 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Model Selection for Reinforcement Learning with Function Approximation
Nov 19, 2020
Deep reinforcement learning has achieved impressive successes yet often requires a very large amount of interaction data. This result is perhaps unsurprising, as using complicated function approximation often requires more data to fit, and early theoretical results on linear Markov decision processes provide regret bounds that scale with the dimension of the linear approximation. Ideally, we would like to automatically identify the minimal dimension of the approximation that is sufficient to encode an optimal policy. Towards this end, we consider the problem of model selection in RL with function approximation, given a set of candidate RL algorithms with known regret guarantees. The learner's goal is to adapt to the complexity of the optimal algorithm without knowing it \textit{a priori}. We present a meta-algorithm that successively rejects increasingly complex models using a simple statistical test. Given at least one candidate that satisfies realizability, we prove the meta-algorithm adapts to the optimal complexity with $\tilde{O}(L^{5/6} T^{2/3})$ regret compared to the optimal candidate's $\tilde{O}(\sqrt T)$ regret, where $T$ is the number of episodes and $L$ is the number of algorithms. The dimension and horizon dependencies remain optimal with respect to the best candidate, and our meta-algorithmic approach is flexible to incorporate multiple candidate algorithms and models. Finally, we show that the meta-algorithm automatically admits significantly improved instance-dependent regret bounds that depend on the gaps between the maximal values attainable by the candidates.
Provably Efficient Reward-Agnostic Navigation with Linear Value Iteration
Aug 18, 2020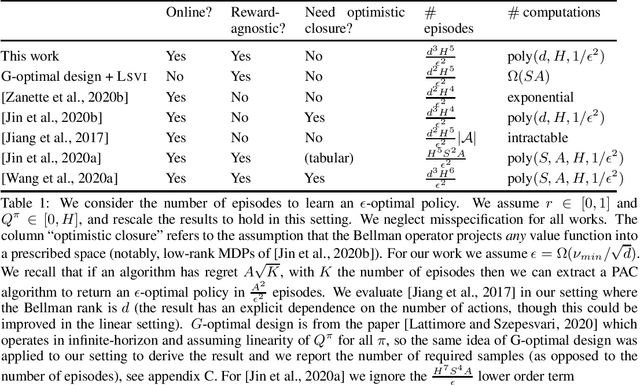

There has been growing progress on theoretical analyses for provably efficient learning in MDPs with linear function approximation, but much of the existing work has made strong assumptions to enable exploration by conventional exploration frameworks. Typically these assumptions are stronger than what is needed to find good solutions in the batch setting. In this work, we show how under a more standard notion of low inherent Bellman error, typically employed in least-square value iteration-style algorithms, we can provide strong PAC guarantees on learning a near optimal value function provided that the linear space is sufficiently ``explorable''. We present a computationally tractable algorithm for the reward-free setting and show how it can be used to learn a near optimal policy for any (linear) reward function, which is revealed only once learning has completed. If this reward function is also estimated from the samples gathered during pure exploration, our results also provide same-order PAC guarantees on the performance of the resulting policy for this setting.
