 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMonoGS-SLAM: Monocular Gaussian Splatting SLAM with Open-set Semantics
Dec 09, 2025Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.
Multi-view Pyramid Transformer: Look Coarser to See Broader
Dec 08, 2025



We propose Multi-view Pyramid Transformer (MVP), a scalable multi-view transformer architecture that directly reconstructs large 3D scenes from tens to hundreds of images in a single forward pass. Drawing on the idea of ``looking broader to see the whole, looking finer to see the details," MVP is built on two core design principles: 1) a local-to-global inter-view hierarchy that gradually broadens the model's perspective from local views to groups and ultimately the full scene, and 2) a fine-to-coarse intra-view hierarchy that starts from detailed spatial representations and progressively aggregates them into compact, information-dense tokens. This dual hierarchy achieves both computational efficiency and representational richness, enabling fast reconstruction of large and complex scenes. We validate MVP on diverse datasets and show that, when coupled with 3D Gaussian Splatting as the underlying 3D representation, it achieves state-of-the-art generalizable reconstruction quality while maintaining high efficiency and scalability across a wide range of view configurations.
Gather-Scatter Mamba: Accelerating Propagation with Efficient State Space Model
Oct 01, 2025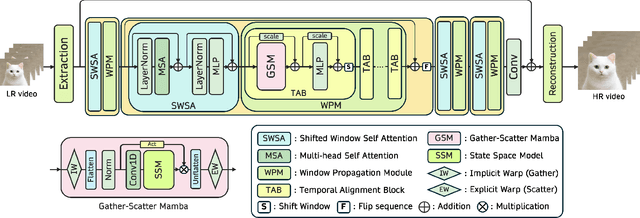
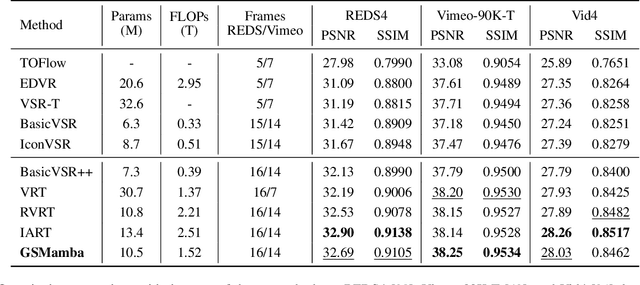
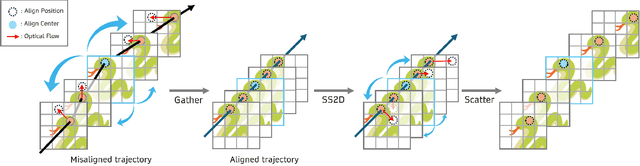
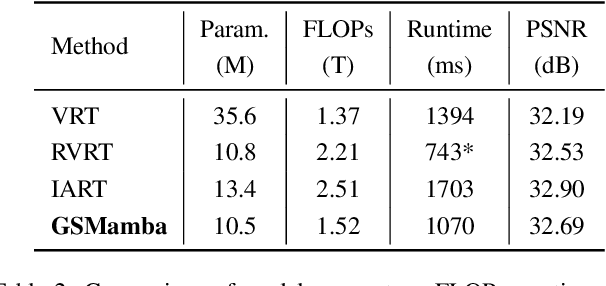
State Space Models (SSMs)-most notably RNNs-have historically played a central role in sequential modeling. Although attention mechanisms such as Transformers have since dominated due to their ability to model global context, their quadratic complexity and limited scalability make them less suited for long sequences. Video super-resolution (VSR) methods have traditionally relied on recurrent architectures to propagate features across frames. However, such approaches suffer from well-known issues including vanishing gradients, lack of parallelism, and slow inference speed. Recent advances in selective SSMs like Mamba offer a compelling alternative: by enabling input-dependent state transitions with linear-time complexity, Mamba mitigates these issues while maintaining strong long-range modeling capabilities. Despite this potential, Mamba alone struggles to capture fine-grained spatial dependencies due to its causal nature and lack of explicit context aggregation. To address this, we propose a hybrid architecture that combines shifted window self-attention for spatial context aggregation with Mamba-based selective scanning for efficient temporal propagation. Furthermore, we introduce Gather-Scatter Mamba (GSM), an alignment-aware mechanism that warps features toward a center anchor frame within the temporal window before Mamba propagation and scatters them back afterward, effectively reducing occlusion artifacts and ensuring effective redistribution of aggregated information across all frames. The official implementation is provided at: https://github.com/Ko-Lani/GSMamba.
