 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
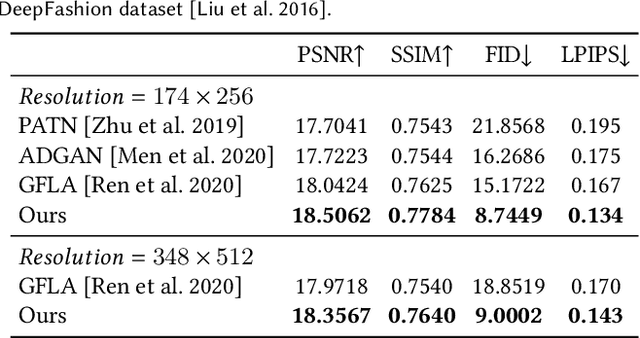


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Ensembling with Deep Generative Views
Apr 29, 2021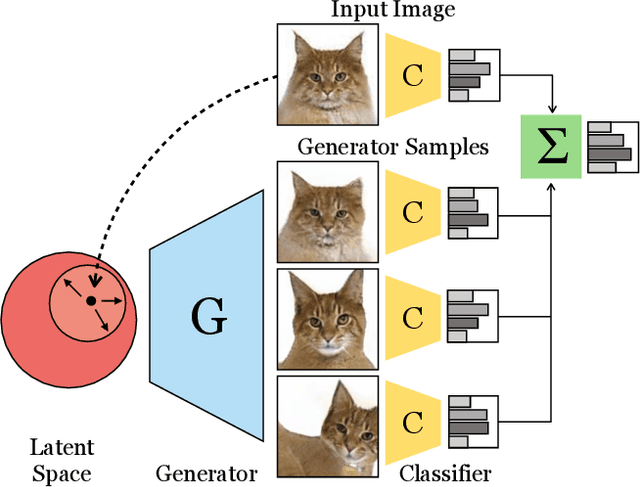
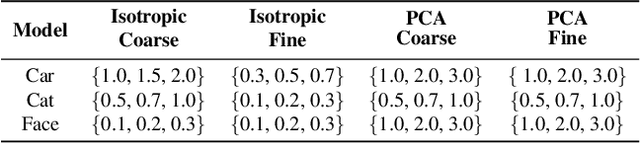

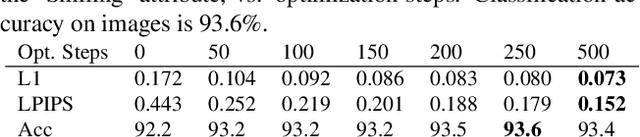
Recent generative models can synthesize "views" of artificial images that mimic real-world variations, such as changes in color or pose, simply by learning from unlabeled image collections. Here, we investigate whether such views can be applied to real images to benefit downstream analysis tasks such as image classification. Using a pretrained generator, we first find the latent code corresponding to a given real input image. Applying perturbations to the code creates natural variations of the image, which can then be ensembled together at test-time. We use StyleGAN2 as the source of generative augmentations and investigate this setup on classification tasks involving facial attributes, cat faces, and cars. Critically, we find that several design decisions are required towards making this process work; the perturbation procedure, weighting between the augmentations and original image, and training the classifier on synthesized images can all impact the result. Currently, we find that while test-time ensembling with GAN-based augmentations can offer some small improvements, the remaining bottlenecks are the efficiency and accuracy of the GAN reconstructions, coupled with classifier sensitivities to artifacts in GAN-generated images.
