 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGenST-Bench: A Benchmark for Spatio-Temporal Reasoning via Active Video Synthesis
May 21, 2026Spatio-temporal reasoning is a core capability for Multimodal Large Language Models (MLLMs) operating in the real world. As such, evaluating it precisely has become an essential challenge. However, existing spatio-temporal reasoning benchmark datasets primarily rely on static image sets or passively curated video data, which limits the evaluation of fine-grained reasoning capabilities. In this paper, we introduce VGenST-Bench, a video benchmark that employs generative models to actively synthesize highly controlled and diverse evaluation scenarios. To construct VGenST-Bench, we propose a multi-agent pipeline incorporating a human quality control stage, ensuring the quality of all generated videos and QA pairs. We establish a comprehensive 3x2x2 video taxonomy, encompassing Spatial Scale, Perspective, and Scene Dynamics to span diverse scenarios. Furthermore, we design a hierarchical task suite that decouples low-level visual perception from high-level spatio-temporal reasoning. By shifting the paradigm from passive curation to active synthesis, VGenST-Bench enables fine-grained diagnosis of spatio-temporal understanding in MLLMs.
Advancing Multi-Robot Networks via MLLM-Driven Sensing, Communication, and Computation: A Comprehensive Survey
Mar 31, 2026Imagine advanced humanoid robots, powered by multimodal large language models (MLLMs), coordinating missions across industries like warehouse logistics, manufacturing, and safety rescue. While individual robots show local autonomy, realistic tasks demand coordination among multiple agents sharing vast streams of sensor data. Communication is indispensable, yet transmitting comprehensive data can overwhelm networks, especially when a system-level orchestrator or cloud-based MLLM fuses multimodal inputs for route planning or anomaly detection. These tasks are often initiated by high-level natural language instructions. This intent serves as a filter for resource optimization: by understanding the goal via MLLMs, the system can selectively activate relevant sensing modalities, dynamically allocate bandwidth, and determine computation placement. Thus, R2X is fundamentally an intent-to-resource orchestration problem where sensing, communication, and computation are jointly optimized to maximize task-level success under resource constraints. This survey examines how integrated design paves the way for multi-robot coordination under MLLM guidance. We review state-of-the-art sensing modalities, communication strategies, and computing approaches, highlighting how reasoning is split between on-device models and powerful edge/cloud servers. We present four end-to-end demonstrations (sense -> communicate -> compute -> act): (i) digital-twin warehouse navigation with predictive link context, (ii) mobility-driven proactive MCS control, (iii) a FollowMe robot with a semantic-sensing switch, and (iv) real-hardware open-vocabulary trash sorting via edge-assisted MLLM grounding. We emphasize system-level metrics -- payload, latency, and success -- to show why R2X orchestration outperforms purely on-device baselines.
Group3D: MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection
Mar 23, 2026Open-vocabulary 3D object detection aims to localize and recognize objects beyond a fixed training taxonomy. In multi-view RGB settings, recent approaches often decouple geometry-based instance construction from semantic labeling, generating class-agnostic fragments and assigning open-vocabulary categories post hoc. While flexible, such decoupling leaves instance construction governed primarily by geometric consistency, without semantic constraints during merging. When geometric evidence is view-dependent and incomplete, this geometry-only merging can lead to irreversible association errors, including over-merging of distinct objects or fragmentation of a single instance. We propose Group3D, a multi-view open-vocabulary 3D detection framework that integrates semantic constraints directly into the instance construction process. Group3D maintains a scene-adaptive vocabulary derived from a multimodal large language model (MLLM) and organizes it into semantic compatibility groups that encode plausible cross-view category equivalence. These groups act as merge-time constraints: 3D fragments are associated only when they satisfy both semantic compatibility and geometric consistency. This semantically gated merging mitigates geometry-driven over-merging while absorbing multi-view category variability. Group3D supports both pose-known and pose-free settings, relying only on RGB observations. Experiments on ScanNet and ARKitScenes demonstrate that Group3D achieves state-of-the-art performance in multi-view open-vocabulary 3D detection, while exhibiting strong generalization in zero-shot scenarios. The project page is available at https://ubin108.github.io/Group3D/.