Provably Good Batch Reinforcement Learning Without Great Exploration
Jul 22, 2020
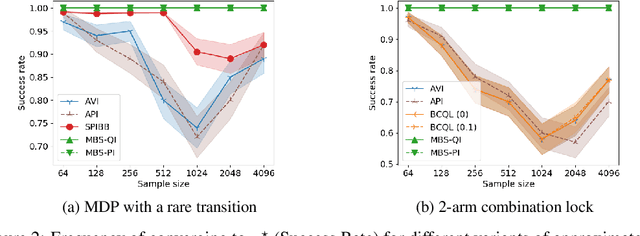
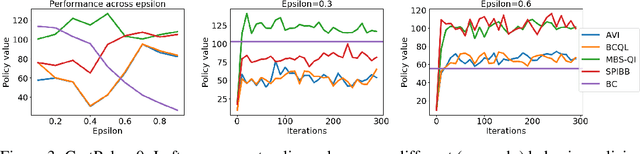
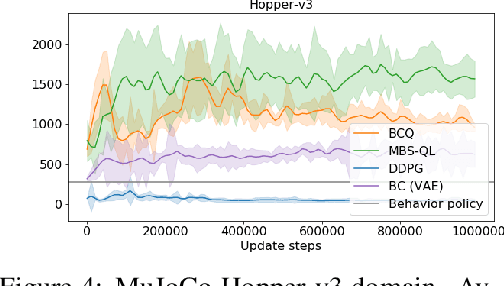
Batch reinforcement learning (RL) is important to apply RL algorithms to many high stakes tasks. Doing batch RL in a way that yields a reliable new policy in large domains is challenging: a new decision policy may visit states and actions outside the support of the batch data, and function approximation and optimization with limited samples can further increase the potential of learning policies with overly optimistic estimates of their future performance. Recent algorithms have shown promise but can still be overly optimistic in their expected outcomes. Theoretical work that provides strong guarantees on the performance of the output policy relies on a strong concentrability assumption, that makes it unsuitable for cases where the ratio between state-action distributions of behavior policy and some candidate policies is large. This is because in the traditional analysis, the error bound scales up with this ratio. We show that a small modification to Bellman optimality and evaluation back-up to take a more conservative update can have much stronger guarantees. In certain settings, they can find the approximately best policy within the state-action space explored by the batch data, without requiring a priori assumptions of concentrability. We highlight the necessity of our conservative update and the limitations of previous algorithms and analyses by illustrative MDP examples, and demonstrate an empirical comparison of our algorithm and other state-of-the-art batch RL baselines in standard benchmarks.
Learning Abstract Models for Strategic Exploration and Fast Reward Transfer
Jul 12, 2020
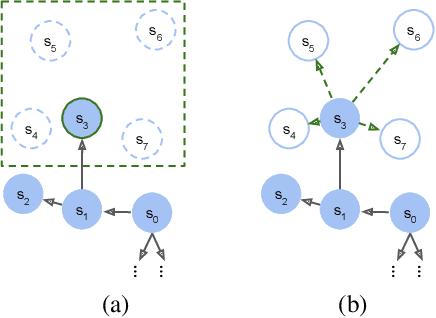

Model-based reinforcement learning (RL) is appealing because (i) it enables planning and thus more strategic exploration, and (ii) by decoupling dynamics from rewards, it enables fast transfer to new reward functions. However, learning an accurate Markov Decision Process (MDP) over high-dimensional states (e.g., raw pixels) is extremely challenging because it requires function approximation, which leads to compounding errors. Instead, to avoid compounding errors, we propose learning an abstract MDP over abstract states: low-dimensional coarse representations of the state (e.g., capturing agent position, ignoring other objects). We assume access to an abstraction function that maps the concrete states to abstract states. In our approach, we construct an abstract MDP, which grows through strategic exploration via planning. Similar to hierarchical RL approaches, the abstract actions of the abstract MDP are backed by learned subpolicies that navigate between abstract states. Our approach achieves strong results on three of the hardest Arcade Learning Environment games (Montezuma's Revenge, Pitfall!, and Private Eye), including superhuman performance on Pitfall! without demonstrations. After training on one task, we can reuse the learned abstract MDP for new reward functions, achieving higher reward in 1000x fewer samples than model-free methods trained from scratch.
