 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Clinical Note Summarization
Apr 18, 2021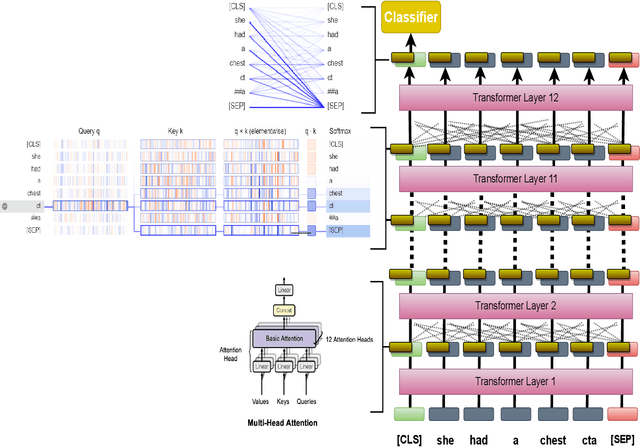

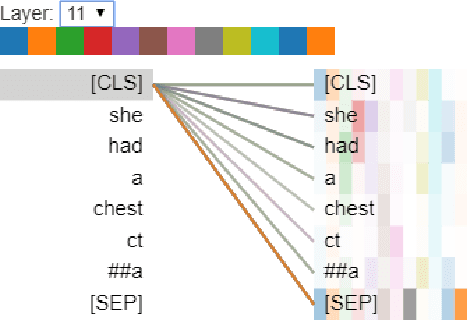
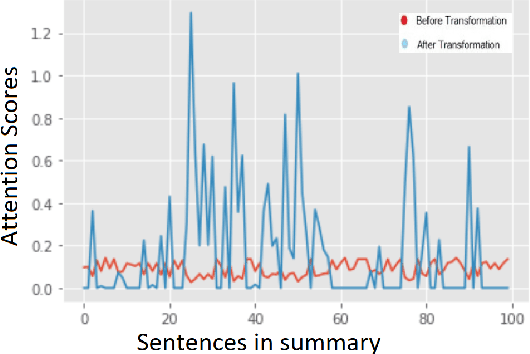
The trend of deploying digital systems in numerous industries has induced a hike in recording digital information. The health sector has observed a large adoption of digital devices and systems generating large volumes of personal medical health records. Electronic health records contain valuable information for retrospective and prospective analysis that is often not entirely exploited because of the dense information storage. The crude purpose of condensing health records is to select the information that holds most characteristics of the original documents based on reported disease. These summaries may boost diagnosis and extend a doctor's interaction time with the patient during a high workload situation like the COVID-19 pandemic. In this paper, we propose a multi-head attention-based mechanism to perform extractive summarization of meaningful phrases in clinical notes. This method finds major sentences for a summary by correlating tokens, segments and positional embeddings. The model outputs attention scores that are statistically transformed to extract key phrases and can be used for a projection on the heat-mapping tool for visual and human use.