Few-shot Image Generation via Cross-domain Correspondence
Apr 13, 2021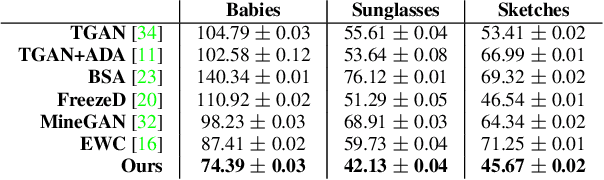

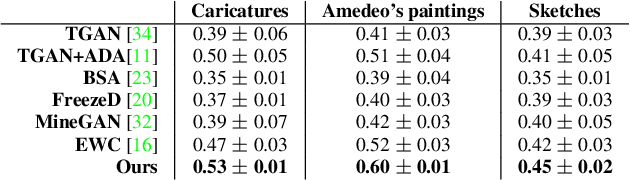
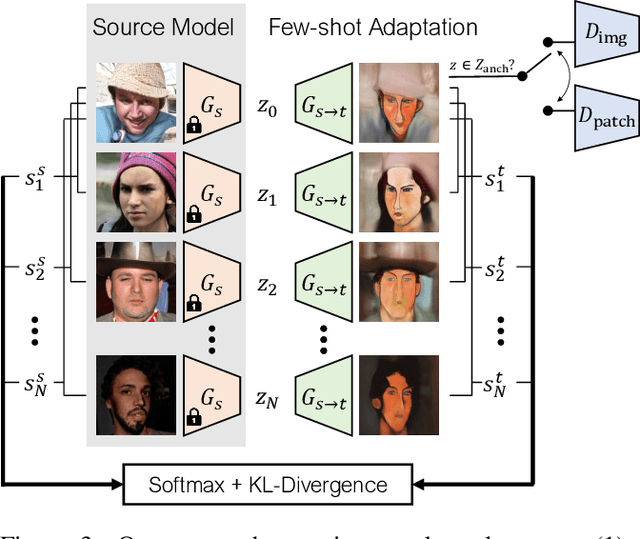
Training generative models, such as GANs, on a target domain containing limited examples (e.g., 10) can easily result in overfitting. In this work, we seek to utilize a large source domain for pretraining and transfer the diversity information from source to target. We propose to preserve the relative similarities and differences between instances in the source via a novel cross-domain distance consistency loss. To further reduce overfitting, we present an anchor-based strategy to encourage different levels of realism over different regions in the latent space. With extensive results in both photorealistic and non-photorealistic domains, we demonstrate qualitatively and quantitatively that our few-shot model automatically discovers correspondences between source and target domains and generates more diverse and realistic images than previous methods.
Modulated Periodic Activations for Generalizable Local Functional Representations
Apr 08, 2021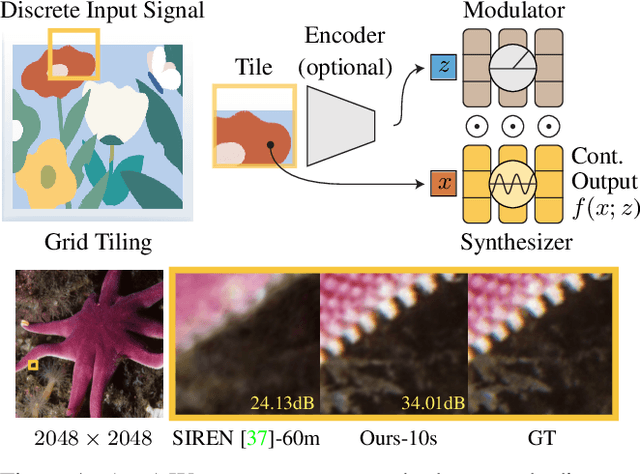
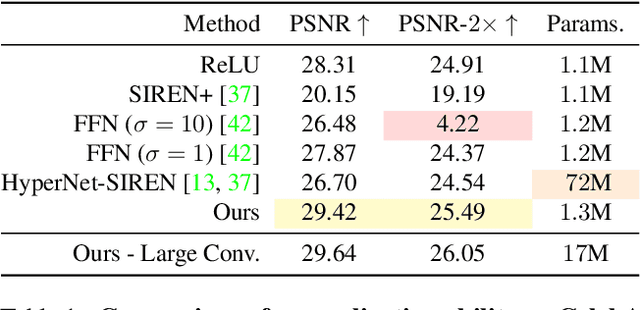
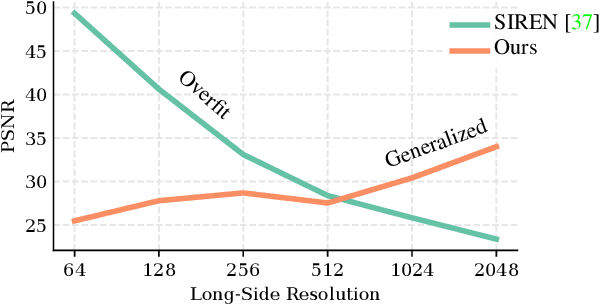
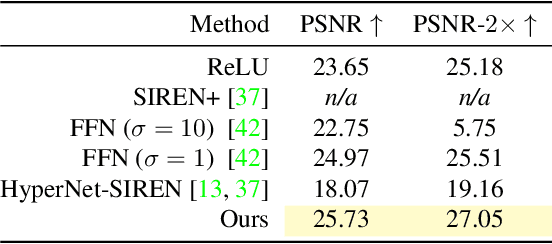
Multi-Layer Perceptrons (MLPs) make powerful functional representations for sampling and reconstruction problems involving low-dimensional signals like images,shapes and light fields. Recent works have significantly improved their ability to represent high-frequency content by using periodic activations or positional encodings. This often came at the expense of generalization: modern methods are typically optimized for a single signal. We present a new representation that generalizes to multiple instances and achieves state-of-the-art fidelity. We use a dual-MLP architecture to encode the signals. A synthesis network creates a functional mapping from a low-dimensional input (e.g. pixel-position) to the