Power-Constrained Bandits
Apr 13, 2020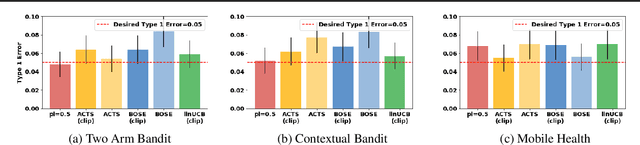

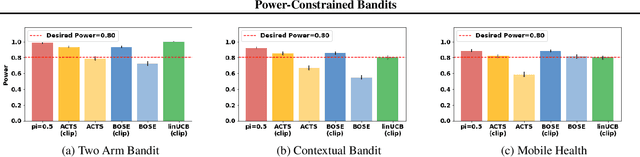
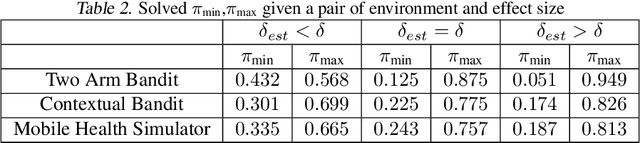
Contextual bandits often provide simple and effective personalization in decision making problems, making them popular in many domains including digital health. However, when bandits are deployed in the context of a scientific study, the aim is not only to personalize for an individual, but also to determine, with sufficient statistical power, whether or not the system's intervention is effective. In this work, we develop a set of constraints and a general meta-algorithm that can be used to both guarantee power constraints and minimize regret. Our results demonstrate a number of existing algorithms can be easily modified to satisfy the constraint without significant decrease in average return. We also show that our modification is also robust to a variety of model mis-specifications.
Value Driven Representation for Human-in-the-Loop Reinforcement Learning
Apr 02, 2020
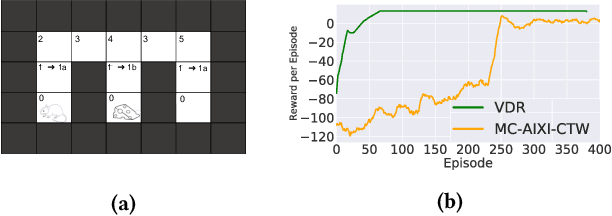
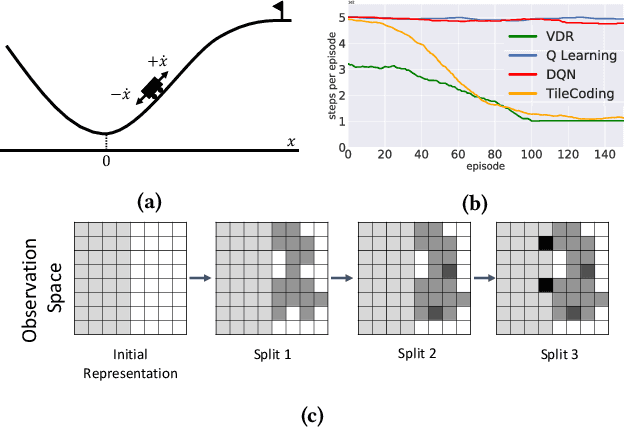
Interactive adaptive systems powered by Reinforcement Learning (RL) have many potential applications, such as intelligent tutoring systems. In such systems there is typically an external human system designer that is creating, monitoring and modifying the interactive adaptive system, trying to improve its performance on the target outcomes. In this paper we focus on algorithmic foundation of how to help the system designer choose the set of sensors or features to define the observation space used by reinforcement learning agent. We present an algorithm, value driven representation (VDR), that can iteratively and adaptively augment the observation space of a reinforcement learning agent so that is sufficient to capture a (near) optimal policy. To do so we introduce a new method to optimistically estimate the value of a policy using offline simulated Monte Carlo rollouts. We evaluate the performance of our approach on standard RL benchmarks with simulated humans and demonstrate significant improvement over prior baselines.
