 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ontology for Unified Modeling of Tasks, Actions, Environments, and Capabilities in Personal Service Robotics
Sep 26, 2025



Personal service robots are increasingly used in domestic settings to assist older adults and people requiring support. Effective operation involves not only physical interaction but also the ability to interpret dynamic environments, understand tasks, and choose appropriate actions based on context. This requires integrating both hardware components (e.g. sensors, actuators) and software systems capable of reasoning about tasks, environments, and robot capabilities. Frameworks such as the Robot Operating System (ROS) provide open-source tools that help connect low-level hardware with higher-level functionalities. However, real-world deployments remain tightly coupled to specific platforms. As a result, solutions are often isolated and hard-coded, limiting interoperability, reusability, and knowledge sharing. Ontologies and knowledge graphs offer a structured way to represent tasks, environments, and robot capabilities. Existing ontologies, such as the Socio-physical Model of Activities (SOMA) and the Descriptive Ontology for Linguistic and Cognitive Engineering (DOLCE), provide models for activities, spatial relationships, and reasoning structures. However, they often focus on specific domains and do not fully capture the connection between environment, action, robot capabilities, and system-level integration. In this work, we propose the Ontology for roBOts and acTions (OntoBOT), which extends existing ontologies to provide a unified representation of tasks, actions, environments, and capabilities. Our contributions are twofold: (1) we unify these aspects into a cohesive ontology to support formal reasoning about task execution, and (2) we demonstrate its generalizability by evaluating competency questions across four embodied agents - TIAGo, HSR, UR3, and Stretch - showing how OntoBOT enables context-aware reasoning, task-oriented execution, and knowledge sharing in service robotics.
Exact Shapley Attributions in Quadratic-time for FANOVA Gaussian Processes
Aug 20, 2025



Shapley values are widely recognized as a principled method for attributing importance to input features in machine learning. However, the exact computation of Shapley values scales exponentially with the number of features, severely limiting the practical application of this powerful approach. The challenge is further compounded when the predictive model is probabilistic - as in Gaussian processes (GPs) - where the outputs are random variables rather than point estimates, necessitating additional computational effort in modeling higher-order moments. In this work, we demonstrate that for an important class of GPs known as FANOVA GP, which explicitly models all main effects and interactions, *exact* Shapley attributions for both local and global explanations can be computed in *quadratic time*. For local, instance-wise explanations, we define a stochastic cooperative game over function components and compute the exact stochastic Shapley value in quadratic time only, capturing both the expected contribution and uncertainty. For global explanations, we introduce a deterministic, variance-based value function and compute exact Shapley values that quantify each feature's contribution to the model's overall sensitivity. Our methods leverage a closed-form (stochastic) M\"{o}bius representation of the FANOVA decomposition and introduce recursive algorithms, inspired by Newton's identities, to efficiently compute the mean and variance of Shapley values. Our work enhances the utility of explainable AI, as demonstrated by empirical studies, by providing more scalable, axiomatically sound, and uncertainty-aware explanations for predictions generated by structured probabilistic models.
Establishing Shared Query Understanding in an Open Multi-Agent System
May 16, 2023



We propose a method that allows to develop shared understanding between two agents for the purpose of performing a task that requires cooperation. Our method focuses on efficiently establishing successful task-oriented communication in an open multi-agent system, where the agents do not know anything about each other and can only communicate via grounded interaction. The method aims to assist researchers that work on human-machine interaction or scenarios that require a human-in-the-loop, by defining interaction restrictions and efficiency metrics. To that end, we point out the challenges and limitations of such a (diverse) setup, while also restrictions and requirements which aim to ensure that high task performance truthfully reflects the extent to which the agents correctly understand each other. Furthermore, we demonstrate a use-case where our method can be applied for the task of cooperative query answering. We design the experiments by modifying an established ontology alignment benchmark. In this example, the agents want to query each other, while representing different databases, defined in their own ontologies that contain different and incomplete knowledge. Grounded interaction here has the form of examples that consists of common instances, for which the agents are expected to have similar knowledge. Our experiments demonstrate successful communication establishment under the required restrictions, and compare different agent policies that aim to solve the task in an efficient manner.
Leveraging class abstraction for commonsense reinforcement learning via residual policy gradient methods
Jan 28, 2022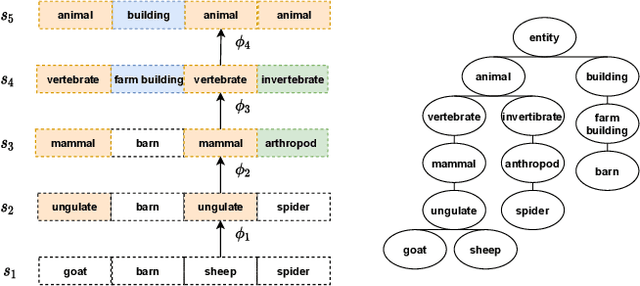
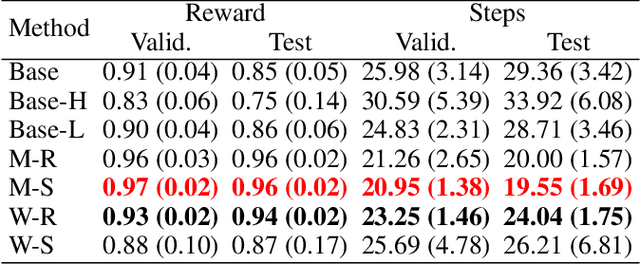
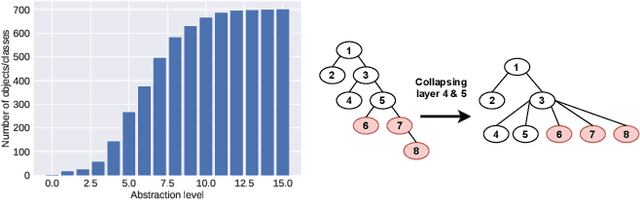