output domain (e.g. RGB color). A modulation network maps a latent code corresponding to the target signal to parameters that modulate the periodic activations of the synthesis network. We also propose a local-functional representation which enables generalization. The signal's domain is partitioned into a regular grid,with each tile represented by a latent code. At test time, the signal is encoded with high-fidelity by inferring (or directly optimizing) the latent code-book. Our approach produces generalizable functional representations of images, videos and shapes, and achieves higher reconstruction quality than prior works that are optimized for a single signal.
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
Mar 31, 2021
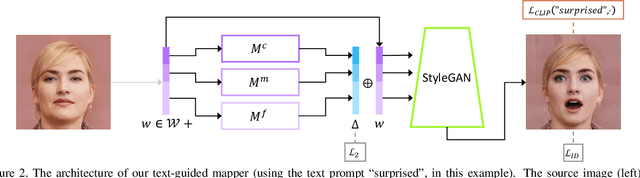


Inspired by the ability of StyleGAN to generate highly realistic images in a variety of domains, much recent work has focused on understanding how to use the latent spaces of StyleGAN to manipulate generated and real images. However, discovering semantically meaningful latent manipulations typically involves painstaking human examination of the many degrees of freedom, or an annotated collection of images for each desired manipulation. In this work, we explore leveraging the power of recently introduced Contrastive Language-Image Pre-training (CLIP) models in order to develop a text-based interface for StyleGAN image manipulation that does not require such manual effort. We first introduce an optimization scheme that utilizes a CLIP-based loss to modify an input latent vector in response to a user-provided text prompt. Next, we describe a latent mapper that infers a text-guided latent manipulation step for a given input image, allowing faster and more stable text-based manipulation. Finally, we present a method for mapping a text prompts to input-agnostic directions in StyleGAN's style space, enabling interactive text-driven image manipulation. Extensive results and comparisons demonstrate the effectiveness of our approaches.
TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transformations
Mar 29, 2021
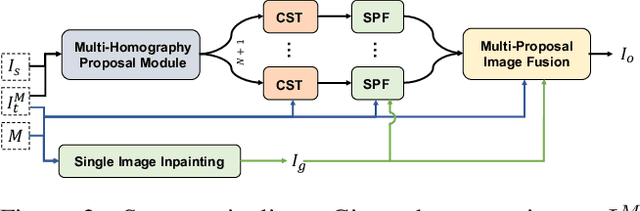
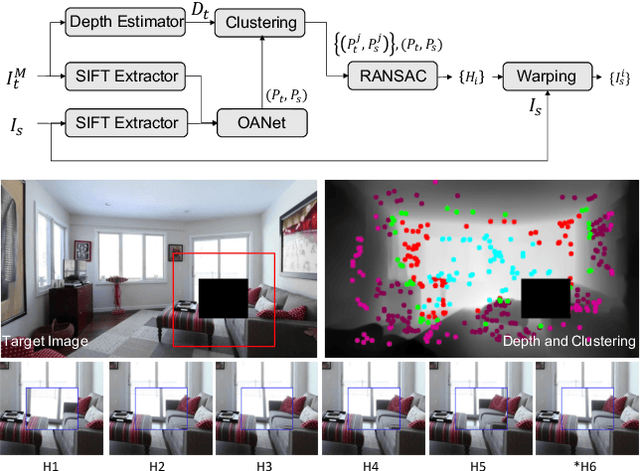
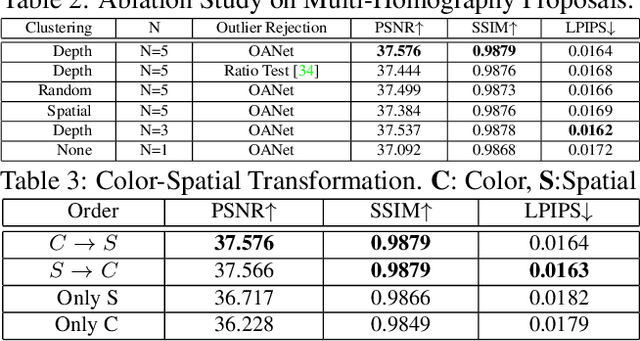
Image inpainting is the task of plausibly restoring missing pixels within a hole region that is to be removed from a target image. Most existing technologies exploit patch similarities within the image, or leverage large-scale training data to fill the hole using learned semantic and texture information. However, due to the ill-posed nature of the inpainting task, such methods struggle to complete larger holes containing complicated scenes. In this paper, we propose TransFill, a multi-homography transformed fusion method to fill the hole by referring to another source image that shares scene contents with the target image. We first align the source image to the target image by estimating multiple homographies guided by different depth levels. We then learn to adjust the color and apply a pixel-level warping to each homography-warped source image to make it more consistent with the target. Finally, a pixel-level fusion module is learned to selectively merge the different proposals. Our method achieves state-of-the-art performance on pairs of images across a variety of wide baselines and color differences, and generalizes to user-provided image pairs.
CharacterGAN: Few-Shot Keypoint Character Animation and Reposing
Feb 05, 2021
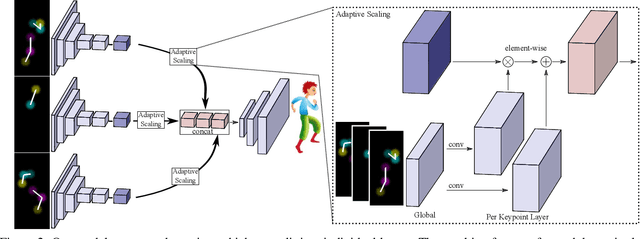
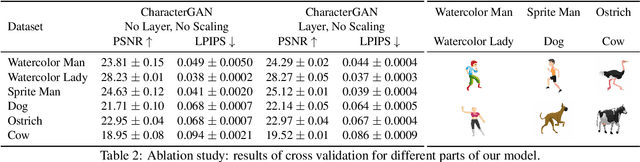

We introduce CharacterGAN, a generative model that can be trained on only a few samples (8 - 15) of a given character. Our model generates novel poses based on keypoint locations, which can be modified in real time while providing interactive feedback, allowing for intuitive reposing and animation. Since we only have very limited training samples, one of the key challenges lies in how to address (dis)occlusions, e.g. when a hand moves behind or in front of a body. To address this, we introduce a novel layering approach which explicitly splits the input keypoints into different layers which are processed independently. These layers represent different parts of the character and provide a strong implicit bias that helps to obtain realistic results even with strong (dis)occlusions. To combine the features of individual layers we use an adaptive scaling approach conditioned on all keypoints. Finally, we introduce a mask connectivity constraint to reduce distortion artifacts that occur with extreme out-of-distribution poses at test time. We show that our approach outperforms recent baselines and creates realistic animations for diverse characters. We also show that our model can handle discrete state changes, for example a profile facing left or right, that the different layers do indeed learn features specific for the respective keypoints in those layers, and that our model scales to larger datasets when more data is available.
