 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2Xplat: Two Experts Are Better Than One Generalist
Mar 24, 2026Pose-free feed-forward 3D Gaussian Splatting (3DGS) has opened a new frontier for rapid 3D modeling, enabling high-quality Gaussian representations to be generated from uncalibrated multi-view images in a single forward pass. The dominant approach in this space adopts unified monolithic architectures, often built on geometry-centric 3D foundation models, to jointly estimate camera poses and synthesize 3DGS representations within a single network. While architecturally streamlined, such "all-in-one" designs may be suboptimal for high-fidelity 3DGS generation, as they entangle geometric reasoning and appearance modeling within a shared representation. In this work, we introduce 2Xplat, a pose-free feed-forward 3DGS framework based on a two-expert design that explicitly separates geometry estimation from Gaussian generation. A dedicated geometry expert first predicts camera poses, which are then explicitly passed to a powerful appearance expert that synthesizes 3D Gaussians. Despite its conceptual simplicity, being largely underexplored in prior works, the proposed approach proves highly effective. In fewer than 5K training iterations, the proposed two-experts pipeline substantially outperforms prior pose-free feed-forward 3DGS approaches and achieves performance on par with state-of-the-art posed methods. These results challenge the prevailing unified paradigm and suggest the potential advantages of modular design principles for complex 3D geometric estimation and appearance synthesis tasks.
Two Experts Are Better Than One Generalist: Decoupling Geometry and Appearance for Feed-Forward 3D Gaussian Splatting
Mar 22, 2026Pose-free feed-forward 3D Gaussian Splatting (3DGS) has opened a new frontier for rapid 3D modeling, enabling high-quality Gaussian representations to be generated from uncalibrated multi-view images in a single forward pass. The dominant approach in this space adopts unified monolithic architectures, often built on geometry-centric 3D foundation models, to jointly estimate camera poses and synthesize 3DGS representations within a single network. While architecturally streamlined, such "all-in-one" designs may be suboptimal for high-fidelity 3DGS generation, as they entangle geometric reasoning and appearance modeling within a shared representation. In this work, we introduce 2Xplat, a pose-free feed-forward 3DGS framework based on a two-expert design that explicitly separates geometry estimation from Gaussian generation. A dedicated geometry expert first predicts camera poses, which are then explicitly passed to a powerful appearance expert that synthesizes 3D Gaussians. Despite its conceptual simplicity, being largely underexplored in prior works, the proposed approach proves highly effective. In fewer than 5K training iterations, the proposed two-experts pipeline substantially outperforms prior pose-free feed-forward 3DGS approaches and achieves performance on par with state-of-the-art posed methods. These results challenge the prevailing unified paradigm and suggest the potential advantages of modular design principles for complex 3D geometric estimation and appearance synthesis tasks.
OpenMonoGS-SLAM: Monocular Gaussian Splatting SLAM with Open-set Semantics
Dec 09, 2025Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.
Multi-view Pyramid Transformer: Look Coarser to See Broader
Dec 08, 2025



We propose Multi-view Pyramid Transformer (MVP), a scalable multi-view transformer architecture that directly reconstructs large 3D scenes from tens to hundreds of images in a single forward pass. Drawing on the idea of ``looking broader to see the whole, looking finer to see the details," MVP is built on two core design principles: 1) a local-to-global inter-view hierarchy that gradually broadens the model's perspective from local views to groups and ultimately the full scene, and 2) a fine-to-coarse intra-view hierarchy that starts from detailed spatial representations and progressively aggregates them into compact, information-dense tokens. This dual hierarchy achieves both computational efficiency and representational richness, enabling fast reconstruction of large and complex scenes. We validate MVP on diverse datasets and show that, when coupled with 3D Gaussian Splatting as the underlying 3D representation, it achieves state-of-the-art generalizable reconstruction quality while maintaining high efficiency and scalability across a wide range of view configurations.
Gather-Scatter Mamba: Accelerating Propagation with Efficient State Space Model
Oct 01, 2025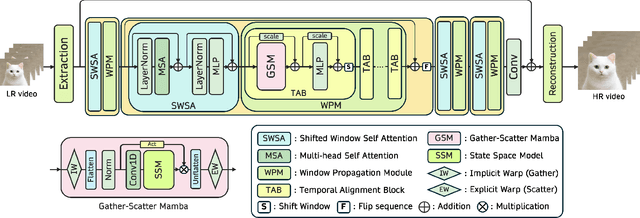
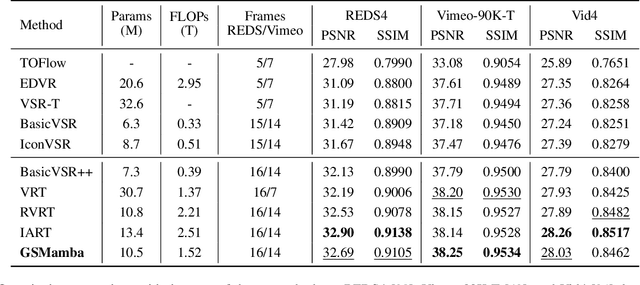
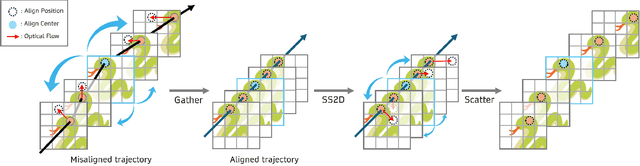
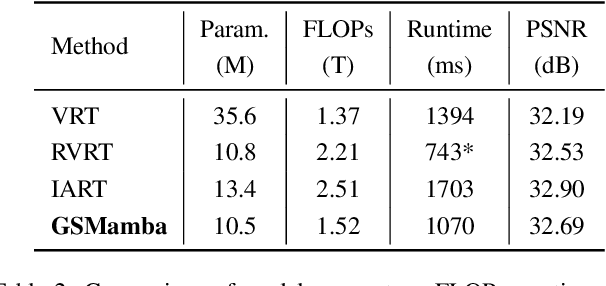
State Space Models (SSMs)-most notably RNNs-have historically played a central role in sequential modeling. Although attention mechanisms such as Transformers have since dominated due to their ability to model global context, their quadratic complexity and limited scalability make them less suited for long sequences. Video super-resolution (VSR) methods have traditionally relied on recurrent architectures to propagate features across frames. However, such approaches suffer from well-known issues including vanishing gradients, lack of parallelism, and slow inference speed. Recent advances in selective SSMs like Mamba offer a compelling alternative: by enabling input-dependent state transitions with linear-time complexity, Mamba mitigates these issues while maintaining strong long-range modeling capabilities. Despite this potential, Mamba alone struggles to capture fine-grained spatial dependencies due to its causal nature and lack of explicit context aggregation. To address this, we propose a hybrid architecture that combines shifted window self-attention for spatial context aggregation with Mamba-based selective scanning for efficient temporal propagation. Furthermore, we introduce Gather-Scatter Mamba (GSM), an alignment-aware mechanism that warps features toward a center anchor frame within the temporal window before Mamba propagation and scatters them back afterward, effectively reducing occlusion artifacts and ensuring effective redistribution of aggregated information across all frames. The official implementation is provided at: https://github.com/Ko-Lani/GSMamba.
Generative Densification: Learning to Densify Gaussians for High-Fidelity Generalizable 3D Reconstruction
Dec 09, 2024



