 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Deep RL with High Update Ratios: Combatting Value Overestimation and Divergence
Mar 09, 2024We show that deep reinforcement learning can maintain its ability to learn without resetting network parameters in settings where the number of gradient updates greatly exceeds the number of environment samples. Under such large update-to-data ratios, a recent study by Nikishin et al. (2022) suggested the emergence of a primacy bias, in which agents overfit early interactions and downplay later experience, impairing their ability to learn. In this work, we dissect the phenomena underlying the primacy bias. We inspect the early stages of training that ought to cause the failure to learn and find that a fundamental challenge is a long-standing acquaintance: value overestimation. Overinflated Q-values are found not only on out-of-distribution but also in-distribution data and can be traced to unseen action prediction propelled by optimizer momentum. We employ a simple unit-ball normalization that enables learning under large update ratios, show its efficacy on the widely used dm_control suite, and obtain strong performance on the challenging dog tasks, competitive with model-based approaches. Our results question, in parts, the prior explanation for sub-optimal learning due to overfitting on early data.
IBCL: Zero-shot Model Generation for Task Trade-offs in Continual Learning
Oct 09, 2023Like generic multi-task learning, continual learning has the nature of multi-objective optimization, and therefore faces a trade-off between the performance of different tasks. That is, to optimize for the current task distribution, it may need to compromise performance on some previous tasks. This means that there exist multiple models that are Pareto-optimal at different times, each addressing a distinct task performance trade-off. Researchers have discussed how to train particular models to address specific trade-off preferences. However, existing algorithms require training overheads proportional to the number of preferences -- a large burden when there are multiple, possibly infinitely many, preferences. As a response, we propose Imprecise Bayesian Continual Learning (IBCL). Upon a new task, IBCL (1) updates a knowledge base in the form of a convex hull of model parameter distributions and (2) obtains particular models to address task trade-off preferences with zero-shot. That is, IBCL does not require any additional training overhead to generate preference-addressing models from its knowledge base. We show that models obtained by IBCL have guarantees in identifying the Pareto optimal parameters. Moreover, experiments on standard image classification and NLP tasks support this guarantee. Statistically, IBCL improves average per-task accuracy by at most 23\% and peak per-task accuracy by at most 15\% with respect to the baseline methods, with steadily near-zero or positive backward transfer. Most importantly, IBCL significantly reduces the training overhead from training 1 model per preference to at most 3 models for all preferences.
Robotic Manipulation Datasets for Offline Compositional Reinforcement Learning
Jul 13, 2023
Offline reinforcement learning (RL) is a promising direction that allows RL agents to pre-train on large datasets, avoiding the recurrence of expensive data collection. To advance the field, it is crucial to generate large-scale datasets. Compositional RL is particularly appealing for generating such large datasets, since 1) it permits creating many tasks from few components, 2) the task structure may enable trained agents to solve new tasks by combining relevant learned components, and 3) the compositional dimensions provide a notion of task relatedness. This paper provides four offline RL datasets for simulated robotic manipulation created using the 256 tasks from CompoSuite [Mendez et al., 2022a]. Each dataset is collected from an agent with a different degree of performance, and consists of 256 million transitions. We provide training and evaluation settings for assessing an agent's ability to learn compositional task policies. Our benchmarking experiments on each setting show that current offline RL methods can learn the training tasks to some extent and that compositional methods significantly outperform non-compositional methods. However, current methods are still unable to extract the tasks' compositional structure to generalize to unseen tasks, showing a need for further research in offline compositional RL.
CAROM Air -- Vehicle Localization and Traffic Scene Reconstruction from Aerial Videos
May 31, 2023Road traffic scene reconstruction from videos has been desirable by road safety regulators, city planners, researchers, and autonomous driving technology developers. However, it is expensive and unnecessary to cover every mile of the road with cameras mounted on the road infrastructure. This paper presents a method that can process aerial videos to vehicle trajectory data so that a traffic scene can be automatically reconstructed and accurately re-simulated using computers. On average, the vehicle localization error is about 0.1 m to 0.3 m using a consumer-grade drone flying at 120 meters. This project also compiles a dataset of 50 reconstructed road traffic scenes from about 100 hours of aerial videos to enable various downstream traffic analysis applications and facilitate further road traffic related research. The dataset is available at https://github.com/duolu/CAROM.
Zero-shot Task Preference Addressing Enabled by Imprecise Bayesian Continual Learning
May 24, 2023Like generic multi-task learning, continual learning has the nature of multi-objective optimization, and therefore faces a trade-off between the performance of different tasks. That is, to optimize for the current task distribution, it may need to compromise performance on some tasks to improve on others. This means there exist multiple models that are each optimal at different times, each addressing a distinct task-performance trade-off. Researchers have discussed how to train particular models to address specific preferences on these trade-offs. However, existing algorithms require additional sample overheads -- a large burden when there are multiple, possibly infinitely many, preferences. As a response, we propose Imprecise Bayesian Continual Learning (IBCL). Upon a new task, IBCL (1) updates a knowledge base in the form of a convex hull of model parameter distributions and (2) obtains particular models to address preferences with zero-shot. That is, IBCL does not require any additional training overhead to construct preference-addressing models from its knowledge base. We show that models obtained by IBCL have guarantees in identifying the preferred parameters. Moreover, experiments show that IBCL is able to locate the Pareto set of parameters given a preference, maintain similar to better performance than baseline methods, and significantly reduce training overhead via zero-shot preference addressing.
Replicable Reinforcement Learning
May 24, 2023

