 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Modality Anchor-Guided Filtering for Test-time Prompt Tuning
Apr 14, 2026Test-Time Prompt Tuning (TPT) adapts vision-language models using augmented views, but its effectiveness is hindered by the challenge of determining which views are beneficial. Standard entropy-based filtering relies on the internal confidence scores of the model, which are often miscalibrated under distribution shift, assigning high confidence to irrelevant crops or background regions while ignoring semantic content. To address this, we propose a dual-modality anchor-guided framework that grounds view selection in semantic evidence. We introduce a text anchor from attribute-rich descriptions, to provide fine-grained class semantics, and an adaptive image anchor that captures evolving test-time statistics. Using these anchors, we filter views based on alignment and confidence, ensuring that only informative views guide adaptation. Moreover, we treat the anchors as auxiliary predictive heads and combine their predictions with the original output in a confidence-weighted ensemble, yielding a stable supervision signal for prompt updates. Extensive experiments on 15 benchmark datasets demonstrate new state-of-the-art performance, highlighting the contribution of anchor-guided supervision as a foundation for robust prompt updates.
Which Concepts to Forget and How to Refuse? Decomposing Concepts for Continual Unlearning in Large Vision-Language Models
Mar 23, 2026Continual unlearning poses the challenge of enabling large vision-language models to selectively refuse specific image-instruction pairs in response to sequential deletion requests, while preserving general utility. However, sequential unlearning updates distort shared representations, creating spurious associations between vision-language pairs and refusal behaviors that hinder precise identification of refusal targets, resulting in inappropriate refusals. To address this challenge, we propose a novel continual unlearning framework that grounds refusal behavior in fine-grained descriptions of visual and textual concepts decomposed from deletion targets. We first identify which visual-linguistic concept combinations characterize each forget category through a concept modulator, then determine how to generate appropriate refusal responses via a mixture of refusal experts, termed refusers, each specialized for concept-aligned refusal generation. To generate concept-specific refusal responses across sequential tasks, we introduce a multimodal, concept-driven routing scheme that reuses refusers for tasks sharing similar concepts and adapts underutilized ones for novel concepts. Extensive experiments on vision-language benchmarks demonstrate that the proposed framework outperforms existing methods by generating concept-grounded refusal responses and preserving the general utility across unlearning sequences.
Stake the Points: Structure-Faithful Instance Unlearning
Mar 13, 2026Machine unlearning (MU) addresses privacy risks in pretrained models. The main goal of MU is to remove the influence of designated data while preserving the utility of retained knowledge. Achieving this goal requires preserving semantic relations among retained instances, which existing studies often overlook. We observe that without such preservation, models suffer from progressive structural collapse, undermining both the deletion-retention balance. In this work, we propose a novel structure-faithful framework that introduces stakes, i.e., semantic anchors that serve as reference points to maintain the knowledge structure. By leveraging these anchors, our framework captures and stabilizes the semantic organization of knowledge. Specifically, we instantiate the anchors from language-driven attribute descriptions encoded by a semantic encoder (e.g., CLIP). We enforce preservation of the knowledge structure via structure-aware alignment and regularization: the former aligns the organization of retained knowledge before and after unlearning around anchors, while the latter regulates updates to structure-critical parameters. Results from image classification, retrieval, and face recognition show average gains of 32.9%, 22.5%, and 19.3% in performance, balancing the deletion-retention trade-off and enhancing generalization.
Instruction-Grounded Visual Projectors for Continual Learning of Generative Vision-Language Models
Aug 01, 2025



Continual learning enables pre-trained generative vision-language models (VLMs) to incorporate knowledge from new tasks without retraining data from previous ones. Recent methods update a visual projector to translate visual information for new tasks, connecting pre-trained vision encoders with large language models. However, such adjustments may cause the models to prioritize visual inputs over language instructions, particularly learning tasks with repetitive types of textual instructions. To address the neglect of language instructions, we propose a novel framework that grounds the translation of visual information on instructions for language models. We introduce a mixture of visual projectors, each serving as a specialized visual-to-language translation expert based on the given instruction context to adapt to new tasks. To avoid using experts for irrelevant instruction contexts, we propose an expert recommendation strategy that reuses experts for tasks similar to those previously learned. Additionally, we introduce expert pruning to alleviate interference from the use of experts that cumulatively activated in previous tasks. Extensive experiments on diverse vision-language tasks demonstrate that our method outperforms existing continual learning approaches by generating instruction-following responses.
