounds like optimization via Score Distillation Sampling (SDS) is also fraught with difficulty, as vector representations are non trivial to directly optimize and tend to result in implausible geometries such as redundant or self-intersecting shapes. NIVeL addresses these challenges by reinterpreting the problem on an alternative, intermediate domain which preserves the desirable properties of vector graphics -- mainly sparsity of representation and resolution-independence. This alternative domain is based on neural implicit fields expressed in a set of decomposable, editable layers. Based on our experiments, NIVeL produces text-to-vector graphics results of significantly better quality than the state-of-the-art.
GEM3D: GEnerative Medial Abstractions for 3D Shape Synthesis
Feb 26, 2024



We introduce GEM3D -- a new deep, topology-aware generative model of 3D shapes. The key ingredient of our method is a neural skeleton-based representation encoding information on both shape topology and geometry. Through a denoising diffusion probabilistic model, our method first generates skeleton-based representations following the Medial Axis Transform (MAT), then generates surfaces through a skeleton-driven neural implicit formulation. The neural implicit takes into account the topological and geometric information stored in the generated skeleton representations to yield surfaces that are more topologically and geometrically accurate compared to previous neural field formulations. We discuss applications of our method in shape synthesis and point cloud reconstruction tasks, and evaluate our method both qualitatively and quantitatively. We demonstrate significantly more faithful surface reconstruction and diverse shape generation results compared to the state-of-the-art, also involving challenging scenarios of reconstructing and synthesizing structurally complex, high-genus shape surfaces from Thingi10K and ShapeNet.
Open3DIS: Open-vocabulary 3D Instance Segmentation with 2D Mask Guidance
Dec 17, 2023



We introduce Open3DIS, a novel solution designed to tackle the problem of Open-Vocabulary Instance Segmentation within 3D scenes. Objects within 3D environments exhibit diverse shapes, scales, and colors, making precise instance-level identification a challenging task. Recent advancements in Open-Vocabulary scene understanding have made significant strides in this area by employing class-agnostic 3D instance proposal networks for object localization and learning queryable features for each 3D mask. While these methods produce high-quality instance proposals, they struggle with identifying small-scale and geometrically ambiguous objects. The key idea of our method is a new module that aggregates 2D instance masks across frames and maps them to geometrically coherent point cloud regions as high-quality object proposals addressing the above limitations. These are then combined with 3D class-agnostic instance proposals to include a wide range of objects in the real world. To validate our approach, we conducted experiments on three prominent datasets, including ScanNet200, S3DIS, and Replica, demonstrating significant performance gains in segmenting objects with diverse categories over the state-of-the-art approaches.
VecFusion: Vector Font Generation with Diffusion
Dec 16, 2023



We present VecFusion, a new neural architecture that can generate vector fonts with varying topological structures and precise control point positions. Our approach is a cascaded diffusion model which consists of a raster diffusion model followed by a vector diffusion model. The raster model generates low-resolution, rasterized fonts with auxiliary control point information, capturing the global style and shape of the font, while the vector model synthesizes vector fonts conditioned on the low-resolution raster fonts from the first stage. To synthesize long and complex curves, our vector diffusion model uses a transformer architecture and a novel vector representation that enables the modeling of diverse vector geometry and the precise prediction of control points. Our experiments show that, in contrast to previous generative models for vector graphics, our new cascaded vector diffusion model generates higher quality vector fonts, with complex structures and diverse styles.
Machine Learning for Automated Mitral Regurgitation Detection from Cardiac Imaging
Oct 07, 2023Mitral regurgitation (MR) is a heart valve disease with potentially fatal consequences that can only be forestalled through timely diagnosis and treatment. Traditional diagnosis methods are expensive, labor-intensive and require clinical expertise, posing a barrier to screening for MR. To overcome this impediment, we propose a new semi-supervised model for MR classification called CUSSP. CUSSP operates on cardiac imaging slices of the 4-chamber view of the heart. It uses standard computer vision techniques and contrastive models to learn from large amounts of unlabeled data, in conjunction with specialized classifiers to establish the first ever automated MR classification system. Evaluated on a test set of 179 labeled -- 154 non-MR and 25 MR -- sequences, CUSSP attains an F1 score of 0.69 and a ROC-AUC score of 0.88, setting the first benchmark result for this new task.
* 12 pages including references and the appendix. 9 Figures, 2 tables. Accepted at MICCAI (Machine Learning for Automated Mitral Regurgitation Detection from Cardiac Imaging) 2023, Link to Springer at https://link.springer.com/chapter/10.1007/978-3-031-43990-2_23
Morig: Motion-aware rigging of character meshes from point clouds
Oct 17, 2022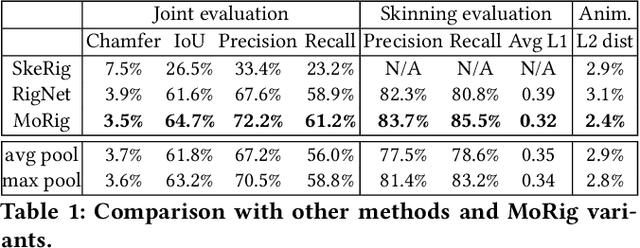
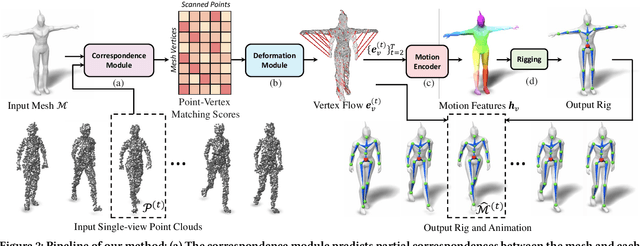
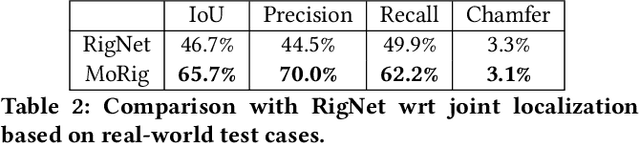

We present MoRig, a method that automatically rigs character meshes driven by single-view point cloud streams capturing the motion of performing characters. Our method is also able to animate the 3D meshes according to the captured point cloud motion. MoRig's neural network encodes motion cues from the point clouds into features that are informative about the articulated parts of the performing character. These motion-aware features guide the inference of an appropriate skeletal rig for the input mesh, which is then animated based on the point cloud motion. Our method can rig and animate diverse characters, including humanoids, quadrupeds, and toys with varying articulation. It accounts for occluded regions in the point clouds and mismatches in the part proportions between the input mesh and captured character. Compared to other rigging approaches that ignore motion cues, MoRig produces more accurate rigs, well-suited for re-targeting motion from captured characters.