 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified View of SDP-based Neural Network Verification through Completely Positive Programming
Mar 06, 2022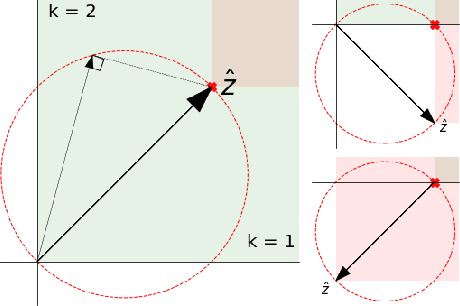
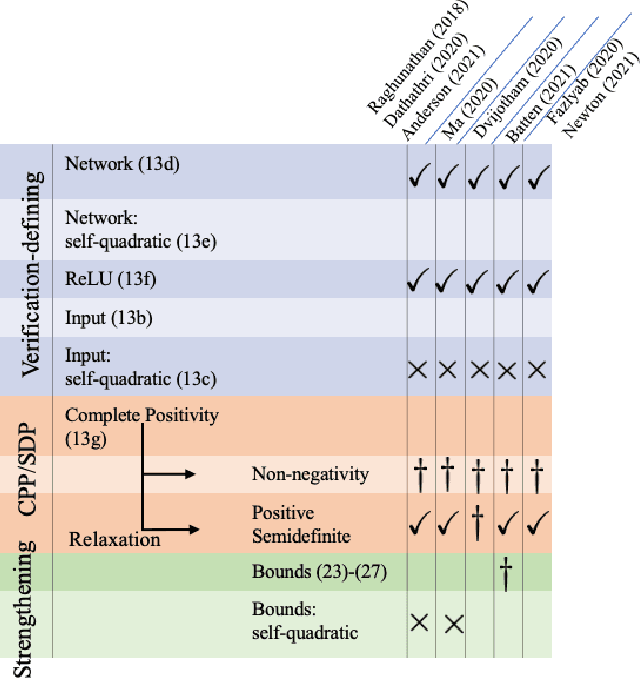
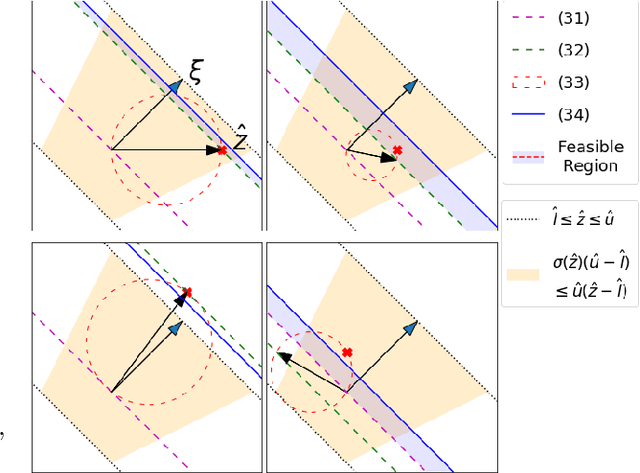
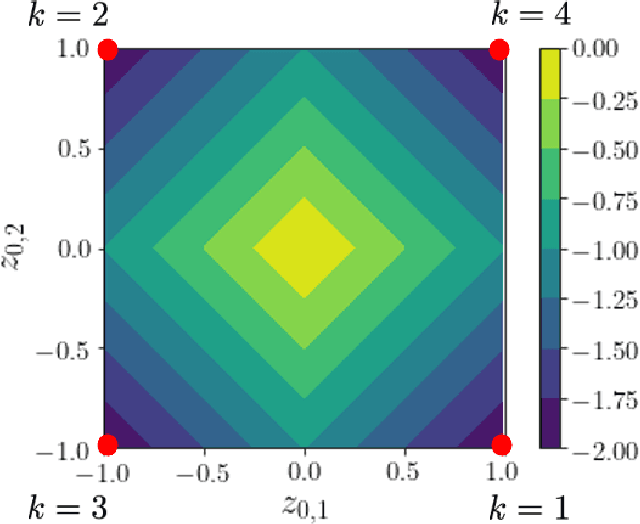
Verifying that input-output relationships of a neural network conform to prescribed operational specifications is a key enabler towards deploying these networks in safety-critical applications. Semidefinite programming (SDP)-based approaches to Rectified Linear Unit (ReLU) network verification transcribe this problem into an optimization problem, where the accuracy of any such formulation reflects the level of fidelity in how the neural network computation is represented, as well as the relaxations of intractable constraints. While the literature contains much progress on improving the tightness of SDP formulations while maintaining tractability, comparatively little work has been devoted to the other extreme, i.e., how to most accurately capture the original verification problem before SDP relaxation. In this work, we develop an exact, convex formulation of verification as a completely positive program (CPP), and provide analysis showing that our formulation is minimal -- the removal of any constraint fundamentally misrepresents the neural network computation. We leverage our formulation to provide a unifying view of existing approaches, and give insight into the source of large relaxation gaps observed in some cases.