Off-policy Policy Evaluation For Sequential Decisions Under Unobserved Confounding
Mar 12, 2020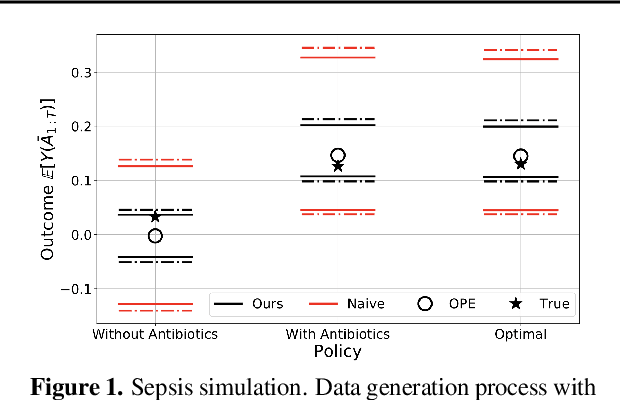
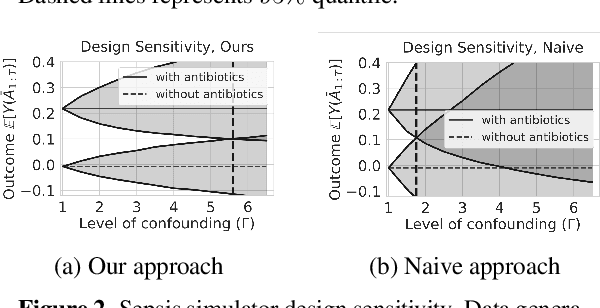
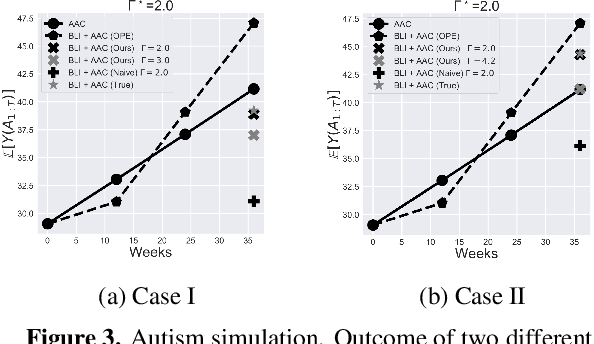
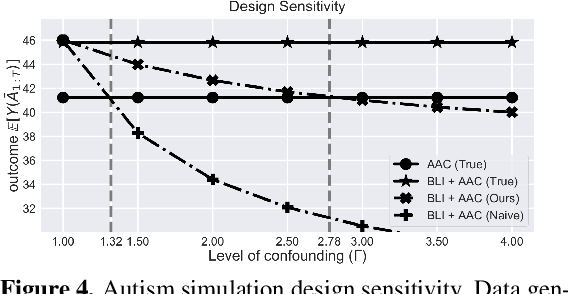
When observed decisions depend only on observed features, off-policy policy evaluation (OPE) methods for sequential decision making problems can estimate the performance of evaluation policies before deploying them. This assumption is frequently violated due to unobserved confounders, unrecorded variables that impact both the decisions and their outcomes. We assess robustness of OPE methods under unobserved confounding by developing worst-case bounds on the performance of an evaluation policy. When unobserved confounders can affect every decision in an episode, we demonstrate that even small amounts of per-decision confounding can heavily bias OPE methods. Fortunately, in a number of important settings found in healthcare, policy-making, operations, and technology, unobserved confounders may primarily affect only one of the many decisions made. Under this less pessimistic model of one-decision confounding, we propose an efficient loss-minimization-based procedure for computing worst-case bounds, and prove its statistical consistency. On two simulated healthcare examples---management of sepsis patients and developmental interventions for autistic children---where this is a reasonable model of confounding, we demonstrate that our method invalidates non-robust results and provides meaningful certificates of robustness, allowing reliable selection of policies even under unobserved confounding.
Learning Near Optimal Policies with Low Inherent Bellman Error
Mar 05, 2020
We study the exploration problem with approximate linear action-value functions in episodic reinforcement learning under the notion of low inherent Bellman error, a condition normally employed to show convergence of approximate value iteration. First we relate this condition to other common frameworks and show that it is strictly more general than the low rank (or linear) MDP assumption of prior work. Second we provide an algorithm with a high probability regret bound $\widetilde O(\sum_{t=1}^H d_t \sqrt{K} + \sum_{t=1}^H \sqrt{d_t} \IBE K)$ where $H$ is the horizon, $K$ is the number of episodes, $\IBE$ is the value if the inherent Bellman error and $d_t$ is the feature dimension at timestep $t$. In addition, we show that the result is unimprovable beyond constants and logs by showing a matching lower bound. This has two important consequences: 1) the algorithm has the optimal statistical rate for this setting which is more general than prior work on low-rank MDPs 2) the lack of closedness (measured by the inherent Bellman error) is only amplified by $\sqrt{d_t}$ despite working in the online setting. Finally, the algorithm reduces to the celebrated \textsc{LinUCB} when $H=1$ but with a different choice of the exploration parameter that allows handling misspecified contextual linear bandits. While computational tractability questions remain open for the MDP setting, this enriches the class of MDPs with a linear representation for the action-value function where statistically efficient reinforcement learning is possible.