Moiré Zero: An Efficient and High-Performance Neural Architecture for Moiré Removal
Jul 30, 2025Moir\'e patterns, caused by frequency aliasing between fine repetitive structures and a camera sensor's sampling process, have been a significant obstacle in various real-world applications, such as consumer photography and industrial defect inspection. With the advancements in deep learning algorithms, numerous studies-predominantly based on convolutional neural networks-have suggested various solutions to address this issue. Despite these efforts, existing approaches still struggle to effectively eliminate artifacts due to the diverse scales, orientations, and color shifts of moir\'e patterns, primarily because the constrained receptive field of CNN-based architectures limits their ability to capture the complex characteristics of moir\'e patterns. In this paper, we propose MZNet, a U-shaped network designed to bring images closer to a 'Moire-Zero' state by effectively removing moir\'e patterns. It integrates three specialized components: Multi-Scale Dual Attention Block (MSDAB) for extracting and refining multi-scale features, Multi-Shape Large Kernel Convolution Block (MSLKB) for capturing diverse moir\'e structures, and Feature Fusion-Based Skip Connection for enhancing information flow. Together, these components enhance local texture restoration and large-scale artifact suppression. Experiments on benchmark datasets demonstrate that MZNet achieves state-of-the-art performance on high-resolution datasets and delivers competitive results on lower-resolution dataset, while maintaining a low computational cost, suggesting that it is an efficient and practical solution for real-world applications. Project page: https://sngryonglee.github.io/MoireZero
RainbowPrompt: Diversity-Enhanced Prompt-Evolving for Continual Learning
Jul 30, 2025

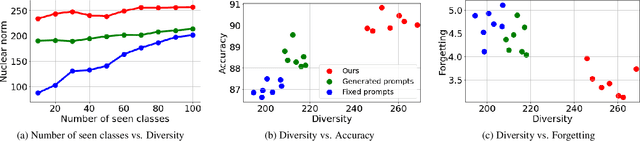

Prompt-based continual learning provides a rehearsal-free solution by tuning small sets of parameters while keeping pre-trained models frozen. To meet the complex demands of sequential tasks, it is crucial to integrate task-specific knowledge within prompts effectively. However, existing works rely on either fixed learned prompts (i.e., prompts whose representations remain unchanged during new task learning) or on prompts generated from an entangled task-shared space, limiting the representational diversity of the integrated prompt. To address this issue, we propose a novel prompt-evolving mechanism to adaptively aggregate base prompts (i.e., task-specific prompts) into a unified prompt while ensuring diversity. By transforming and aligning base prompts, both previously learned and newly introduced, our approach continuously evolves accumulated knowledge to facilitate learning new tasks. We further introduce a learnable probabilistic gate that adaptively determines which layers to activate during the evolution process. We validate our method on image classification and video action recognition tasks in class-incremental learning, achieving average gains of 9.07% and 7.40% over existing methods across all scenarios.
Continual Learning for Multiple Modalities
Mar 11, 2025



Continual learning aims to learn knowledge of tasks observed in sequential time steps while mitigating the forgetting of previously learned knowledge. Existing methods were proposed under the assumption of learning a single modality (e.g., image) over time, which limits their applicability in scenarios involving multiple modalities. In this work, we propose a novel continual learning framework that accommodates multiple modalities (image, video, audio, depth, and text). We train a model to align various modalities with text, leveraging its rich semantic information. However, this increases the risk of forgetting previously learned knowledge, exacerbated by the differing input traits of each task. To alleviate the overwriting of the previous knowledge of modalities, we propose a method for aggregating knowledge within and across modalities. The aggregated knowledge is obtained by assimilating new information through self-regularization within each modality and associating knowledge between modalities by prioritizing contributions from relevant modalities. Furthermore, we propose a strategy that re-aligns the embeddings of modalities to resolve biased alignment between modalities. We evaluate the proposed method in a wide range of continual learning scenarios using multiple datasets with different modalities. Extensive experiments demonstrate that ours outperforms existing methods in the scenarios, regardless of whether the identity of the modality is given.
