 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioCube: A Multimodal Dataset for Biodiversity Research
May 16, 2025



Biodiversity research requires complete and detailed information to study ecosystem dynamics at different scales. Employing data-driven methods like Machine Learning is getting traction in ecology and more specific biodiversity, offering alternative modelling pathways. For these methods to deliver accurate results there is the need for large, curated and multimodal datasets that offer granular spatial and temporal resolutions. In this work, we introduce BioCube, a multimodal, fine-grained global dataset for ecology and biodiversity research. BioCube incorporates species observations through images, audio recordings and descriptions, environmental DNA, vegetation indices, agricultural, forest, land indicators, and high-resolution climate variables. All observations are geospatially aligned under the WGS84 geodetic system, spanning from 2000 to 2020. The dataset will become available at https://huggingface.co/datasets/BioDT/BioCube while the acquisition and processing code base at https://github.com/BioDT/bfm-data.
A Multi-layer LSTM-based Approach for Robot Command Interaction Modeling
Nov 13, 2018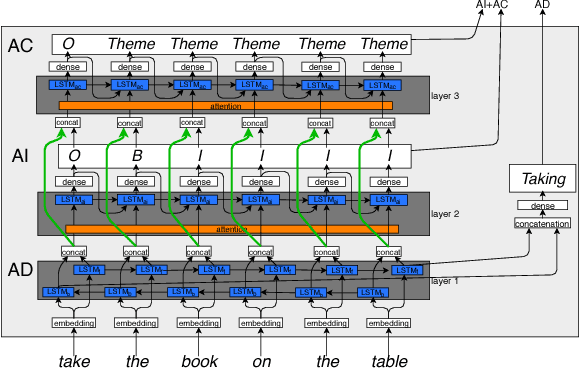
As the first robotic platforms slowly approach our everyday life, we can imagine a near future where service robots will be easily accessible by non-expert users through vocal interfaces. The capability of managing natural language would indeed speed up the process of integrating such platform in the ordinary life. Semantic parsing is a fundamental task of the Natural Language Understanding process, as it allows extracting the meaning of a user utterance to be used by a machine. In this paper, we present a preliminary study to semantically parse user vocal commands for a House Service robot, using a multi-layer Long-Short Term Memory neural network with attention mechanism. The system is trained on the Human Robot Interaction Corpus, and it is preliminarily compared with previous approaches.