On the Problem of Reformulating Systems with Uncertain Dynamics as a Stochastic Differential Equation
Nov 11, 2021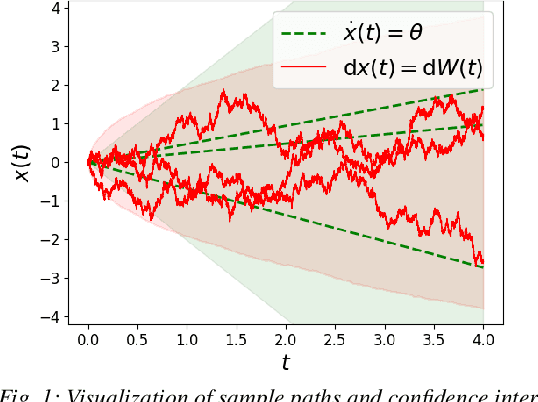
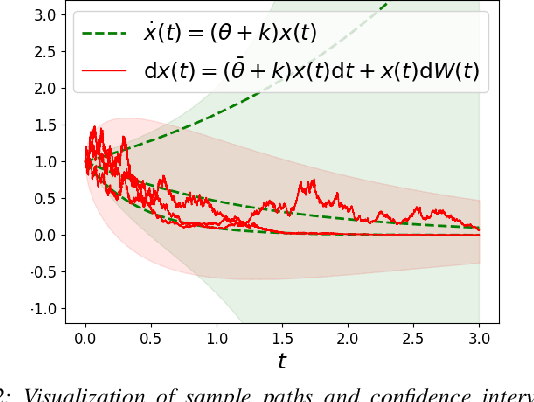
We identify an issue in recent approaches to learning-based control that reformulate systems with uncertain dynamics using a stochastic differential equation. Specifically, we discuss the approximation that replaces a model with fixed but uncertain parameters (a source of epistemic uncertainty) with a model subject to external disturbances modeled as a Brownian motion (corresponding to aleatoric uncertainty).
Sample-Efficient Safety Assurances using Conformal Prediction
Sep 28, 2021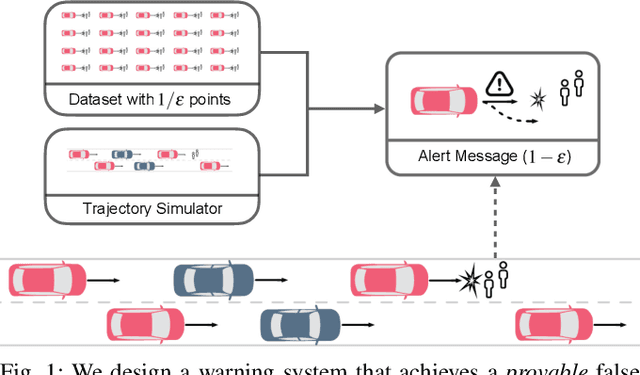
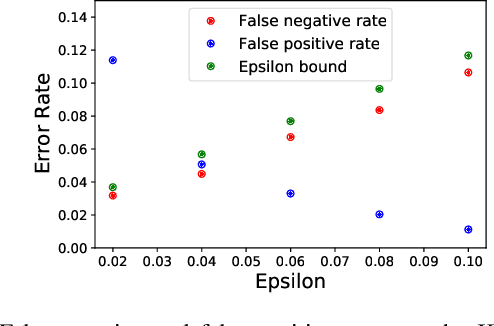
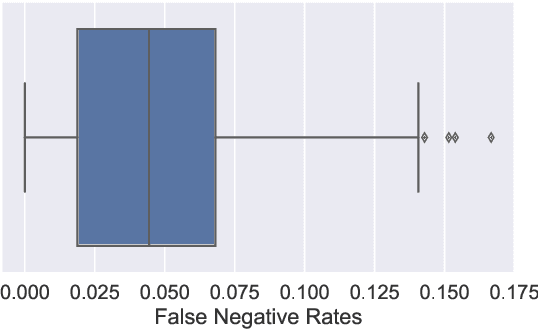
When deploying machine learning models in high-stakes robotics applications, the ability to detect unsafe situations is crucial. Early warning systems can provide alerts when an unsafe situation is imminent (in the absence of corrective action). To reliably improve safety, these warning systems should have a provable false negative rate; i.e. of the situations that are unsafe, fewer than $\epsilon$ will occur without an alert. In this work, we present a framework that combines a statistical inference technique known as conformal prediction with a simulator of robot/environment dynamics, in order to tune warning systems to provably achieve an $\epsilon$ false negative rate using as few as $1/\epsilon$ data points. We apply our framework to a driver warning system and a robotic grasping application, and empirically demonstrate guaranteed false negative rate and low false detection (positive) rate using very little data.