Self-Corrective Task Planning by Inverse Prompting with Large Language Models
Mar 10, 2025In robot task planning, large language models (LLMs) have shown significant promise in generating complex and long-horizon action sequences. However, it is observed that LLMs often produce responses that sound plausible but are not accurate. To address these problems, existing methods typically employ predefined error sets or external knowledge sources, requiring human efforts and computation resources. Recently, self-correction approaches have emerged, where LLM generates and refines plans, identifying errors by itself. Despite their effectiveness, they are more prone to failures in correction due to insufficient reasoning. In this paper, we introduce InversePrompt, a novel self-corrective task planning approach that leverages inverse prompting to enhance interpretability. Our method incorporates reasoning steps to provide clear, interpretable feedback. It generates inverse actions corresponding to the initially generated actions and verifies whether these inverse actions can restore the system to its original state, explicitly validating the logical coherence of the generated plans. The results on benchmark datasets show an average 16.3% higher success rate over existing LLM-based task planning methods. Our approach offers clearer justifications for feedback in real-world environments, resulting in more successful task completion than existing self-correction approaches across various scenarios.
Deep Elastic Networks with Model Selection for Multi-Task Learning
Sep 11, 2019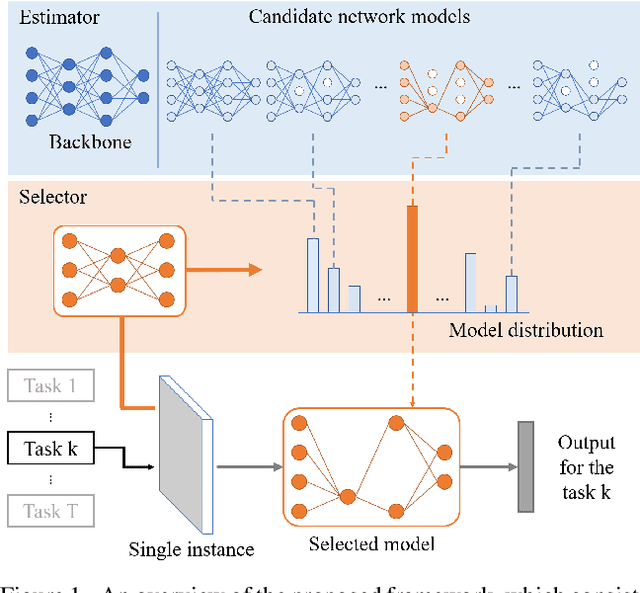
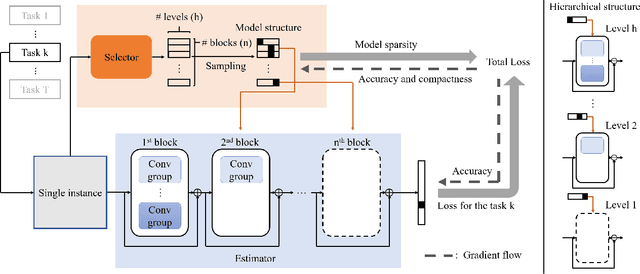
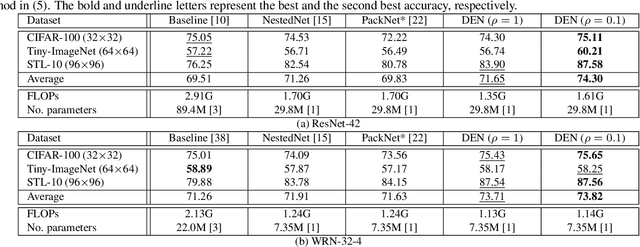
In this work, we consider the problem of instance-wise dynamic network model selection for multi-task learning. To this end, we propose an efficient approach to exploit a compact but accurate model in a backbone architecture for each instance of all tasks. The proposed method consists of an estimator and a selector. The estimator is based on a backbone architecture and structured hierarchically. It can produce multiple different network models of different configurations in a hierarchical structure. The selector chooses a model dynamically from a pool of candidate models given an input instance. The selector is a relatively small-size network consisting of a few layers, which estimates a probability distribution over the candidate models when an input instance of a task is given. Both estimator and selector are jointly trained in a unified learning framework in conjunction with a sampling-based learning strategy, without additional computation steps. We demonstrate the proposed approach for several image classification tasks compared to existing approaches performing model selection or learning multiple tasks. Experimental results show that our approach gives not only outstanding performance compared to other competitors but also the versatility to perform instance-wise model selection for multiple tasks.