Spatially-Adaptive Pixelwise Networks for Fast Image Translation
Dec 05, 2020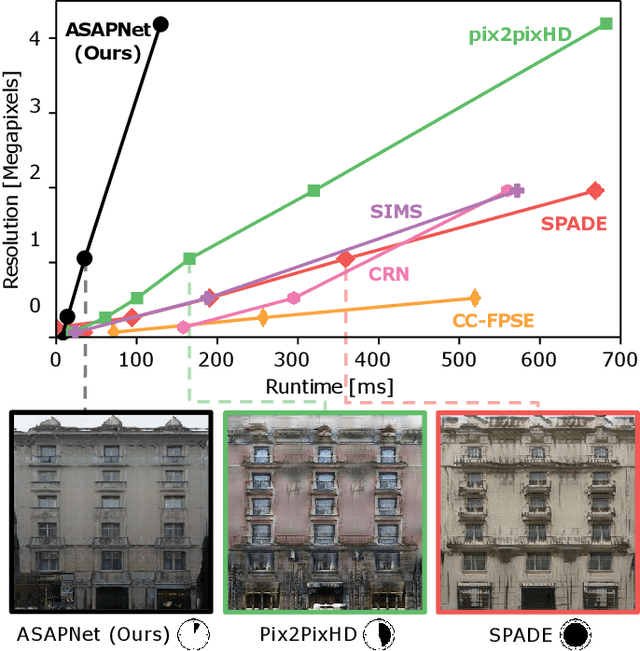

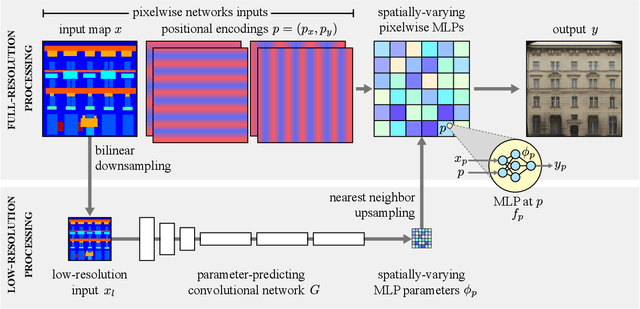
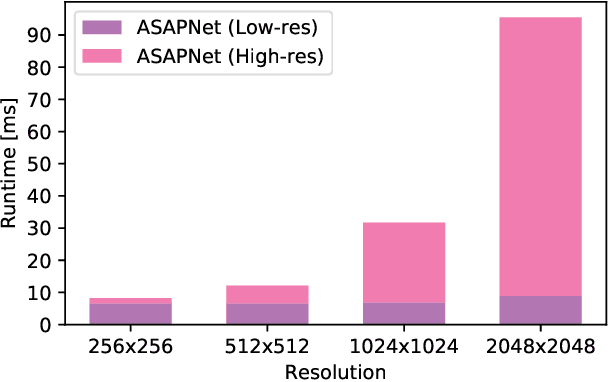
We introduce a new generator architecture, aimed at fast and efficient high-resolution image-to-image translation. We design the generator to be an extremely lightweight function of the full-resolution image. In fact, we use pixel-wise networks; that is, each pixel is processed independently of others, through a composition of simple affine transformations and nonlinearities. We take three important steps to equip such a seemingly simple function with adequate expressivity. First, the parameters of the pixel-wise networks are spatially varying so they can represent a broader function class than simple 1x1 convolutions. Second, these parameters are predicted by a fast convolutional network that processes an aggressively low-resolution representation of the input; Third, we augment the input image with a sinusoidal encoding of spatial coordinates, which provides an effective inductive bias for generating realistic novel high-frequency image content. As a result, our model is up to 18x faster than state-of-the-art baselines. We achieve this speedup while generating comparable visual quality across different image resolutions and translation domains.
