Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSublinear Optimal Policy Value Estimation in Contextual Bandits
Paper and Code
Dec 13, 2019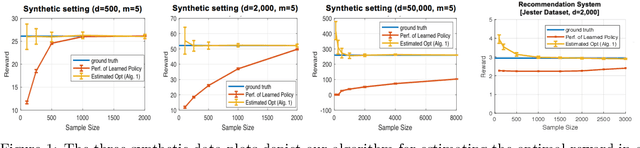
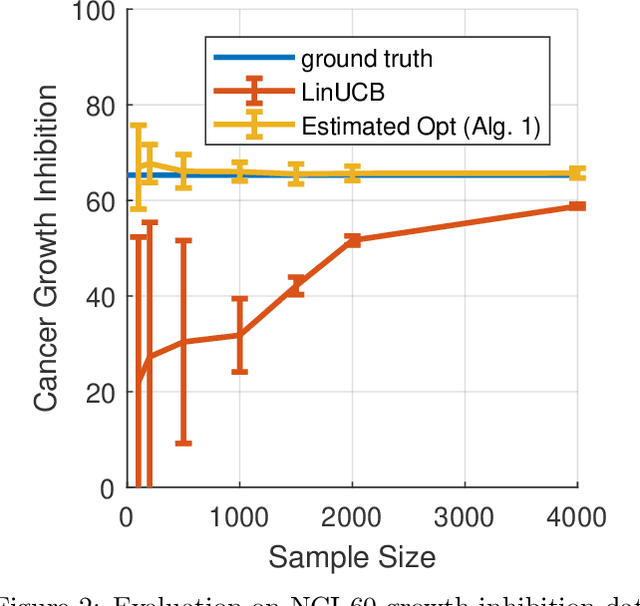
We study the problem of estimating the expected reward of the optimal policy in the stochastic disjoint linear bandit setting. We prove that for certain settings it is possible to obtain an accurate estimate of the optimal policy value even with a number of samples that is sublinear in the number that would be required to \emph{find} a policy that realizes a value close to this optima. We establish nearly matching information theoretic lower bounds, showing that our algorithm achieves near optimal estimation error. Finally, we demonstrate the effectiveness of our algorithm on joke recommendation and cancer inhibition dosage selection problems using real datasets.
* Extended to the mixture of Gaussians setting
View paper on