 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
Sep 05, 2023



The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
Shape My Face: Registering 3D Face Scans by Surface-to-Surface Translation
Dec 16, 2020

Existing surface registration methods focus on fitting in-sample data with little to no generalization ability and require both heavy pre-processing and careful hand-tuning. In this paper, we cast the registration task as a surface-to-surface translation problem, and design a model to reliably capture the latent geometric information directly from raw 3D face scans. We introduce Shape-My-Face (SMF), a powerful encoder-decoder architecture based on an improved point cloud encoder, a novel visual attention mechanism, graph convolutional decoders with skip connections, and a specialized mouth model that we smoothly integrate with the mesh convolutions. Compared to the previous state-of-the-art learning algorithms for non-rigid registration of face scans, SMF only requires the raw data to be rigidly aligned (with scaling) with a pre-defined face template. Additionally, our model provides topologically-sound meshes with minimal supervision, offers faster training time, has orders of magnitude fewer trainable parameters, is more robust to noise, and can generalize to previously unseen datasets. We extensively evaluate the quality of our registrations on diverse data. We demonstrate the robustness and generalizability of our model with in-the-wild face scans across different modalities, sensor types, and resolutions. Finally, we show that, by learning to register scans, SMF produces a hybrid linear and non-linear morphable model that can be used for generation, shape morphing, and expression transfer through manipulation of the latent space, including in-the-wild. We train SMF on a dataset of human faces comprising 9 large-scale databases on commodity hardware.
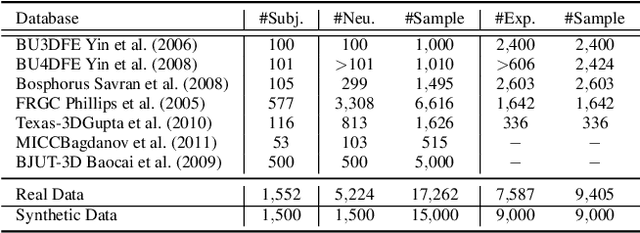
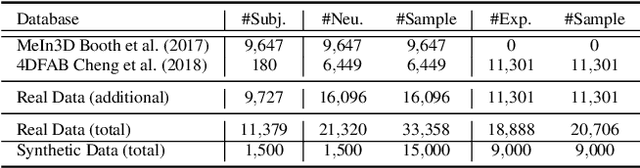
Towards a complete 3D morphable model of the human head
Nov 18, 2019