Moiré Zero: An Efficient and High-Performance Neural Architecture for Moiré Removal
Jul 30, 2025Moir\'e patterns, caused by frequency aliasing between fine repetitive structures and a camera sensor's sampling process, have been a significant obstacle in various real-world applications, such as consumer photography and industrial defect inspection. With the advancements in deep learning algorithms, numerous studies-predominantly based on convolutional neural networks-have suggested various solutions to address this issue. Despite these efforts, existing approaches still struggle to effectively eliminate artifacts due to the diverse scales, orientations, and color shifts of moir\'e patterns, primarily because the constrained receptive field of CNN-based architectures limits their ability to capture the complex characteristics of moir\'e patterns. In this paper, we propose MZNet, a U-shaped network designed to bring images closer to a 'Moire-Zero' state by effectively removing moir\'e patterns. It integrates three specialized components: Multi-Scale Dual Attention Block (MSDAB) for extracting and refining multi-scale features, Multi-Shape Large Kernel Convolution Block (MSLKB) for capturing diverse moir\'e structures, and Feature Fusion-Based Skip Connection for enhancing information flow. Together, these components enhance local texture restoration and large-scale artifact suppression. Experiments on benchmark datasets demonstrate that MZNet achieves state-of-the-art performance on high-resolution datasets and delivers competitive results on lower-resolution dataset, while maintaining a low computational cost, suggesting that it is an efficient and practical solution for real-world applications. Project page: https://sngryonglee.github.io/MoireZero
Hybrid 3D-4D Gaussian Splatting for Fast Dynamic Scene Representation
May 19, 2025Recent advancements in dynamic 3D scene reconstruction have shown promising results, enabling high-fidelity 3D novel view synthesis with improved temporal consistency. Among these, 4D Gaussian Splatting (4DGS) has emerged as an appealing approach due to its ability to model high-fidelity spatial and temporal variations. However, existing methods suffer from substantial computational and memory overhead due to the redundant allocation of 4D Gaussians to static regions, which can also degrade image quality. In this work, we introduce hybrid 3D-4D Gaussian Splatting (3D-4DGS), a novel framework that adaptively represents static regions with 3D Gaussians while reserving 4D Gaussians for dynamic elements. Our method begins with a fully 4D Gaussian representation and iteratively converts temporally invariant Gaussians into 3D, significantly reducing the number of parameters and improving computational efficiency. Meanwhile, dynamic Gaussians retain their full 4D representation, capturing complex motions with high fidelity. Our approach achieves significantly faster training times compared to baseline 4D Gaussian Splatting methods while maintaining or improving the visual quality.
CompMarkGS: Robust Watermarking for Compression 3D Gaussian Splatting
Mar 17, 20253D Gaussian Splatting (3DGS) enables rapid differentiable rendering for 3D reconstruction and novel view synthesis, leading to its widespread commercial use. Consequently, copyright protection via watermarking has become critical. However, because 3DGS relies on millions of Gaussians, which require gigabytes of storage, efficient transfer and storage require compression. Existing 3DGS watermarking methods are vulnerable to quantization-based compression, often resulting in the loss of the embedded watermark. To address this challenge, we propose a novel watermarking method that ensures watermark robustness after model compression while maintaining high rendering quality. In detail, we incorporate a quantization distortion layer that simulates compression during training, preserving the watermark under quantization-based compression. Also, we propose a learnable watermark embedding feature that embeds the watermark into the anchor feature, ensuring structural consistency and seamless integration into the 3D scene. Furthermore, we present a frequency-aware anchor growing mechanism to enhance image quality in high-frequency regions by effectively identifying Guassians within these regions. Experimental results confirm that our method preserves the watermark and maintains superior image quality under high compression, validating it as a promising approach for a secure 3DGS model.
