 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Internal States Reveal Hallucination Risk Faced With a Query
Jul 03, 2024The hallucination problem of Large Language Models (LLMs) significantly limits their reliability and trustworthiness. Humans have a self-awareness process that allows us to recognize what we don't know when faced with queries. Inspired by this, our paper investigates whether LLMs can estimate their own hallucination risk before response generation. We analyze the internal mechanisms of LLMs broadly both in terms of training data sources and across 15 diverse Natural Language Generation (NLG) tasks, spanning over 700 datasets. Our empirical analysis reveals two key insights: (1) LLM internal states indicate whether they have seen the query in training data or not; and (2) LLM internal states show they are likely to hallucinate or not regarding the query. Our study explores particular neurons, activation layers, and tokens that play a crucial role in the LLM perception of uncertainty and hallucination risk. By a probing estimator, we leverage LLM self-assessment, achieving an average hallucination estimation accuracy of 84.32\% at run time.
Belief Revision: The Adaptability of Large Language Models Reasoning
Jun 28, 2024



The capability to reason from text is crucial for real-world NLP applications. Real-world scenarios often involve incomplete or evolving data. In response, individuals update their beliefs and understandings accordingly. However, most existing evaluations assume that language models (LMs) operate with consistent information. We introduce Belief-R, a new dataset designed to test LMs' belief revision ability when presented with new evidence. Inspired by how humans suppress prior inferences, this task assesses LMs within the newly proposed delta reasoning ($\Delta R$) framework. Belief-R features sequences of premises designed to simulate scenarios where additional information could necessitate prior conclusions drawn by LMs. We evaluate $\sim$30 LMs across diverse prompting strategies and found that LMs generally struggle to appropriately revise their beliefs in response to new information. Further, models adept at updating often underperformed in scenarios without necessary updates, highlighting a critical trade-off. These insights underscore the importance of improving LMs' adaptiveness to changing information, a step toward more reliable AI systems.
The Pyramid of Captions
May 01, 2024We introduce a formal information-theoretic framework for image captioning by regarding it as a representation learning task. Our framework defines three key objectives: task sufficiency, minimal redundancy, and human interpretability. Building upon this foundation, we propose a novel Pyramid of Captions (PoCa) method, which constructs caption pyramids by generating localized captions for zoomed-in image patches and integrating them with global caption information using large language models. This approach leverages intuition that the detailed examination of local patches can reduce error risks and address inaccuracies in global captions, either by correcting the hallucination or adding missing details. Based on our theoretical framework, we formalize this intuition and provide formal proof demonstrating the effectiveness of PoCa under certain assumptions. Empirical tests with various image captioning models and large language models show that PoCa consistently yields more informative and semantically aligned captions, maintaining brevity and interpretability.
High-Dimension Human Value Representation in Large Language Models
Apr 11, 2024



The widespread application of Large Language Models (LLMs) across various tasks and fields has necessitated the alignment of these models with human values and preferences. Given various approaches of human value alignment, ranging from Reinforcement Learning with Human Feedback (RLHF), to constitutional learning, etc. there is an urgent need to understand the scope and nature of human values injected into these models before their release. There is also a need for model alignment without a costly large scale human annotation effort. We propose UniVaR, a high-dimensional representation of human value distributions in LLMs, orthogonal to model architecture and training data. Trained from the value-relevant output of eight multilingual LLMs and tested on the output from four multilingual LLMs, namely LlaMA2, ChatGPT, JAIS and Yi, we show that UniVaR is a powerful tool to compare the distribution of human values embedded in different LLMs with different langauge sources. Through UniVaR, we explore how different LLMs prioritize various values in different languages and cultures, shedding light on the complex interplay between human values and language modeling.