The replicability crisis in the social, behavioral, and data sciences has led to the formulation of algorithm frameworks for replicability -- i.e., a requirement that an algorithm produce identical outputs (with high probability) when run on two different samples from the same underlying distribution. While still in its infancy, provably replicable algorithms have been developed for many fundamental tasks in machine learning and statistics, including statistical query learning, the heavy hitters problem, and distribution testing. In this work we initiate the study of replicable reinforcement learning, providing a provably replicable algorithm for parallel value iteration, and a provably replicable version of R-max in the episodic setting. These are the first formal replicability results for control problems, which present different challenges for replication than batch learning settings.
ZeroFlow: Fast Zero Label Scene Flow via Distillation
May 23, 2023



Scene flow estimation is the task of describing the 3D motion field between temporally successive point clouds. State-of-the-art methods use strong priors and test-time optimization techniques, but require on the order of tens of seconds for large-scale point clouds, making them unusable as computer vision primitives for real-time applications such as open world object detection. Feed forward methods are considerably faster, running on the order of tens to hundreds of milliseconds for large-scale point clouds, but require expensive human supervision. To address both limitations, we propose Scene Flow via Distillation, a simple distillation framework that uses a label-free optimization method to produce pseudo-labels to supervise a feed forward model. Our instantiation of this framework, ZeroFlow, produces scene flow estimates in real-time on large-scale point clouds at quality competitive with state-of-the-art methods while using zero human labels. Notably, at test-time ZeroFlow is over 1000$\times$ faster than label-free state-of-the-art optimization-based methods on large-scale point clouds and over 1000$\times$ cheaper to train on unlabeled data compared to the cost of human annotation of that data. To facilitate research reuse, we release our code, trained model weights, and high quality pseudo-labels for the Argoverse 2 and Waymo Open datasets.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023



Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Land Use Prediction using Electro-Optical to SAR Few-Shot Transfer Learning
Dec 04, 2022Satellite image analysis has important implications for land use, urbanization, and ecosystem monitoring. Deep learning methods can facilitate the analysis of different satellite modalities, such as electro-optical (EO) and synthetic aperture radar (SAR) imagery, by supporting knowledge transfer between the modalities to compensate for individual shortcomings. Recent progress has shown how distributional alignment of neural network embeddings can produce powerful transfer learning models by employing a sliced Wasserstein distance (SWD) loss. We analyze how this method can be applied to Sentinel-1 and -2 satellite imagery and develop several extensions toward making it effective in practice. In an application to few-shot Local Climate Zone (LCZ) prediction, we show that these networks outperform multiple common baselines on datasets with a large number of classes. Further, we provide evidence that instance normalization can significantly stabilize the training process and that explicitly shaping the embedding space using supervised contrastive learning can lead to improved performance.
How to Reuse and Compose Knowledge for a Lifetime of Tasks: A Survey on Continual Learning and Functional Composition
Jul 15, 2022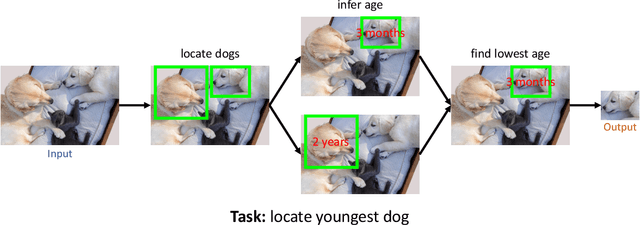

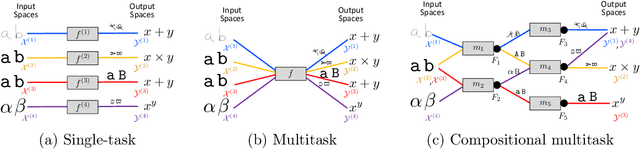
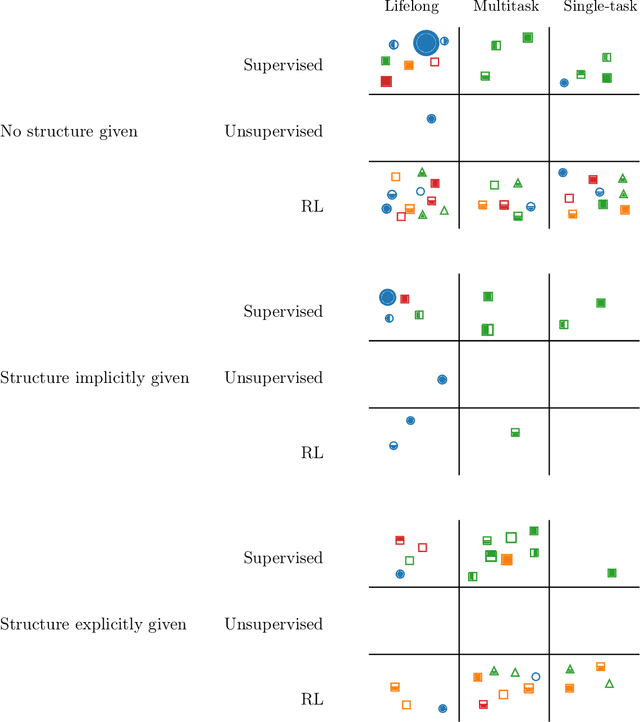
A major goal of artificial intelligence (AI) is to create an agent capable of acquiring a general understanding of the world. Such an agent would require the ability to continually accumulate and build upon its knowledge as it encounters new experiences. Lifelong or continual learning addresses this setting, whereby an agent faces a continual stream of problems and must strive to capture the knowledge necessary for solving each new task it encounters. If the agent is capable of accumulating knowledge in some form of compositional representation, it could then selectively reuse and combine relevant pieces of knowledge to construct novel solutions. Despite the intuitive appeal of this simple idea, the literatures on lifelong learning and compositional learning have proceeded largely separately. In an effort to promote developments that bridge between the two fields, this article surveys their respective research landscapes and discusses existing and future connections between them.