Generative Physical AI in Vision: A Survey
Jan 19, 2025



Generative Artificial Intelligence (AI) has rapidly advanced the field of computer vision by enabling machines to create and interpret visual data with unprecedented sophistication. This transformation builds upon a foundation of generative models to produce realistic images, videos, and 3D or 4D content. Traditionally, generative models primarily focus on visual fidelity while often neglecting the physical plausibility of generated content. This gap limits their effectiveness in applications requiring adherence to real-world physical laws, such as robotics, autonomous systems, and scientific simulations. As generative AI evolves to increasingly integrate physical realism and dynamic simulation, its potential to function as a "world simulator" expands-enabling the modeling of interactions governed by physics and bridging the divide between virtual and physical realities. This survey systematically reviews this emerging field of physics-aware generative AI in computer vision, categorizing methods based on how they incorporate physical knowledge-either through explicit simulation or implicit learning. We analyze key paradigms, discuss evaluation protocols, and identify future research directions. By offering a comprehensive overview, this survey aims to help future developments in physically grounded generation for vision. The reviewed papers are summarized at https://github.com/BestJunYu/Awesome-Physics-aware-Generation.
Sequence Matters: Harnessing Video Models in Super-Resolution
Dec 16, 20243D super-resolution aims to reconstruct high-fidelity 3D models from low-resolution (LR) multi-view images. Early studies primarily focused on single-image super-resolution (SISR) models to upsample LR images into high-resolution images. However, these methods often lack view consistency because they operate independently on each image. Although various post-processing techniques have been extensively explored to mitigate these inconsistencies, they have yet to fully resolve the issues. In this paper, we perform a comprehensive study of 3D super-resolution by leveraging video super-resolution (VSR) models. By utilizing VSR models, we ensure a higher degree of spatial consistency and can reference surrounding spatial information, leading to more accurate and detailed reconstructions. Our findings reveal that VSR models can perform remarkably well even on sequences that lack precise spatial alignment. Given this observation, we propose a simple yet practical approach to align LR images without involving fine-tuning or generating 'smooth' trajectory from the trained 3D models over LR images. The experimental results show that the surprisingly simple algorithms can achieve the state-of-the-art results of 3D super-resolution tasks on standard benchmark datasets, such as the NeRF-synthetic and MipNeRF-360 datasets. Project page: https://ko-lani.github.io/Sequence-Matters
EditSplat: Multi-View Fusion and Attention-Guided Optimization for View-Consistent 3D Scene Editing with 3D Gaussian Splatting
Dec 16, 2024



Recent advancements in 3D editing have highlighted the potential of text-driven methods in real-time, user-friendly AR/VR applications. However, current methods rely on 2D diffusion models without adequately considering multi-view information, resulting in multi-view inconsistency. While 3D Gaussian Splatting (3DGS) significantly improves rendering quality and speed, its 3D editing process encounters difficulties with inefficient optimization, as pre-trained Gaussians retain excessive source information, hindering optimization. To address these limitations, we propose \textbf{EditSplat}, a novel 3D editing framework that integrates Multi-view Fusion Guidance (MFG) and Attention-Guided Trimming (AGT). Our MFG ensures multi-view consistency by incorporating essential multi-view information into the diffusion process, leveraging classifier-free guidance from the text-to-image diffusion model and the geometric properties of 3DGS. Additionally, our AGT leverages the explicit representation of 3DGS to selectively prune and optimize 3D Gaussians, enhancing optimization efficiency and enabling precise, semantically rich local edits. Through extensive qualitative and quantitative evaluations, EditSplat achieves superior multi-view consistency and editing quality over existing methods, significantly enhancing overall efficiency.
Generative Densification: Learning to Densify Gaussians for High-Fidelity Generalizable 3D Reconstruction
Dec 09, 2024Generalized feed-forward Gaussian models have achieved significant progress in sparse-view 3D reconstruction by leveraging prior knowledge from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be adapted to the feed-forward models, it may not be ideally suited for generalized scenarios. In this paper, we propose Generative Densification, an efficient and generalizable method to densify Gaussians generated by feed-forward models. Unlike the 3D-GS densification strategy, which iteratively splits and clones raw Gaussian parameters, our method up-samples feature representations from the feed-forward models and generates their corresponding fine Gaussians in a single forward pass, leveraging the embedded prior knowledge for enhanced generalization. Experimental results on both object-level and scene-level reconstruction tasks demonstrate that our method outperforms state-of-the-art approaches with comparable or smaller model sizes, achieving notable improvements in representing fine details.