Gather-Scatter Mamba: Accelerating Propagation with Efficient State Space Model
Oct 01, 2025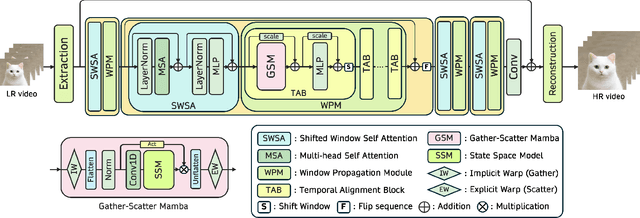
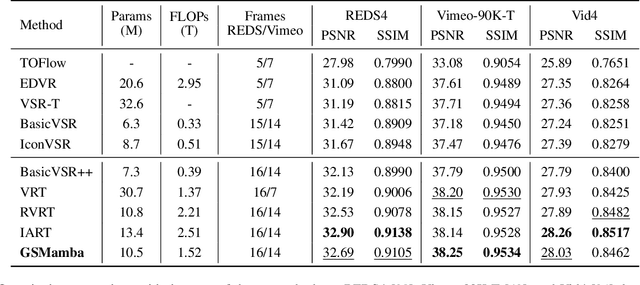
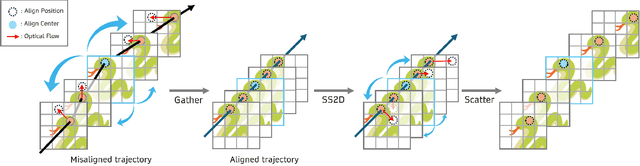
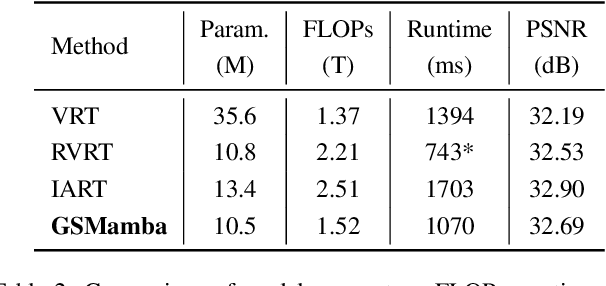
State Space Models (SSMs)-most notably RNNs-have historically played a central role in sequential modeling. Although attention mechanisms such as Transformers have since dominated due to their ability to model global context, their quadratic complexity and limited scalability make them less suited for long sequences. Video super-resolution (VSR) methods have traditionally relied on recurrent architectures to propagate features across frames. However, such approaches suffer from well-known issues including vanishing gradients, lack of parallelism, and slow inference speed. Recent advances in selective SSMs like Mamba offer a compelling alternative: by enabling input-dependent state transitions with linear-time complexity, Mamba mitigates these issues while maintaining strong long-range modeling capabilities. Despite this potential, Mamba alone struggles to capture fine-grained spatial dependencies due to its causal nature and lack of explicit context aggregation. To address this, we propose a hybrid architecture that combines shifted window self-attention for spatial context aggregation with Mamba-based selective scanning for efficient temporal propagation. Furthermore, we introduce Gather-Scatter Mamba (GSM), an alignment-aware mechanism that warps features toward a center anchor frame within the temporal window before Mamba propagation and scatters them back afterward, effectively reducing occlusion artifacts and ensuring effective redistribution of aggregated information across all frames. The official implementation is provided at: https://github.com/Ko-Lani/GSMamba.
MetaFormer: High-fidelity Metalens Imaging via Aberration Correcting Transformers
Dec 05, 2024



Metalens is an emerging optical system with an irreplaceable merit in that it can be manufactured in ultra-thin and compact sizes, which shows great promise of various applications such as medical imaging and augmented/virtual reality (AR/VR). Despite its advantage in miniaturization, its practicality is constrained by severe aberrations and distortions, which significantly degrade the image quality. Several previous arts have attempted to address different types of aberrations, yet most of them are mainly designed for the traditional bulky lens and not convincing enough to remedy harsh aberrations of the metalens. While there have existed aberration correction methods specifically for metalens, they still fall short of restoration quality. In this work, we propose MetaFormer, an aberration correction framework for metalens-captured images, harnessing Vision Transformers (ViT) that has shown remarkable restoration performance in diverse image restoration tasks. Specifically, we devise a Multiple Adaptive Filters Guidance (MAFG), where multiple Wiener filters enrich the degraded input images with various noise-detail balances, enhancing output restoration quality. In addition, we introduce a Spatial and Transposed self-Attention Fusion (STAF) module, which aggregates features from spatial self-attention and transposed self-attention modules to further ameliorate aberration correction. We conduct extensive experiments, including correcting aberrated images and videos, and clean 3D reconstruction from the degraded images. The proposed method outperforms the previous arts by a significant margin. We further fabricate a metalens and verify the practicality of MetaFormer by restoring the images captured with the manufactured metalens in the wild. Code and pre-trained models are available at https://benhenryl.github.io/MetaFormer
Printable Hydraulics: A Method for Fabricating Robots by 3D Co-Printing Solids and Liquids
Dec 18, 2015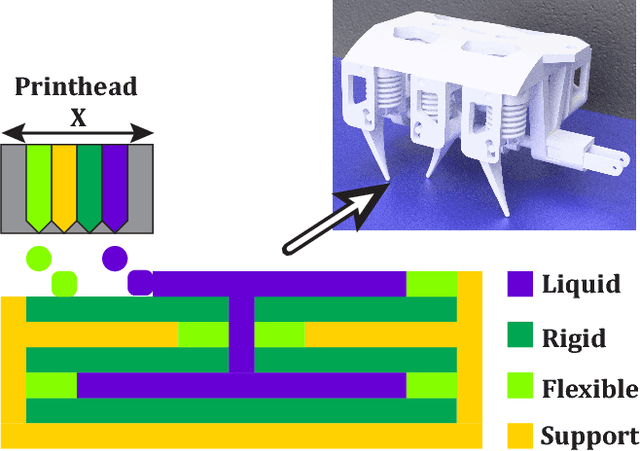



This work introduces a novel technique for fabricating functional robots using 3D printers. Simultaneously depositing photopolymers and a non-curing liquid allows complex, pre-filled fluidic channels to be fabricated. This new printing capability enables complex hydraulically actuated robots and robotic components to be automatically built, with no assembly required. The technique is showcased by printing linear bellows actuators, gear pumps, soft grippers and a hexapod robot, using a commercially-available 3D printer. We detail the steps required to modify the printer and describe the design constraints imposed by this new fabrication approach.