Deep Virtual Networks for Memory Efficient Inference of Multiple Tasks
Apr 09, 2019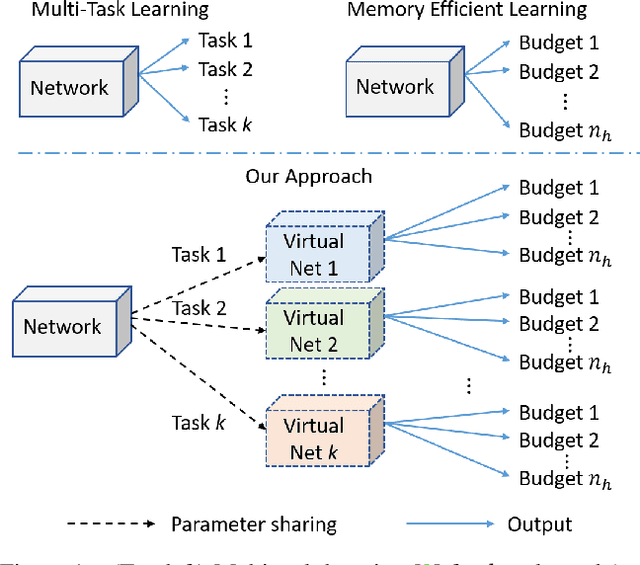
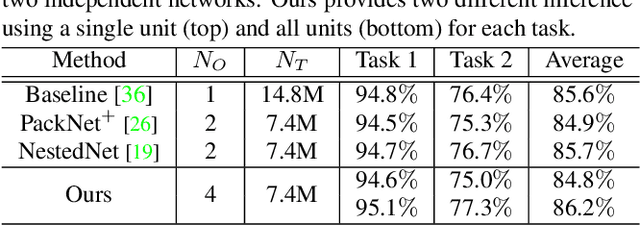
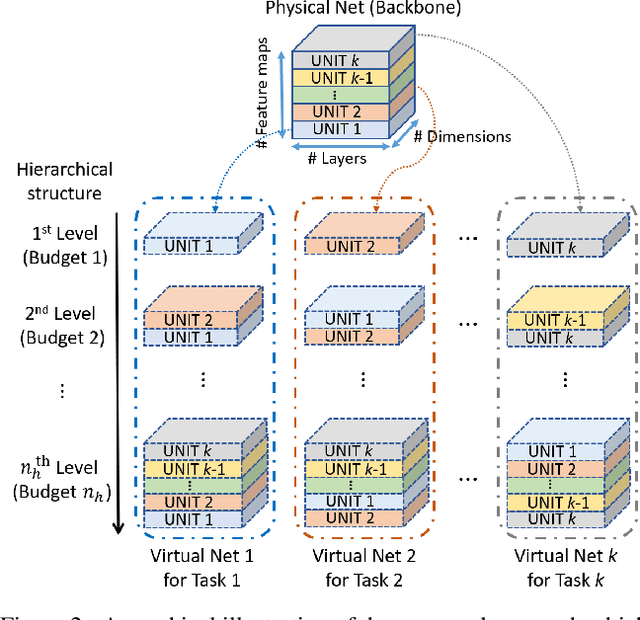
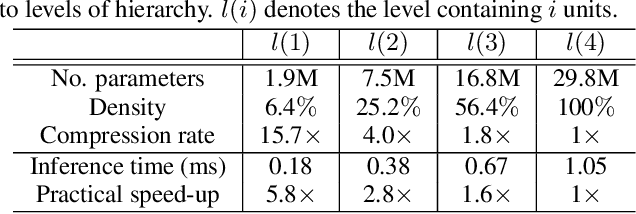
Deep networks consume a large amount of memory by their nature. A natural question arises can we reduce that memory requirement whilst maintaining performance. In particular, in this work we address the problem of memory efficient learning for multiple tasks. To this end, we propose a novel network architecture producing multiple networks of different configurations, termed deep virtual networks (DVNs), for different tasks. Each DVN is specialized for a single task and structured hierarchically. The hierarchical structure, which contains multiple levels of hierarchy corresponding to different numbers of parameters, enables multiple inference for different memory budgets. The building block of a deep virtual network is based on a disjoint collection of parameters of a network, which we call a unit. The lowest level of hierarchy in a deep virtual network is a unit, and higher levels of hierarchy contain lower levels' units and other additional units. Given a budget on the number of parameters, a different level of a deep virtual network can be chosen to perform the task. A unit can be shared by different DVNs, allowing multiple DVNs in a single network. In addition, shared units provide assistance to the target task with additional knowledge learned from another tasks. This cooperative configuration of DVNs makes it possible to handle different tasks in a memory-aware manner. Our experiments show that the proposed method outperforms existing approaches for multiple tasks. Notably, ours is more efficient than others as it allows memory-aware inference for all tasks.