 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCONE-GAN: Semantic Contrastive learning-based Generative Adversarial Network for an end-to-end image translation
Nov 07, 2023



SCONE-GAN presents an end-to-end image translation, which is shown to be effective for learning to generate realistic and diverse scenery images. Most current image-to-image translation approaches are devised as two mappings: a translation from the source to target domain and another to represent its inverse. While successful in many applications, these approaches may suffer from generating trivial solutions with limited diversity. That is because these methods learn more frequent associations rather than the scene structures. To mitigate the problem, we propose SCONE-GAN that utilises graph convolutional networks to learn the objects dependencies, maintain the image structure and preserve its semantics while transferring images into the target domain. For more realistic and diverse image generation we introduce style reference image. We enforce the model to maximize the mutual information between the style image and output. The proposed method explicitly maximizes the mutual information between the related patches, thus encouraging the generator to produce more diverse images. We validate the proposed algorithm for image-to-image translation and stylizing outdoor images. Both qualitative and quantitative results demonstrate the effectiveness of our approach on four dataset.
Progressive Feature Adjustment for Semi-supervised Learning from Pretrained Models
Sep 09, 2023



As an effective way to alleviate the burden of data annotation, semi-supervised learning (SSL) provides an attractive solution due to its ability to leverage both labeled and unlabeled data to build a predictive model. While significant progress has been made recently, SSL algorithms are often evaluated and developed under the assumption that the network is randomly initialized. This is in sharp contrast to most vision recognition systems that are built from fine-tuning a pretrained network for better performance. While the marriage of SSL and a pretrained model seems to be straightforward, recent literature suggests that naively applying state-of-the-art SSL with a pretrained model fails to unleash the full potential of training data. In this paper, we postulate the underlying reason is that the pretrained feature representation could bring a bias inherited from the source data, and the bias tends to be magnified through the self-training process in a typical SSL algorithm. To overcome this issue, we propose to use pseudo-labels from the unlabelled data to update the feature extractor that is less sensitive to incorrect labels and only allow the classifier to be trained from the labeled data. More specifically, we progressively adjust the feature extractor to ensure its induced feature distribution maintains a good class separability even under strong input perturbation. Through extensive experimental studies, we show that the proposed approach achieves superior performance over existing solutions.
RanPAC: Random Projections and Pre-trained Models for Continual Learning
Jul 05, 2023



Continual learning (CL) aims to incrementally learn different tasks (such as classification) in a non-stationary data stream without forgetting old ones. Most CL works focus on tackling catastrophic forgetting under a learning-from-scratch paradigm. However, with the increasing prominence of foundation models, pre-trained models equipped with informative representations have become available for various downstream requirements. Several CL methods based on pre-trained models have been explored, either utilizing pre-extracted features directly (which makes bridging distribution gaps challenging) or incorporating adaptors (which may be subject to forgetting). In this paper, we propose a concise and effective approach for CL with pre-trained models. Given that forgetting occurs during parameter updating, we contemplate an alternative approach that exploits training-free random projectors and class-prototype accumulation, which thus bypasses the issue. Specifically, we inject a frozen Random Projection layer with nonlinear activation between the pre-trained model's feature representations and output head, which captures interactions between features with expanded dimensionality, providing enhanced linear separability for class-prototype-based CL. We also demonstrate the importance of decorrelating the class-prototypes to reduce the distribution disparity when using pre-trained representations. These techniques prove to be effective and circumvent the problem of forgetting for both class- and domain-incremental continual learning. Compared to previous methods applied to pre-trained ViT-B/16 models, we reduce final error rates by between 10\% and 62\% on seven class-incremental benchmark datasets, despite not using any rehearsal memory. We conclude that the full potential of pre-trained models for simple, effective, and fast continual learning has not hitherto been fully tapped.
Selective Mixup Helps with Distribution Shifts, But Not (Only) because of Mixup
Jun 02, 2023Mixup is a highly successful technique to improve generalization of neural networks by augmenting the training data with combinations of random pairs. Selective mixup is a family of methods that apply mixup to specific pairs, e.g. only combining examples across classes or domains. These methods have claimed remarkable improvements on benchmarks with distribution shifts, but their mechanisms and limitations remain poorly understood. We examine an overlooked aspect of selective mixup that explains its success in a completely new light. We find that the non-random selection of pairs affects the training distribution and improve generalization by means completely unrelated to the mixing. For example in binary classification, mixup across classes implicitly resamples the data for a uniform class distribution - a classical solution to label shift. We show empirically that this implicit resampling explains much of the improvements in prior work. Theoretically, these results rely on a regression toward the mean, an accidental property that we identify in several datasets. We have found a new equivalence between two successful methods: selective mixup and resampling. We identify limits of the former, confirm the effectiveness of the latter, and find better combinations of their respective benefits.
Semantic Role Labeling Guided Out-of-distribution Detection
May 29, 2023