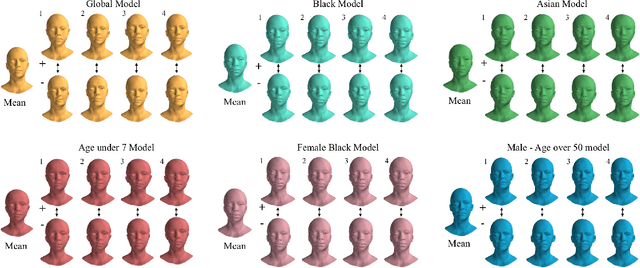
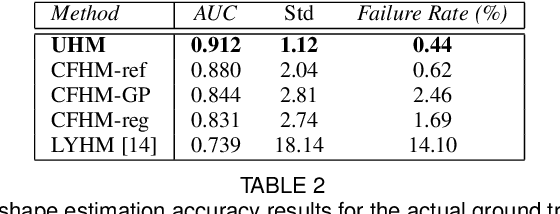
Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D shapes and textures of an object class. Here we present the most complete 3DMM of the human head to date that includes face, cranium, ears, eyes, teeth and tongue. To achieve this, we propose two methods for combining existing 3DMMs of different overlapping head parts: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Thus we build a new combined face-and-head shape model that blends the variability and facial detail of an existing face model (the LSFM) with the full head modelling capability of an existing head model (the LYHM). Then we construct and fuse a highly-detailed ear model to extend the variation of the ear shape. Eye and eye region models are incorporated into the head model, along with basic models of the teeth, tongue and inner mouth cavity. The new model achieves state-of-the-art performance. We use our model to reconstruct full head representations from single, unconstrained images allowing us to parameterize craniofacial shape and texture, along with the ear shape, eye gaze and eye color.
Hybrid Robotic-assisted Frameworks for Endomicroscopy Scanning in Retinal Surgeries
Sep 15, 2019
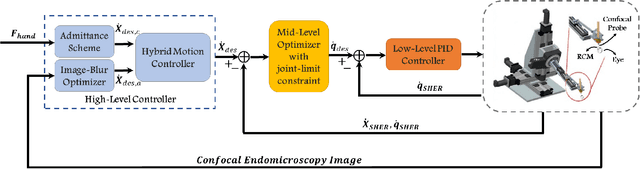
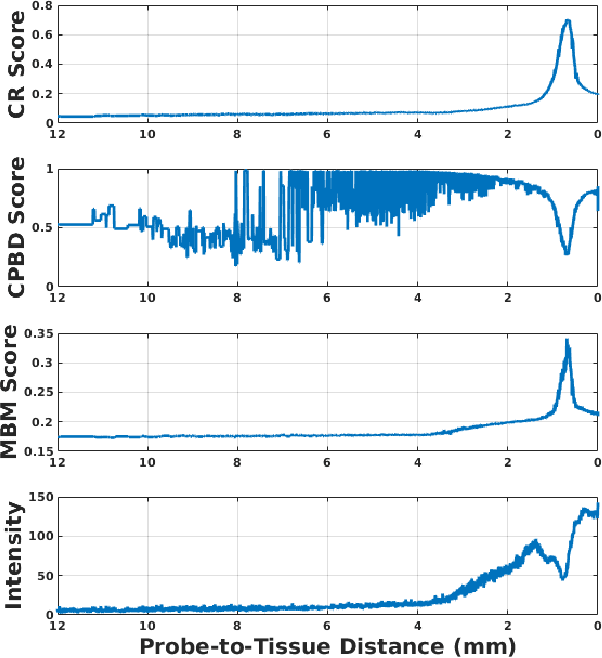
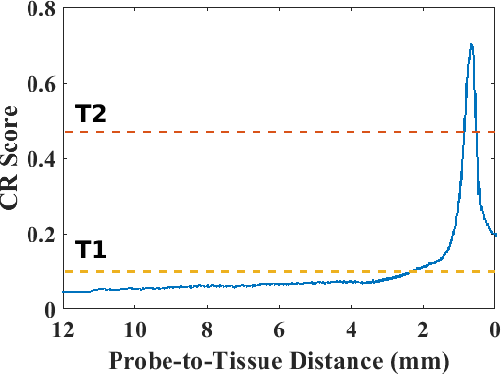
High-resolution real-time imaging at cellular levelin retinal surgeries is very challenging due to extremely confinedspace within the eyeball and lack of appropriate modalities.Probe-based confocal laser endomicroscopy (pCLE) system,which has a small footprint and provides highly-magnified im-ages, can be a potential imaging modality for improved diagnosis.The ability to visualize in cellular-level the retinal pigmentepithelium and the chorodial blood vessels underneath canprovide useful information for surgical outcomes in conditionssuch as retinal detachment. However, the adoption of pCLE islimited due to narrow field of view and micron-level range offocus. The physiological tremor of surgeons' hand also deterioratethe image quality considerably and leads to poor imaging results. In this paper, a novel image-based hybrid motion controlapproach is proposed to mitigate challenges of using pCLEin retinal surgeries. The proposed framework enables sharedcontrol of the pCLE probe by a surgeon to scan the tissueprecisely without hand tremors and an auto-focus image-basedcontrol algorithm that optimizes quality of pCLE images. Thecontrol strategy is deployed on two semi-autonomous frameworks: cooperative and teleoperated. Both frameworks consist of theSteady-Hand Eye Robot (SHER), whose end-effector holds thepCLE probe...