Contrastive Learning for Inference in Dialogue
Oct 19, 2023Inference, especially those derived from inductive processes, is a crucial component in our conversation to complement the information implicitly or explicitly conveyed by a speaker. While recent large language models show remarkable advances in inference tasks, their performance in inductive reasoning, where not all information is present in the context, is far behind deductive reasoning. In this paper, we analyze the behavior of the models based on the task difficulty defined by the semantic information gap -- which distinguishes inductive and deductive reasoning (Johnson-Laird, 1988, 1993). Our analysis reveals that the disparity in information between dialogue contexts and desired inferences poses a significant challenge to the inductive inference process. To mitigate this information gap, we investigate a contrastive learning approach by feeding negative samples. Our experiments suggest negative samples help models understand what is wrong and improve their inference generations.
Towards Mitigating Hallucination in Large Language Models via Self-Reflection
Oct 10, 2023



Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
Can Question Rewriting Help Conversational Question Answering?
Apr 13, 2022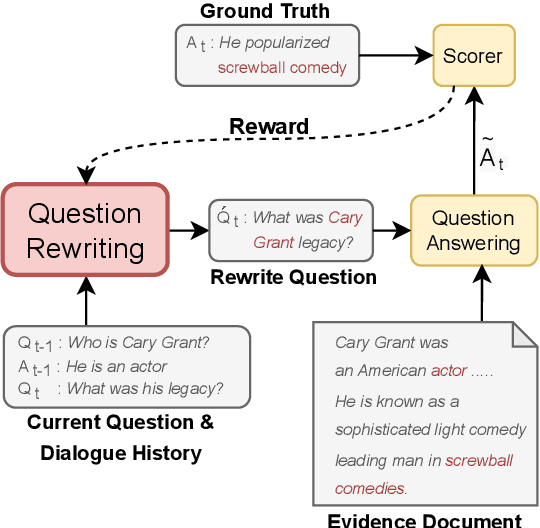
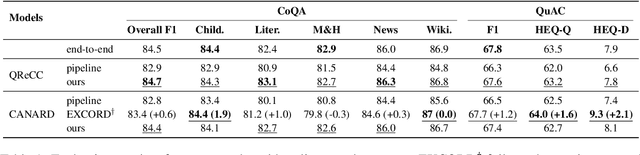

Question rewriting (QR) is a subtask of conversational question answering (CQA) aiming to ease the challenges of understanding dependencies among dialogue history by reformulating questions in a self-contained form. Despite seeming plausible, little evidence is available to justify QR as a mitigation method for CQA. To verify the effectiveness of QR in CQA, we