Few-shot Image Generation with Elastic Weight Consolidation
Dec 04, 2020

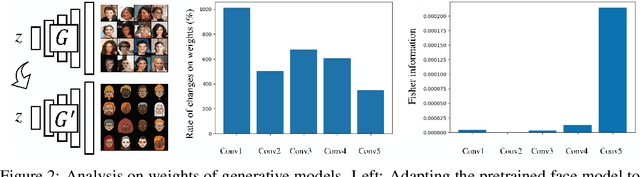
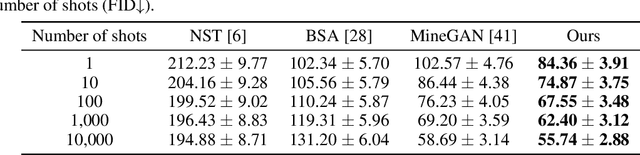
Few-shot image generation seeks to generate more data of a given domain, with only few available training examples. As it is unreasonable to expect to fully infer the distribution from just a few observations (e.g., emojis), we seek to leverage a large, related source domain as pretraining (e.g., human faces). Thus, we wish to preserve the diversity of the source domain, while adapting to the appearance of the target. We adapt a pretrained model, without introducing any additional parameters, to the few examples of the target domain. Crucially, we regularize the changes of the weights during this adaptation, in order to best preserve the information of the source dataset, while fitting the target. We demonstrate the effectiveness of our algorithm by generating high-quality results of different target domains, including those with extremely few examples (e.g., <10). We also analyze the performance of our method with respect to some important factors, such as the number of examples and the dissimilarity between the source and target domain.
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
Dec 03, 2020
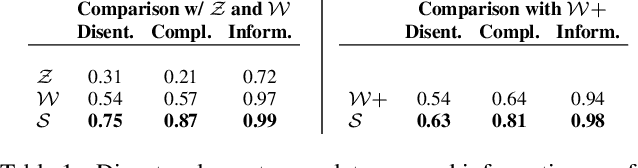
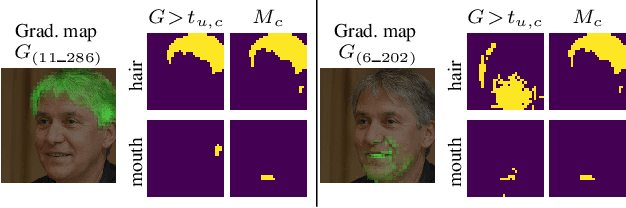
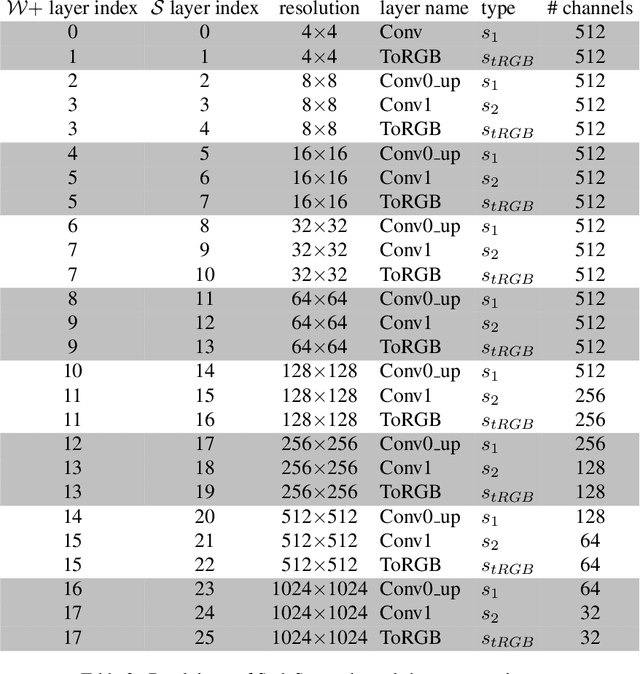
We explore and analyze the latent style space of StyleGAN2, a state-of-the-art architecture for image generation, using models pretrained on several different datasets. We first show that StyleSpace, the space of channel-wise style parameters, is significantly more disentangled than the other intermediate latent spaces explored by previous works. Next, we describe a method for discovering a large collection of style channels, each of which is shown to control a distinct visual attribute in a highly localized and disentangled manner. Third, we propose a simple method for identifying style channels that control a specific attribute, using a pretrained classifier or a small number of example images. Manipulation of visual attributes via these StyleSpace controls is shown to be better disentangled than via those proposed in previous works. To show this, we make use of a newly proposed Attribute Dependency metric. Finally, we demonstrate the applicability of StyleSpace controls to the manipulation of real images. Our findings pave the way to semantically meaningful and well-disentangled image manipulations via simple and intuitive interfaces.