Identifying unexpected domain-shifted instances in natural language processing is crucial in real-world applications. Previous works identify the OOD instance by leveraging a single global feature embedding to represent the sentence, which cannot characterize subtle OOD patterns well. Another major challenge current OOD methods face is learning effective low-dimensional sentence representations to identify the hard OOD instances that are semantically similar to the ID data. In this paper, we propose a new unsupervised OOD detection method, namely Semantic Role Labeling Guided Out-of-distribution Detection (SRLOOD), that separates, extracts, and learns the semantic role labeling (SRL) guided fine-grained local feature representations from different arguments of a sentence and the global feature representations of the full sentence using a margin-based contrastive loss. A novel self-supervised approach is also introduced to enhance such global-local feature learning by predicting the SRL extracted role. The resulting model achieves SOTA performance on four OOD benchmarks, indicating the effectiveness of our approach. Codes will be available upon acceptance.
ProtoCon: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning
Mar 22, 2023



Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually underperform. ProtoCon refines the pseudo-labels by leveraging their nearest neighbours' information. The neighbours are identified as the training proceeds using an online clustering approach operating in an embedding space trained via a prototypical loss to encourage well-formed clusters. The online nature of ProtoCon allows it to utilise the label history of the entire dataset in one training cycle to refine labels in the following cycle without the need to store image embeddings. Hence, it can seamlessly scale to larger datasets at a low cost. Finally, ProtoCon addresses the poor training signal in the initial phase of training (due to fewer confident predictions) by introducing an auxiliary self-supervised loss. It delivers significant gains and faster convergence over state-of-the-art across 5 datasets, including CIFARs, ImageNet and DomainNet.
Bayesian Learning with Information Gain Provably Bounds Risk for a Robust Adversarial Defense
Dec 05, 2022We present a new algorithm to learn a deep neural network model robust against adversarial attacks. Previous algorithms demonstrate an adversarially trained Bayesian Neural Network (BNN) provides improved robustness. We recognize the adversarial learning approach for approximating the multi-modal posterior distribution of a Bayesian model can lead to mode collapse; consequently, the model's achievements in robustness and performance are sub-optimal. Instead, we first propose preventing mode collapse to better approximate the multi-modal posterior distribution. Second, based on the intuition that a robust model should ignore perturbations and only consider the informative content of the input, we conceptualize and formulate an information gain objective to measure and force the information learned from both benign and adversarial training instances to be similar. Importantly. we prove and demonstrate that minimizing the information gain objective allows the adversarial risk to approach the conventional empirical risk. We believe our efforts provide a step toward a basis for a principled method of adversarially training BNNs. Our model demonstrate significantly improved robustness--up to 20%--compared with adversarial training and Adv-BNN under PGD attacks with 0.035 distortion on both CIFAR-10 and STL-10 datasets.
* Published at ICML 2022
LAVA: Label-efficient Visual Learning and Adaptation
Oct 19, 2022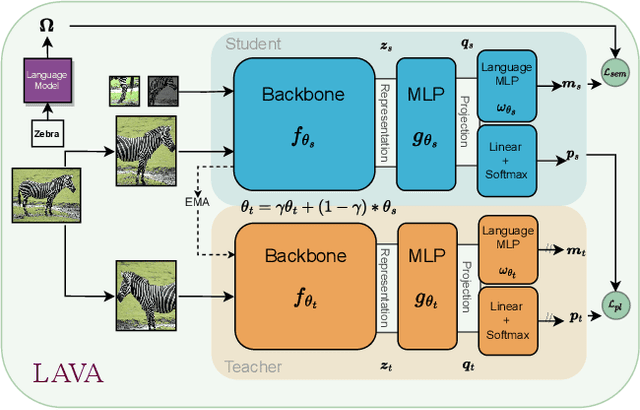