A Response Retrieval Approach for Dialogue Using a Multi-Attentive Transformer
Dec 15, 2020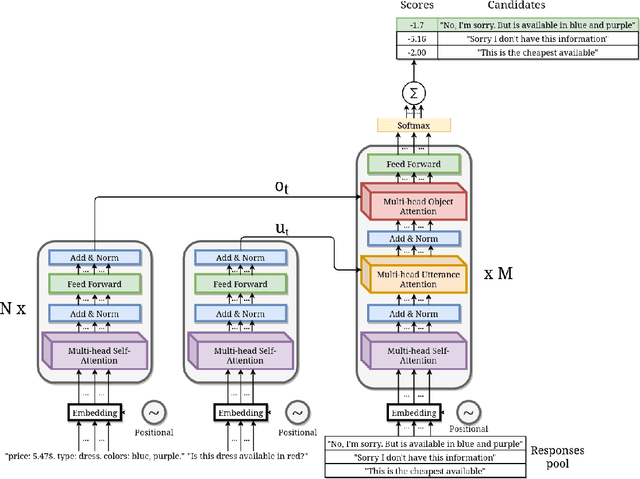
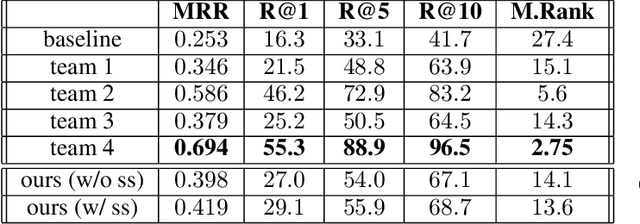
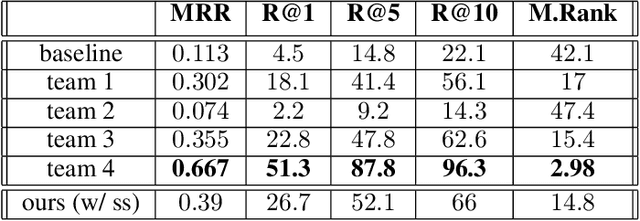
This paper presents our work for the ninth edition of the Dialogue System Technology Challenge (DSTC9). Our solution addresses the track number four: Simulated Interactive MultiModal Conversations. The task consists in providing an algorithm able to simulate a shopping assistant that supports the user with his/her requests. We address the task of response retrieval, that is the task of retrieving the most appropriate agent response from a pool of response candidates. Our approach makes use of a neural architecture based on transformer with a multi-attentive structure that conditions the response of the agent on the request made by the user and on the product the user is referring to. Final experiments on the SIMMC Fashion Dataset show that our approach achieves the second best scores on all the retrieval metrics defined by the organizers. The source code is available at https://github.com/D2KLab/dstc9-SIMMC.
Understanding Twitter Engagement with a Click-Through Rate-based Method
Sep 30, 2020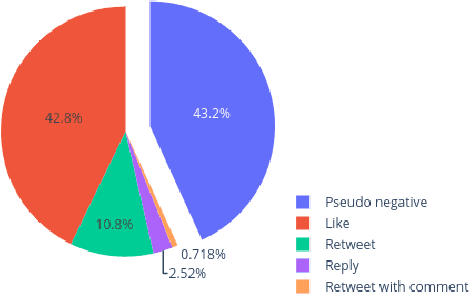

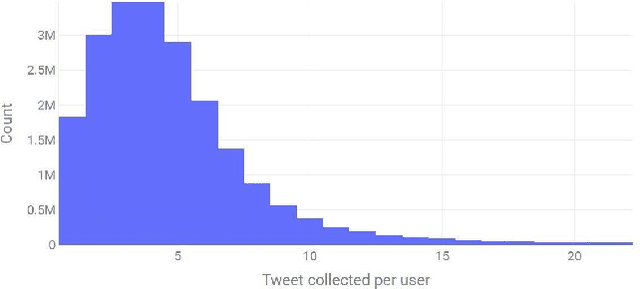
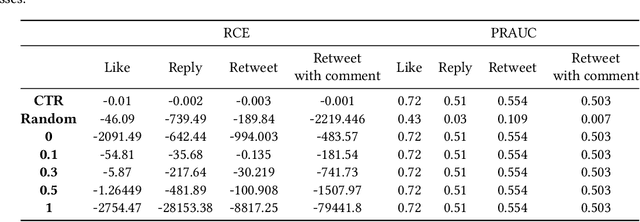
This paper presents the POLINKS solution to the RecSys Challenge 2020 that ranked 6th in the final leaderboard. We analyze the performance of our solution that utilizes the click-through rate value to address the challenge task, we compare it with a gradient boosting model, and we report the quality indicators utilized for computing the final leaderboard.