investigate a reinforcement learning approach that integrates QR and CQA tasks and does not require corresponding QR datasets for targeted CQA. We find, however, that the RL method is on par with the end-to-end baseline. We provide an analysis of the failure and describe the difficulty of exploiting QR for CQA.
VScript: Controllable Script Generation with Audio-Visual Presentation
Mar 01, 2022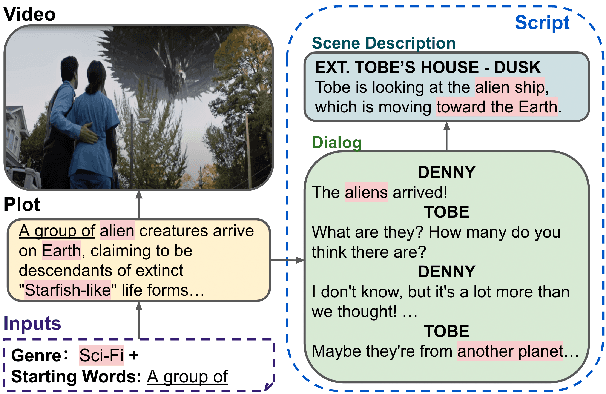
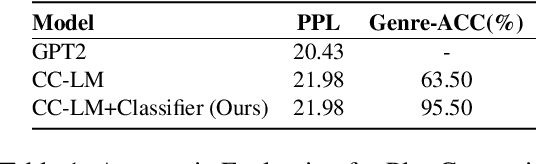
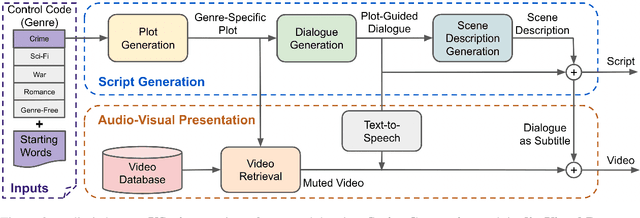
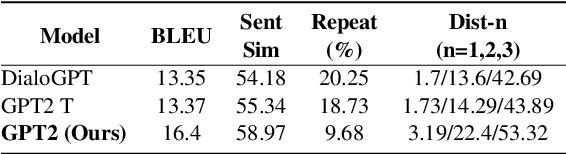
Automatic script generation could save a considerable amount of resources and offer inspiration to professional scriptwriters. We present VScript, a controllable pipeline that generates complete scripts including dialogues and scene descriptions, and presents visually using video retrieval and aurally using text-to-speech for spoken dialogue. With an interactive interface, our system allows users to select genres and input starting words that control the theme and development of the generated script. We adopt a hierarchical structure, which generates the plot, then the script and its audio-visual presentation. We also introduce a novel approach to plot-guided dialogue generation by treating it as an inverse dialogue summarization. Experiment results show that our approach outperforms the baselines on both automatic and human evaluations, especially in terms of genre control.
Survey of Hallucination in Natural Language Generation
Feb 08, 2022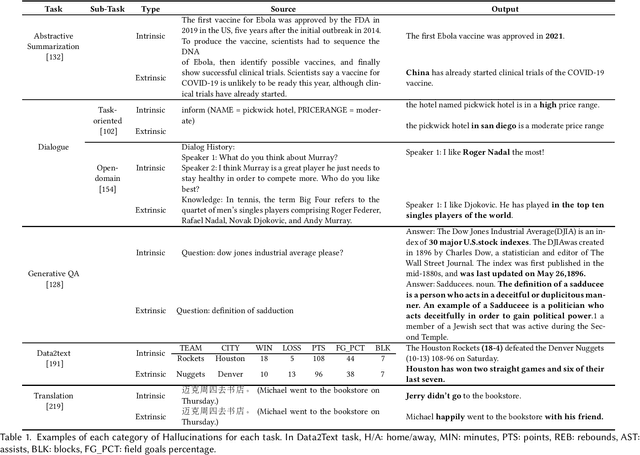
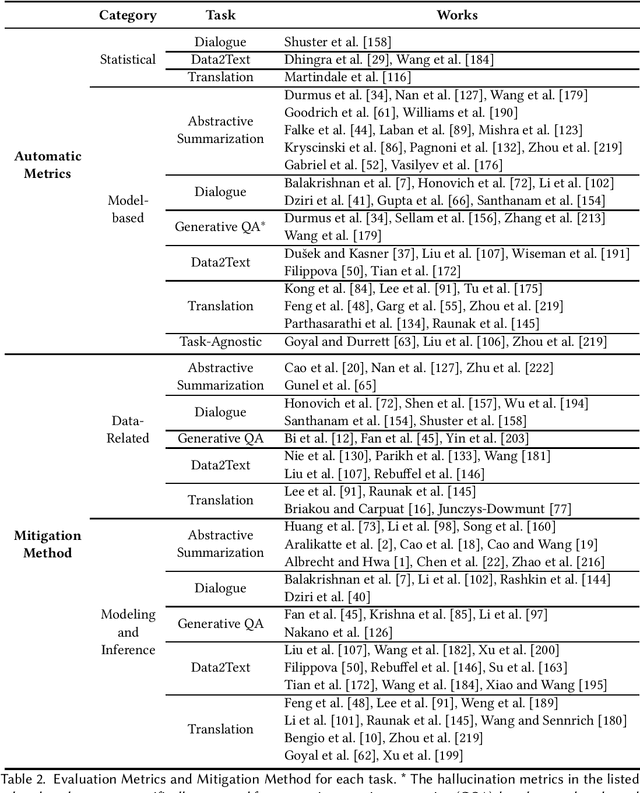
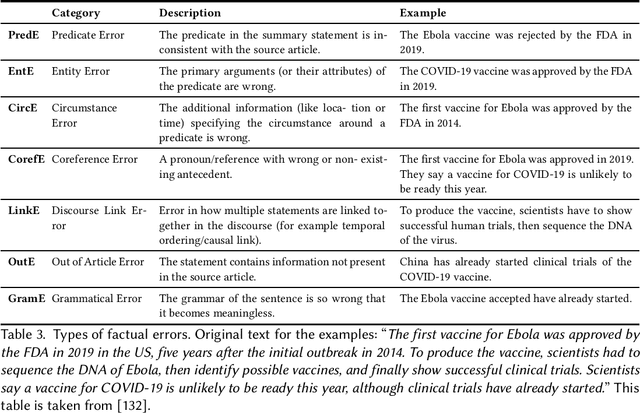
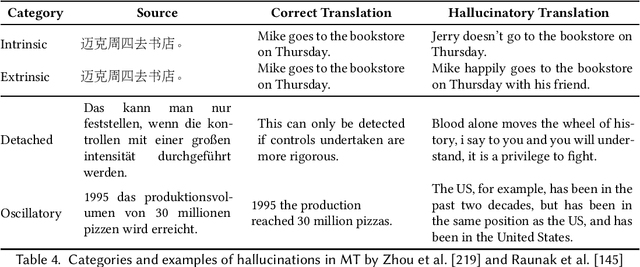