Interpretable Off-Policy Evaluation in Reinforcement Learning by Highlighting Influential Transitions
Feb 14, 2020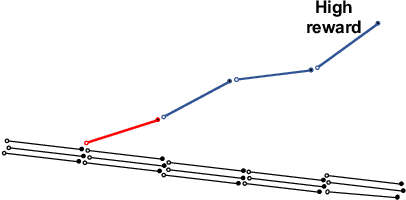
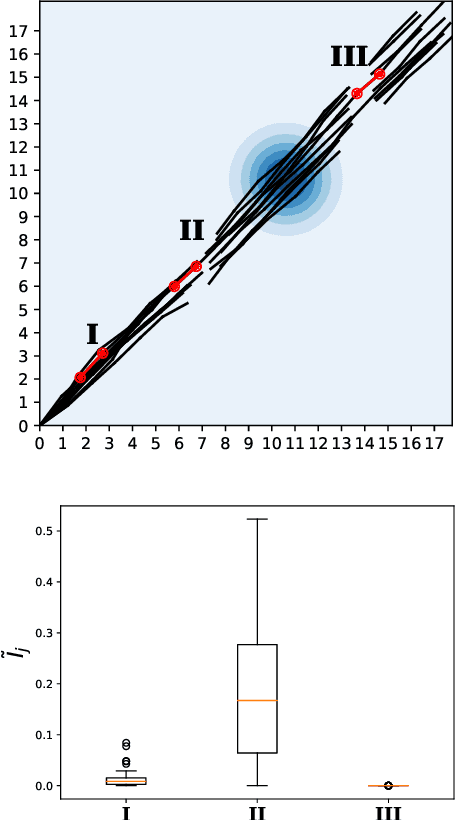
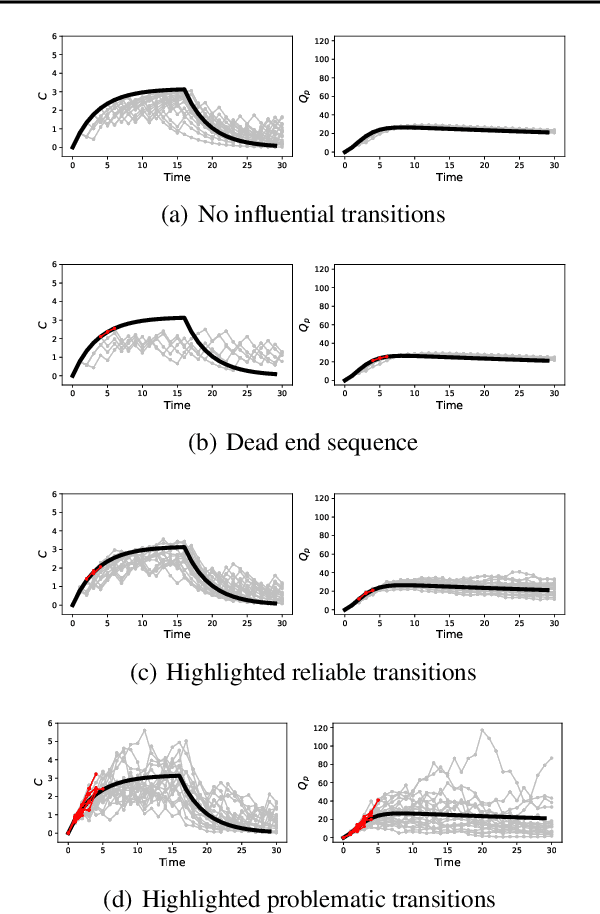
Off-policy evaluation in reinforcement learning offers the chance of using observational data to improve future outcomes in domains such as healthcare and education, but safe deployment in high stakes settings requires ways of assessing its validity. Traditional measures such as confidence intervals may be insufficient due to noise, limited data and confounding. In this paper we develop a method that could serve as a hybrid human-AI system, to enable human experts to analyze the validity of policy evaluation estimates. This is accomplished by highlighting observations in the data whose removal will have a large effect on the OPE estimate, and formulating a set of rules for choosing which ones to present to domain experts for validation. We develop methods to compute exactly the influence functions for fitted Q-evaluation with two different function classes: kernel-based and linear least squares. Experiments on medical simulations and real-world intensive care unit data demonstrate that our method can be used to identify limitations in the evaluation process and make evaluation more robust.
Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning
Jan 31, 2020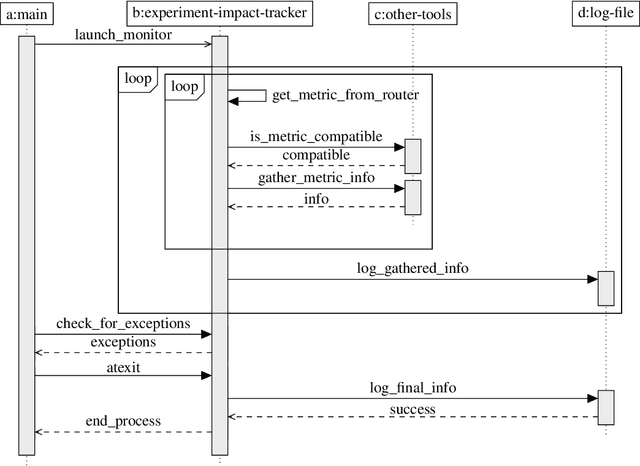
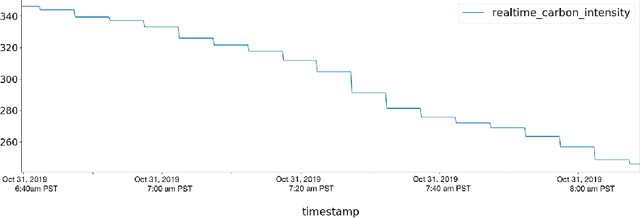
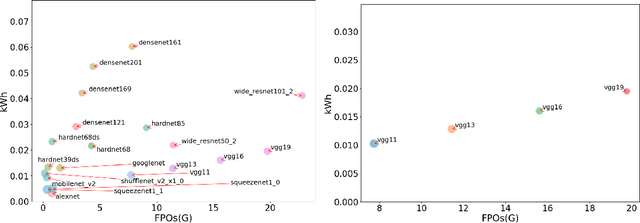
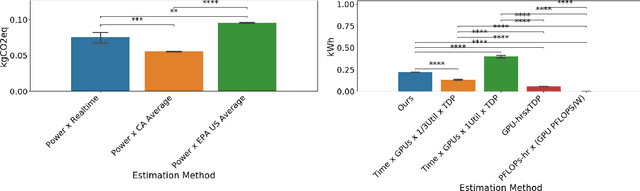
Accurate reporting of energy and carbon usage is essential for understanding the potential climate impacts of machine learning research. We introduce a framework that makes this easier by providing a simple interface for tracking realtime energy consumption and carbon emissions, as well as generating standardized online appendices. Utilizing this framework, we create a leaderboard for energy efficient reinforcement learning algorithms to incentivize responsible research in this area as an example for other areas of machine learning. Finally, based on case studies using our framework, we propose strategies for mitigation of carbon emissions and reduction of energy consumption. By making accounting easier, we hope to further the sustainable development of machine learning experiments and spur more research into energy efficient algorithms.