Enabling reinforcement learning (RL) agents to leverage a knowledge base while learning from experience promises to advance RL in knowledge intensive domains. However, it has proven difficult to leverage knowledge that is not manually tailored to the environment. We propose to use the subclass relationships present in open-source knowledge graphs to abstract away from specific objects. We develop a residual policy gradient method that is able to integrate knowledge across different abstraction levels in the class hierarchy. Our method results in improved sample efficiency and generalisation to unseen objects in commonsense games, but we also investigate failure modes, such as excessive noise in the extracted class knowledge or environments with little class structure.
Local Explanations for Clinical Search Engine results
Oct 19, 2021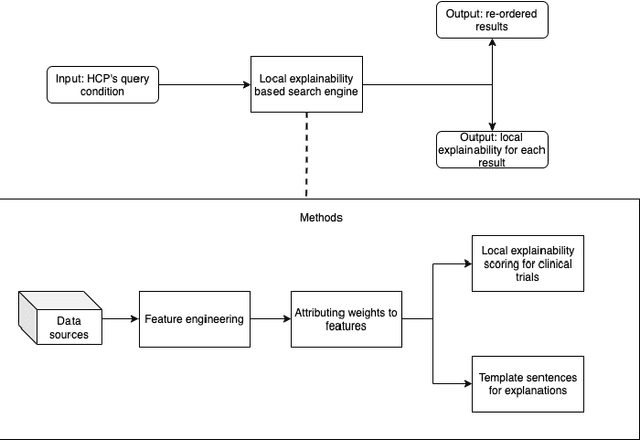
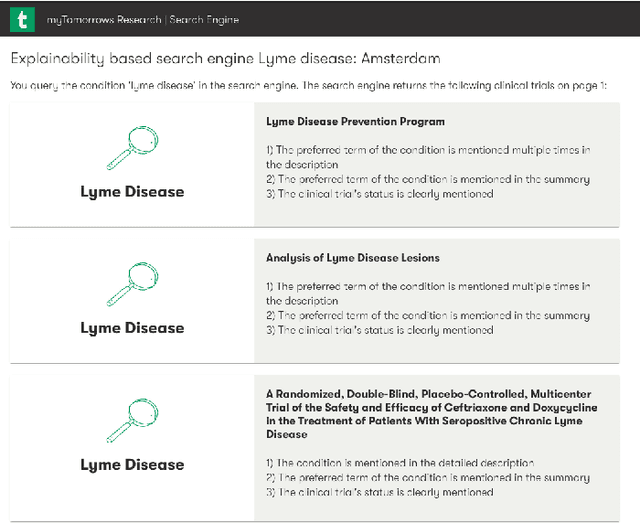
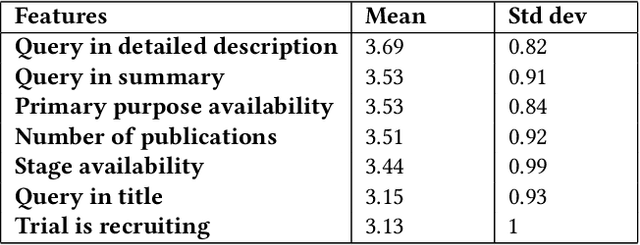
Health care professionals rely on treatment search engines to efficiently find adequate clinical trials and early access programs for their patients. However, doctors lose trust in the system if its underlying processes are unclear and unexplained. In this paper, a model-agnostic explainable method is developed to provide users with further information regarding the reasons why a clinical trial is retrieved in response to a query. To accomplish this, the engine generates features from clinical trials using by using a knowledge graph, clinical trial data and additional medical resources. and a crowd-sourcing methodology is used to determine their importance. Grounded on the proposed methodology, the rationale behind retrieving the clinical trials is explained in layman's terms so that healthcare processionals can effortlessly perceive them. In addition, we compute an explainability score for each of the retrieved items, according to which the items can be ranked. The experiments validated by medical professionals suggest that the proposed methodology induces trust in targeted as well as in non-targeted users, and provide them with reliable explanations and ranking of retrieved items.
A Multi-layer LSTM-based Approach for Robot Command Interaction Modeling
Nov 13, 2018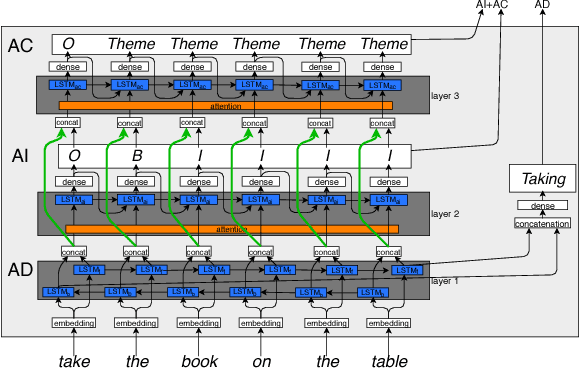
As the first robotic platforms slowly approach our everyday life, we can imagine a near future where service robots will be easily accessible by non-expert users through vocal interfaces. The capability of managing natural language would indeed speed up the process of integrating such platform in the ordinary life. Semantic parsing is a fundamental task of the Natural Language Understanding process, as it allows extracting the meaning of a user utterance to be used by a machine. In this paper, we present a preliminary study to semantically parse user vocal commands for a House Service robot, using a multi-layer Long-Short Term Memory neural network with attention mechanism. The system is trained on the Human Robot Interaction Corpus, and it is preliminarily compared with previous approaches.