A Multi-layer LSTM-based Approach for Robot Command Interaction Modeling
Nov 13, 2018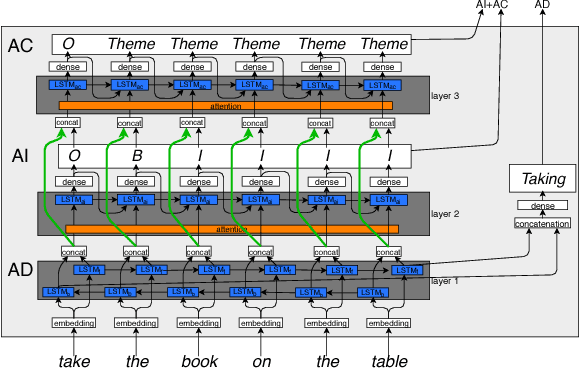
As the first robotic platforms slowly approach our everyday life, we can imagine a near future where service robots will be easily accessible by non-expert users through vocal interfaces. The capability of managing natural language would indeed speed up the process of integrating such platform in the ordinary life. Semantic parsing is a fundamental task of the Natural Language Understanding process, as it allows extracting the meaning of a user utterance to be used by a machine. In this paper, we present a preliminary study to semantically parse user vocal commands for a House Service robot, using a multi-layer Long-Short Term Memory neural network with attention mechanism. The system is trained on the Human Robot Interaction Corpus, and it is preliminarily compared with previous approaches.
Analysis of Named Entity Recognition and Linking for Tweets
Oct 27, 2014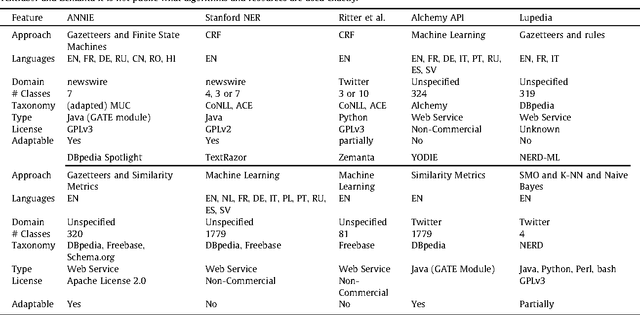
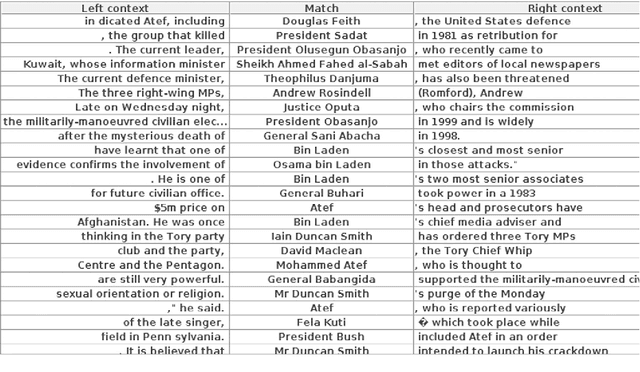

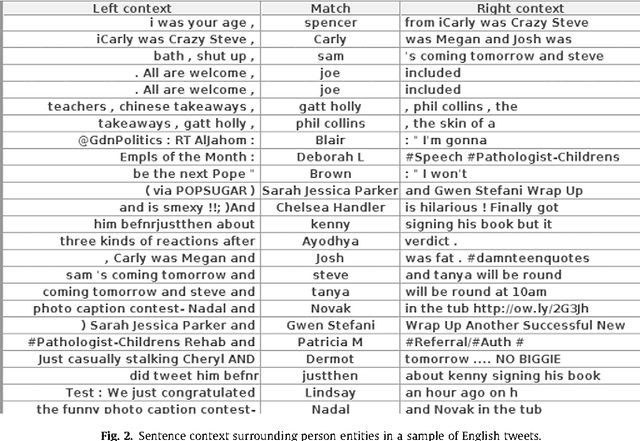
Applying natural language processing for mining and intelligent information access to tweets (a form of microblog) is a challenging, emerging research area. Unlike carefully authored news text and other longer content, tweets pose a number of new challenges, due to their short, noisy, context-dependent, and dynamic nature. Information extraction from tweets is typically performed in a pipeline, comprising consecutive stages of language identification, tokenisation, part-of-speech tagging, named entity recognition and entity disambiguation (e.g. with respect to DBpedia). In this work, we describe a new Twitter entity disambiguation dataset, and conduct an empirical analysis of named entity recognition and disambiguation, investigating how robust a number of state-of-the-art systems are on such noisy texts, what the main sources of error are, and which problems should be further investigated to improve the state of the art.
* 35 pages, accepted to journal Information Processing and Management