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent natural language generation, naturally leading to development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also investigated that such generation includes hallucinated texts, which makes the performances of text generation fail to meet users' expectations in many real-world scenarios. In order to address this issue, studies in evaluation and mitigation methods of hallucinations have been presented in various tasks, but have not been reviewed in a combined manner. In this survey, we provide a broad overview of the research progress and challenges in the hallucination problem of NLG. The survey is organized into two big divisions: (i) a general overview of metrics, mitigation methods, and future directions; (ii) task-specific research progress for hallucinations in a large set of downstream tasks: abstractive summarization, dialogue generation, generative question answering, data-to-text generation, and machine translation. This survey could facilitate collaborative efforts among researchers in these tasks.
Greenformer: Factorization Toolkit for Efficient Deep Neural Networks
Sep 14, 2021

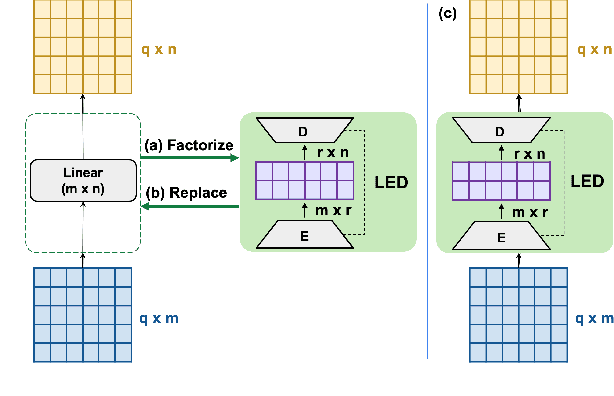
While the recent advances in deep neural networks (DNN) bring remarkable success, the computational cost also increases considerably. In this paper, we introduce Greenformer, a toolkit to accelerate the computation of neural networks through matrix factorization while maintaining performance. Greenformer can be easily applied with a single line of code to any DNN model. Our experimental results show that Greenformer is effective for a wide range of scenarios. We provide the showcase of Greenformer at https://samuelcahyawijaya.github.io/greenformer-demo/.