 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Music Audio Representations With Limited Data
May 09, 2025Large deep-learning models for music, including those focused on learning general-purpose music audio representations, are often assumed to require substantial training data to achieve high performance. If true, this would pose challenges in scenarios where audio data or annotations are scarce, such as for underrepresented music traditions, non-popular genres, and personalized music creation and listening. Understanding how these models behave in limited-data scenarios could be crucial for developing techniques to tackle them. In this work, we investigate the behavior of several music audio representation models under limited-data learning regimes. We consider music models with various architectures, training paradigms, and input durations, and train them on data collections ranging from 5 to 8,000 minutes long. We evaluate the learned representations on various music information retrieval tasks and analyze their robustness to noise. We show that, under certain conditions, representations from limited-data and even random models perform comparably to ones from large-dataset models, though handcrafted features outperform all learned representations in some tasks.
From Aesthetics to Human Preferences: Comparative Perspectives of Evaluating Text-to-Music Systems
Apr 30, 2025Evaluating generative models remains a fundamental challenge, particularly when the goal is to reflect human preferences. In this paper, we use music generation as a case study to investigate the gap between automatic evaluation metrics and human preferences. We conduct comparative experiments across five state-of-the-art music generation approaches, assessing both perceptual quality and distributional similarity to human-composed music. Specifically, we evaluate synthesis music from various perceptual dimensions and examine reference-based metrics such as Mauve Audio Divergence (MAD) and Kernel Audio Distance (KAD). Our findings reveal significant inconsistencies across the different metrics, highlighting the limitation of the current evaluation practice. To support further research, we release a benchmark dataset comprising samples from multiple models. This study provides a broader perspective on the alignment of human preference in generative modeling, advocating for more human-centered evaluation strategies across domains.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Audio-FLAN: A Preliminary Release
Feb 23, 2025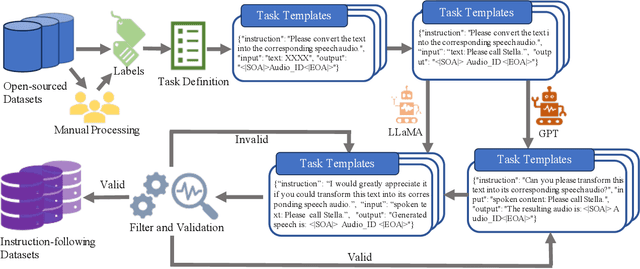

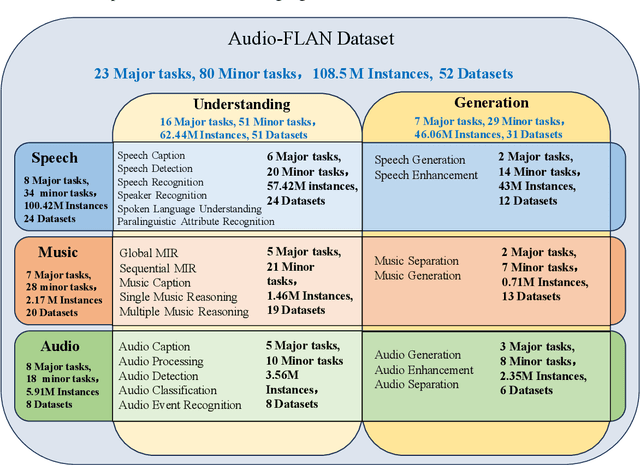

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
LHGNN: Local-Higher Order Graph Neural Networks For Audio Classification and Tagging
Jan 07, 2025



Transformers have set new benchmarks in audio processing tasks, leveraging self-attention mechanisms to capture complex patterns and dependencies within audio data. However, their focus on pairwise interactions limits their ability to process the higher-order relations essential for identifying distinct audio objects. To address this limitation, this work introduces the Local- Higher Order Graph Neural Network (LHGNN), a graph based model that enhances feature understanding by integrating local neighbourhood information with higher-order data from Fuzzy C-Means clusters, thereby capturing a broader spectrum of audio relationships. Evaluation of the model on three publicly available audio datasets shows that it outperforms Transformer-based models across all benchmarks while operating with substantially fewer parameters. Moreover, LHGNN demonstrates a distinct advantage in scenarios lacking ImageNet pretraining, establishing its effectiveness and efficiency in environments where extensive pretraining data is unavailable.
Classification of Spontaneous and Scripted Speech for Multilingual Audio
Dec 16, 2024