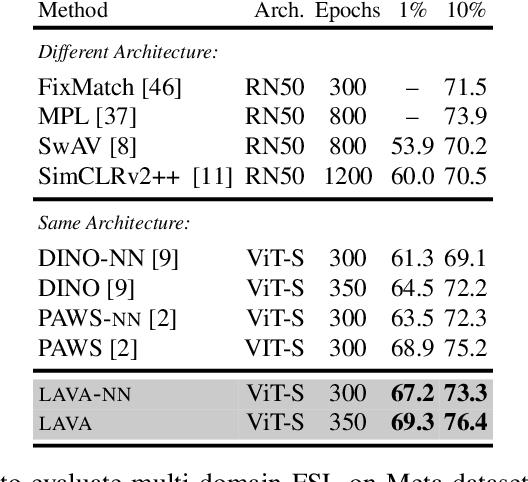
We present LAVA, a simple yet effective method for multi-domain visual transfer learning with limited data. LAVA builds on a few recent innovations to enable adapting to partially labelled datasets with class and domain shifts. First, LAVA learns self-supervised visual representations on the source dataset and ground them using class label semantics to overcome transfer collapse problems associated with supervised pretraining. Secondly, LAVA maximises the gains from unlabelled target data via a novel method which uses multi-crop augmentations to obtain highly robust pseudo-labels. By combining these ingredients, LAVA achieves a new state-of-the-art on ImageNet semi-supervised protocol, as well as on 7 out of 10 datasets in multi-domain few-shot learning on the Meta-dataset. Code and models are made available.
ID and OOD Performance Are Sometimes Inversely Correlated on Real-world Datasets
Sep 01, 2022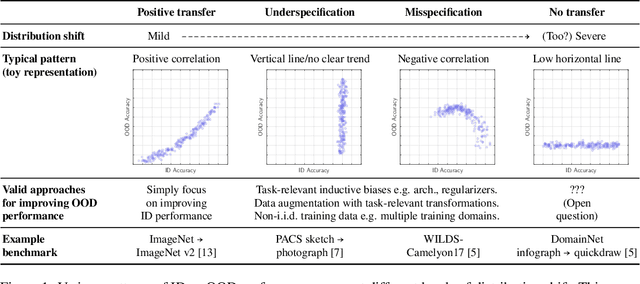
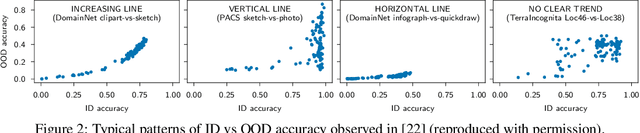
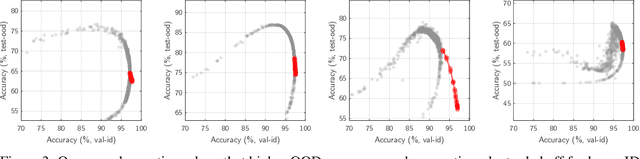
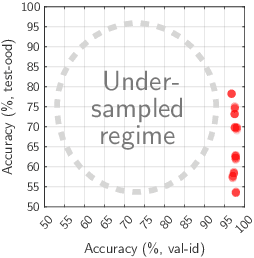
Several studies have empirically compared in-distribution (ID) and out-of-distribution (OOD) performance of various models. They report frequent positive correlations on benchmarks in computer vision and NLP. Surprisingly, they never observe inverse correlations suggesting necessary trade-offs. This matters to determine whether ID performance can serve as a proxy for OOD generalization. This short paper shows that inverse correlations between ID and OOD performance do happen in real-world benchmarks. They may have been missed in past studies because of a biased selection of models. We show an example of the pattern on the WILDS-Camelyon17 dataset, using models from multiple training epochs and random seeds. Our observations are particularly striking on models trained with a regularizer that diversifies the solutions to the ERM objective. We nuance recommendations and conclusions made in past studies. (1) High OOD performance does sometimes require trading off ID performance. (2) Focusing on ID performance alone may not lead to optimal OOD performance: it can lead to diminishing and eventually negative returns in OOD performance. (3) Our example reminds that empirical studies only chart regimes achievable with existing methods: care is warranted in deriving prescriptive recommendations.
Predicting is not Understanding: Recognizing and Addressing Underspecification in Machine Learning
Jul 06, 2022
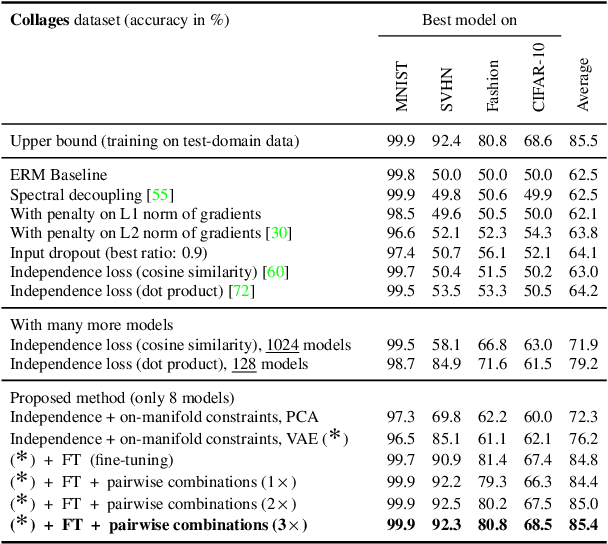
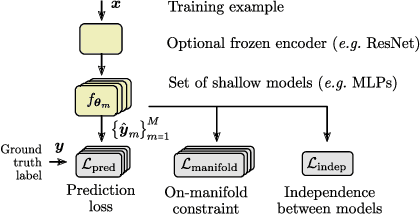

Machine learning (ML) models are typically optimized for their accuracy on a given dataset. However, this predictive criterion rarely captures all desirable properties of a model, in particular how well it matches a domain expert's understanding of a task. Underspecification refers to the existence of multiple models that are indistinguishable in their in-domain accuracy, even though they differ in other desirable properties such as out-of-distribution (OOD) performance. Identifying these situations is critical for assessing the reliability of ML models. We formalize the concept of underspecification and propose a method to identify and partially address it. We train multiple models with an independence constraint that forces them to implement different functions. They discover predictive features that are otherwise ignored by standard empirical risk minimization (ERM), which we then distill into a global model with superior OOD performance. Importantly, we constrain the models to align with the data manifold to ensure that they discover meaningful features. We demonstrate the method on multiple datasets in computer vision (collages, WILDS-Camelyon17, GQA) and discuss general implications of underspecification. Most notably, in-domain performance cannot serve for OOD model selection without additional assumptions.