 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
Mar 19, 2026Creating dynamic, view-consistent videos of customized subjects is highly sought after for a wide range of emerging applications, including immersive VR/AR, virtual production, and next-generation e-commerce. However, despite rapid progress in subject-driven video generation, existing methods predominantly treat subjects as 2D entities, focusing on transferring identity through single-view visual features or textual prompts. Because real-world subjects are inherently 3D, applying these 2D-centric approaches to 3D object customization reveals a fundamental limitation: they lack the comprehensive spatial priors necessary to reconstruct the 3D geometry. Consequently, when synthesizing novel views, they must rely on generating plausible but arbitrary details for unseen regions, rather than preserving the true 3D identity. Achieving genuine 3D-aware customization remains challenging due to the scarcity of multi-view video datasets. While one might attempt to fine-tune models on limited video sequences, this often leads to temporal overfitting. To resolve these issues, we introduce a novel framework for 3D-aware video customization, comprising 3DreamBooth and 3Dapter. 3DreamBooth decouples spatial geometry from temporal motion through a 1-frame optimization paradigm. By restricting updates to spatial representations, it effectively bakes a robust 3D prior into the model without the need for exhaustive video-based training. To enhance fine-grained textures and accelerate convergence, we incorporate 3Dapter, a visual conditioning module. Following single-view pre-training, 3Dapter undergoes multi-view joint optimization with the main generation branch via an asymmetrical conditioning strategy. This design allows the module to act as a dynamic selective router, querying view-specific geometric hints from a minimal reference set. Project page: https://ko-lani.github.io/3DreamBooth/
OpenMonoGS-SLAM: Monocular Gaussian Splatting SLAM with Open-set Semantics
Dec 09, 2025Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.
Gather-Scatter Mamba: Accelerating Propagation with Efficient State Space Model
Oct 01, 2025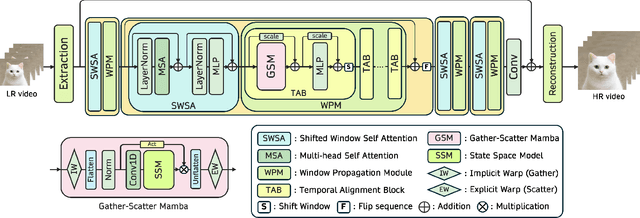
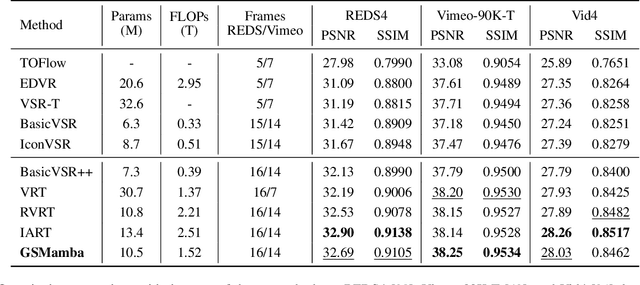
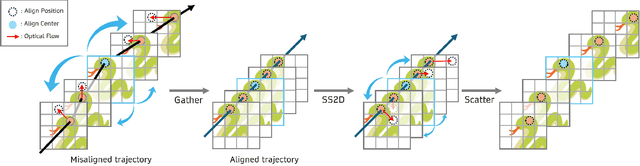
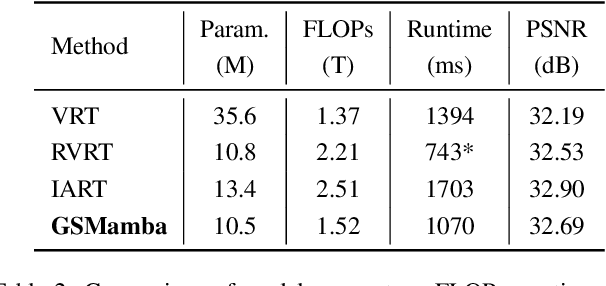
State Space Models (SSMs)-most notably RNNs-have historically played a central role in sequential modeling. Although attention mechanisms such as Transformers have since dominated due to their ability to model global context, their quadratic complexity and limited scalability make them less suited for long sequences. Video super-resolution (VSR) methods have traditionally relied on recurrent architectures to propagate features across frames. However, such approaches suffer from well-known issues including vanishing gradients, lack of parallelism, and slow inference speed. Recent advances in selective SSMs like Mamba offer a compelling alternative: by enabling input-dependent state transitions with linear-time complexity, Mamba mitigates these issues while maintaining strong long-range modeling capabilities. Despite this potential, Mamba alone struggles to capture fine-grained spatial dependencies due to its causal nature and lack of explicit context aggregation. To address this, we propose a hybrid architecture that combines shifted window self-attention for spatial context aggregation with Mamba-based selective scanning for efficient temporal propagation. Furthermore, we introduce Gather-Scatter Mamba (GSM), an alignment-aware mechanism that warps features toward a center anchor frame within the temporal window before Mamba propagation and scatters them back afterward, effectively reducing occlusion artifacts and ensuring effective redistribution of aggregated information across all frames. The official implementation is provided at: https://github.com/Ko-Lani/GSMamba.
Sequence Matters: Harnessing Video Models in Super-Resolution
Dec 16, 2024



3D super-resolution aims to reconstruct high-fidelity 3D models from low-resolution (LR) multi-view images. Early studies primarily focused on single-image super-resolution (SISR) models to upsample LR images into high-resolution images. However, these methods often lack view consistency because they operate independently on each image. Although various post-processing techniques have been extensively explored to mitigate these inconsistencies, they have yet to fully resolve the issues. In this paper, we perform a comprehensive study of 3D super-resolution by leveraging video super-resolution (VSR) models. By utilizing VSR models, we ensure a higher degree of spatial consistency and can reference surrounding spatial information, leading to more accurate and detailed reconstructions. Our findings reveal that VSR models can perform remarkably well even on sequences that lack precise spatial alignment. Given this observation, we propose a simple yet practical approach to align LR images without involving fine-tuning or generating 'smooth' trajectory from the trained 3D models over LR images. The experimental results show that the surprisingly simple algorithms can achieve the state-of-the-art results of 3D super-resolution tasks on standard benchmark datasets, such as the NeRF-synthetic and MipNeRF-360 datasets. Project page: https://ko-lani.github.io/Sequence-Matters