 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
Mar 19, 2026Creating dynamic, view-consistent videos of customized subjects is highly sought after for a wide range of emerging applications, including immersive VR/AR, virtual production, and next-generation e-commerce. However, despite rapid progress in subject-driven video generation, existing methods predominantly treat subjects as 2D entities, focusing on transferring identity through single-view visual features or textual prompts. Because real-world subjects are inherently 3D, applying these 2D-centric approaches to 3D object customization reveals a fundamental limitation: they lack the comprehensive spatial priors necessary to reconstruct the 3D geometry. Consequently, when synthesizing novel views, they must rely on generating plausible but arbitrary details for unseen regions, rather than preserving the true 3D identity. Achieving genuine 3D-aware customization remains challenging due to the scarcity of multi-view video datasets. While one might attempt to fine-tune models on limited video sequences, this often leads to temporal overfitting. To resolve these issues, we introduce a novel framework for 3D-aware video customization, comprising 3DreamBooth and 3Dapter. 3DreamBooth decouples spatial geometry from temporal motion through a 1-frame optimization paradigm. By restricting updates to spatial representations, it effectively bakes a robust 3D prior into the model without the need for exhaustive video-based training. To enhance fine-grained textures and accelerate convergence, we incorporate 3Dapter, a visual conditioning module. Following single-view pre-training, 3Dapter undergoes multi-view joint optimization with the main generation branch via an asymmetrical conditioning strategy. This design allows the module to act as a dynamic selective router, querying view-specific geometric hints from a minimal reference set. Project page: https://ko-lani.github.io/3DreamBooth/
Moiré Zero: An Efficient and High-Performance Neural Architecture for Moiré Removal
Jul 30, 2025Moir\'e patterns, caused by frequency aliasing between fine repetitive structures and a camera sensor's sampling process, have been a significant obstacle in various real-world applications, such as consumer photography and industrial defect inspection. With the advancements in deep learning algorithms, numerous studies-predominantly based on convolutional neural networks-have suggested various solutions to address this issue. Despite these efforts, existing approaches still struggle to effectively eliminate artifacts due to the diverse scales, orientations, and color shifts of moir\'e patterns, primarily because the constrained receptive field of CNN-based architectures limits their ability to capture the complex characteristics of moir\'e patterns. In this paper, we propose MZNet, a U-shaped network designed to bring images closer to a 'Moire-Zero' state by effectively removing moir\'e patterns. It integrates three specialized components: Multi-Scale Dual Attention Block (MSDAB) for extracting and refining multi-scale features, Multi-Shape Large Kernel Convolution Block (MSLKB) for capturing diverse moir\'e structures, and Feature Fusion-Based Skip Connection for enhancing information flow. Together, these components enhance local texture restoration and large-scale artifact suppression. Experiments on benchmark datasets demonstrate that MZNet achieves state-of-the-art performance on high-resolution datasets and delivers competitive results on lower-resolution dataset, while maintaining a low computational cost, suggesting that it is an efficient and practical solution for real-world applications. Project page: https://sngryonglee.github.io/MoireZero
StarFT: Robust Fine-tuning of Zero-shot Models via Spuriosity Alignment
May 19, 2025Learning robust representations from data often requires scale, which has led to the success of recent zero-shot models such as CLIP. However, the obtained robustness can easily be deteriorated when these models are fine-tuned on other downstream tasks (e.g., of smaller scales). Previous works often interpret this phenomenon in the context of domain shift, developing fine-tuning methods that aim to preserve the original domain as much as possible. However, in a different context, fine-tuned models with limited data are also prone to learning features that are spurious to humans, such as background or texture. In this paper, we propose StarFT (Spurious Textual Alignment Regularization), a novel framework for fine-tuning zero-shot models to enhance robustness by preventing them from learning spuriosity. We introduce a regularization that aligns the output distribution for spuriosity-injected labels with the original zero-shot model, ensuring that the model is not induced to extract irrelevant features further from these descriptions.We leverage recent language models to get such spuriosity-injected labels by generating alternative textual descriptions that highlight potentially confounding features.Extensive experiments validate the robust generalization of StarFT and its emerging properties: zero-shot group robustness and improved zero-shot classification. Notably, StarFT boosts both worst-group and average accuracy by 14.30% and 3.02%, respectively, in the Waterbirds group shift scenario, where other robust fine-tuning baselines show even degraded performance.
DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Jun 26, 2024Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
Hydra: Multi-head Low-rank Adaptation for Parameter Efficient Fine-tuning
Sep 13, 2023



The recent surge in large-scale foundation models has spurred the development of efficient methods for adapting these models to various downstream tasks. Low-rank adaptation methods, such as LoRA, have gained significant attention due to their outstanding parameter efficiency and no additional inference latency. This paper investigates a more general form of adapter module based on the analysis that parallel and sequential adaptation branches learn novel and general features during fine-tuning, respectively. The proposed method, named Hydra, due to its multi-head computational branches, combines parallel and sequential branch to integrate capabilities, which is more expressive than existing single branch methods and enables the exploration of a broader range of optimal points in the fine-tuning process. In addition, the proposed adaptation method explicitly leverages the pre-trained weights by performing a linear combination of the pre-trained features. It allows the learned features to have better generalization performance across diverse downstream tasks. Furthermore, we perform a comprehensive analysis of the characteristics of each adaptation branch with empirical evidence. Through an extensive range of experiments, encompassing comparisons and ablation studies, we substantiate the efficiency and demonstrate the superior performance of Hydra. This comprehensive evaluation underscores the potential impact and effectiveness of Hydra in a variety of applications. Our code is available on \url{https://github.com/extremebird/Hydra}
Explaining Visual Biases as Words by Generating Captions
Jan 26, 2023We aim to diagnose the potential biases in image classifiers. To this end, prior works manually labeled biased attributes or visualized biased features, which need high annotation costs or are often ambiguous to interpret. Instead, we leverage two types (generative and discriminative) of pre-trained vision-language models to describe the visual bias as a word. Specifically, we propose bias-to-text (B2T), which generates captions of the mispredicted images using a pre-trained captioning model to extract the common keywords that may describe visual biases. Then, we categorize the bias type as spurious correlation or majority bias by checking if it is specific or agnostic to the class, based on the similarity of class-wise mispredicted images and the keyword upon a pre-trained vision-language joint embedding space, e.g., CLIP. We demonstrate that the proposed simple and intuitive scheme can recover well-known gender and background biases, and discover novel ones in real-world datasets. Moreover, we utilize B2T to compare the classifiers using different architectures or training methods. Finally, we show that one can obtain debiased classifiers using the B2T bias keywords and CLIP, in both zero-shot and full-shot manners, without using any human annotation on the bias.
ORA3D: Overlap Region Aware Multi-view 3D Object Detection
Jul 02, 2022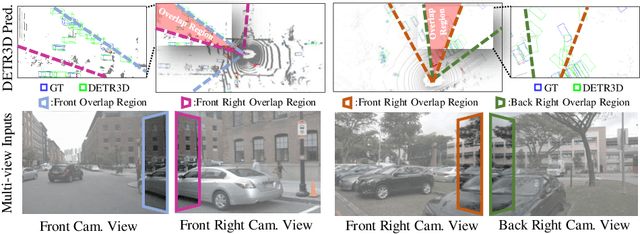
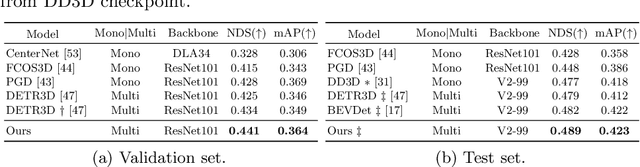
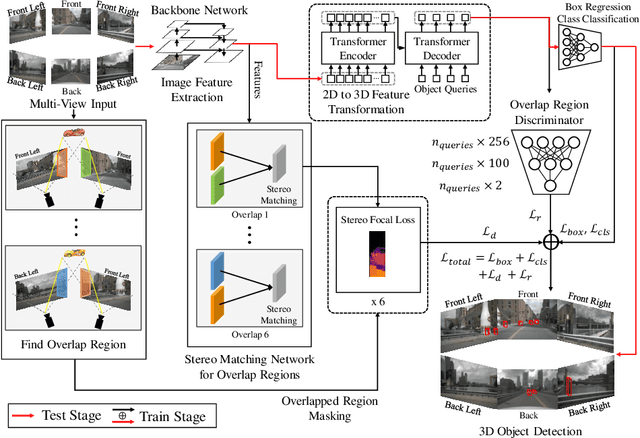

In multi-view 3D object detection tasks, disparity supervision over overlapping image regions substantially improves the overall detection performance. However, current multi-view 3D object detection methods often fail to detect objects in the overlap region properly, and the network's understanding of the scene is often limited to that of a monocular detection network. To mitigate this issue, we advocate for applying the traditional stereo disparity estimation method to obtain reliable disparity information for the overlap region. Given the disparity estimates as a supervision, we propose to regularize the network to fully utilize the geometric potential of binocular images, and improve the overall detection accuracy. Moreover, we propose to use an adversarial overlap region discriminator, which is trained to minimize the representational gap between non-overlap regions and overlapping regions where objects are often largely occluded or suffer from deformation due to camera distortion, causing a domain shift. We demonstrate the effectiveness of the proposed method with the large-scale multi-view 3D object detection benchmark, called nuScenes. Our experiment shows that our proposed method outperforms the current state-of-the-art methods.