Distinguishing scripted from spontaneous speech is an essential tool for better understanding how speech styles influence speech processing research. It can also improve recommendation systems and discovery experiences for media users through better segmentation of large recorded speech catalogues. This paper addresses the challenge of building a classifier that generalises well across different formats and languages. We systematically evaluate models ranging from traditional, handcrafted acoustic and prosodic features to advanced audio transformers, utilising a large, multilingual proprietary podcast dataset for training and validation. We break down the performance of each model across 11 language groups to evaluate cross-lingual biases. Our experimental analysis extends to publicly available datasets to assess the models' generalisability to non-podcast domains. Our results indicate that transformer-based models consistently outperform traditional feature-based techniques, achieving state-of-the-art performance in distinguishing between scripted and spontaneous speech across various languages.
ST-ITO: Controlling Audio Effects for Style Transfer with Inference-Time Optimization
Oct 28, 2024Audio production style transfer is the task of processing an input to impart stylistic elements from a reference recording. Existing approaches often train a neural network to estimate control parameters for a set of audio effects. However, these approaches are limited in that they can only control a fixed set of effects, where the effects must be differentiable or otherwise employ specialized training techniques. In this work, we introduce ST-ITO, Style Transfer with Inference-Time Optimization, an approach that instead searches the parameter space of an audio effect chain at inference. This method enables control of arbitrary audio effect chains, including unseen and non-differentiable effects. Our approach employs a learned metric of audio production style, which we train through a simple and scalable self-supervised pretraining strategy, along with a gradient-free optimizer. Due to the limited existing evaluation methods for audio production style transfer, we introduce a multi-part benchmark to evaluate audio production style metrics and style transfer systems. This evaluation demonstrates that our audio representation better captures attributes related to audio production and enables expressive style transfer via control of arbitrary audio effects.
GraFPrint: A GNN-Based Approach for Audio Identification
Oct 14, 2024



This paper introduces GraFPrint, an audio identification framework that leverages the structural learning capabilities of Graph Neural Networks (GNNs) to create robust audio fingerprints. Our method constructs a k-nearest neighbor (k-NN) graph from time-frequency representations and applies max-relative graph convolutions to encode local and global information. The network is trained using a self-supervised contrastive approach, which enhances resilience to ambient distortions by optimizing feature representation. GraFPrint demonstrates superior performance on large-scale datasets at various levels of granularity, proving to be both lightweight and scalable, making it suitable for real-world applications with extensive reference databases.
LC-Protonets: Multi-label Few-shot learning for world music audio tagging
Sep 17, 2024



We introduce Label-Combination Prototypical Networks (LC-Protonets) to address the problem of multi-label few-shot classification, where a model must generalize to new classes based on only a few available examples. Extending Prototypical Networks, LC-Protonets generate one prototype per label combination, derived from the power set of labels present in the limited training items, rather than one prototype per label. Our method is applied to automatic audio tagging across diverse music datasets, covering various cultures and including both modern and traditional music, and is evaluated against existing approaches in the literature. The results demonstrate a significant performance improvement in almost all domains and training setups when using LC-Protonets for multi-label classification. In addition to training a few-shot learning model from scratch, we explore the use of a pre-trained model, obtained via supervised learning, to embed items in the feature space. Fine-tuning improves the generalization ability of all methods, yet LC-Protonets achieve high-level performance even without fine-tuning, in contrast to the comparative approaches. We finally analyze the scalability of the proposed method, providing detailed quantitative metrics from our experiments. The implementation and experimental setup are made publicly available, offering a benchmark for future research.
Domain-Invariant Representation Learning of Bird Sounds
Sep 16, 2024

Passive acoustic monitoring (PAM) is crucial for bioacoustic research, enabling non-invasive species tracking and biodiversity monitoring. Citizen science platforms like Xeno-Canto provide large annotated datasets from focal recordings, where the target species is intentionally recorded. However, PAM requires monitoring in passive soundscapes, creating a domain shift between focal and passive recordings, which challenges deep learning models trained on focal recordings. To address this, we leverage supervised contrastive learning to improve domain generalization in bird sound classification, enforcing domain invariance across same-class examples from different domains. We also propose ProtoCLR (Prototypical Contrastive Learning of Representations), which reduces the computational complexity of the SupCon loss by comparing examples to class prototypes instead of pairwise comparisons. Additionally, we present a new few-shot classification benchmark based on BirdSet, a large-scale bird sound dataset, and demonstrate the effectiveness of our approach in achieving strong transfer performance.