Generalized feed-forward Gaussian models have achieved significant progress in sparse-view 3D reconstruction by leveraging prior knowledge from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be adapted to the feed-forward models, it may not be ideally suited for generalized scenarios. In this paper, we propose Generative Densification, an efficient and generalizable method to densify Gaussians generated by feed-forward models. Unlike the 3D-GS densification strategy, which iteratively splits and clones raw Gaussian parameters, our method up-samples feature representations from the feed-forward models and generates their corresponding fine Gaussians in a single forward pass, leveraging the embedded prior knowledge for enhanced generalization. Experimental results on both object-level and scene-level reconstruction tasks demonstrate that our method outperforms state-of-the-art approaches with comparable or smaller model sizes, achieving notable improvements in representing fine details.
SelfSplat: Pose-Free and 3D Prior-Free Generalizable 3D Gaussian Splatting
Nov 26, 2024



We propose SelfSplat, a novel 3D Gaussian Splatting model designed to perform pose-free and 3D prior-free generalizable 3D reconstruction from unposed multi-view images. These settings are inherently ill-posed due to the lack of ground-truth data, learned geometric information, and the need to achieve accurate 3D reconstruction without finetuning, making it difficult for conventional methods to achieve high-quality results. Our model addresses these challenges by effectively integrating explicit 3D representations with self-supervised depth and pose estimation techniques, resulting in reciprocal improvements in both pose accuracy and 3D reconstruction quality. Furthermore, we incorporate a matching-aware pose estimation network and a depth refinement module to enhance geometry consistency across views, ensuring more accurate and stable 3D reconstructions. To present the performance of our method, we evaluated it on large-scale real-world datasets, including RealEstate10K, ACID, and DL3DV. SelfSplat achieves superior results over previous state-of-the-art methods in both appearance and geometry quality, also demonstrates strong cross-dataset generalization capabilities. Extensive ablation studies and analysis also validate the effectiveness of our proposed methods. Code and pretrained models are available at https://gynjn.github.io/selfsplat/
CodecNeRF: Toward Fast Encoding and Decoding, Compact, and High-quality Novel-view Synthesis
Apr 07, 2024



Neural Radiance Fields (NeRF) have achieved huge success in effectively capturing and representing 3D objects and scenes. However, several factors have impeded its further proliferation as next-generation 3D media. To establish a ubiquitous presence in everyday media formats, such as images and videos, it is imperative to devise a solution that effectively fulfills three key objectives: fast encoding and decoding time, compact model sizes, and high-quality renderings. Despite significant advancements, a comprehensive algorithm that adequately addresses all objectives has yet to be fully realized. In this work, we present CodecNeRF, a neural codec for NeRF representations, consisting of a novel encoder and decoder architecture that can generate a NeRF representation in a single forward pass. Furthermore, inspired by the recent parameter-efficient finetuning approaches, we develop a novel finetuning method to efficiently adapt the generated NeRF representations to a new test instance, leading to high-quality image renderings and compact code sizes. The proposed CodecNeRF, a newly suggested encoding-decoding-finetuning pipeline for NeRF, achieved unprecedented compression performance of more than 150x and 20x reduction in encoding time while maintaining (or improving) the image quality on widely used 3D object datasets, such as ShapeNet and Objaverse.