Towards the Unification and Data-Driven Synthesis of Autonomous Vehicle Safety Concepts
Jul 30, 2021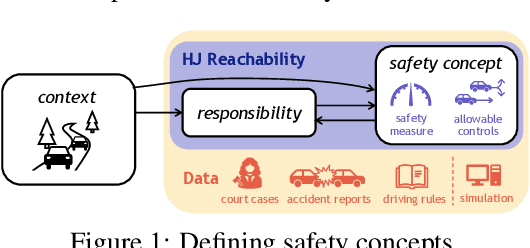
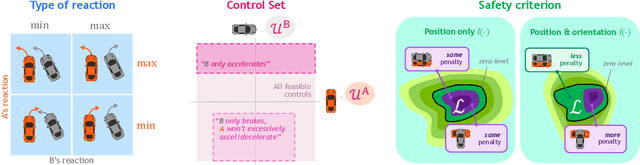
As safety-critical autonomous vehicles (AVs) will soon become pervasive in our society, a number of safety concepts for trusted AV deployment have been recently proposed throughout industry and academia. Yet, agreeing upon an "appropriate" safety concept is still an elusive task. In this paper, we advocate for the use of Hamilton Jacobi (HJ) reachability as a unifying mathematical framework for comparing existing safety concepts, and propose ways to expand its modeling premises in a data-driven fashion. Specifically, we show that (i) existing predominant safety concepts can be embedded in the HJ reachability framework, thereby enabling a common language for comparing and contrasting modeling assumptions, and (ii) HJ reachability can serve as an inductive bias to effectively reason, in a data-driven context, about two critical, yet often overlooked aspects of safety: responsibility and context-dependency.
On Infusing Reachability-Based Safety Assurance within Planning Frameworks for Human-Robot Vehicle Interactions
Dec 06, 2020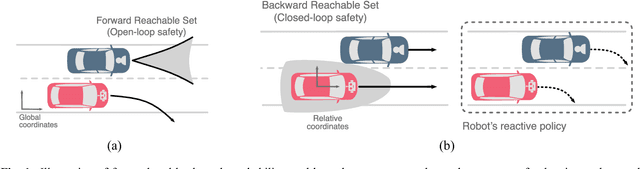

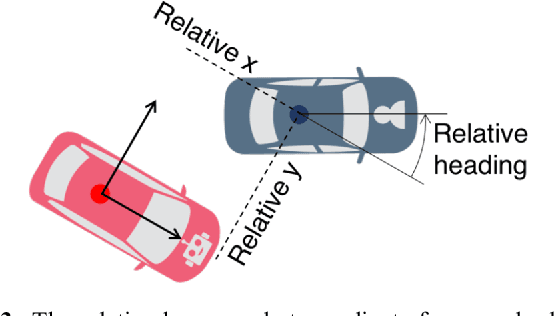
Action anticipation, intent prediction, and proactive behavior are all desirable characteristics for autonomous driving policies in interactive scenarios. Paramount, however, is ensuring safety on the road -- a key challenge in doing so is accounting for uncertainty in human driver actions without unduly impacting planner performance. This paper introduces a minimally-interventional safety controller operating within an autonomous vehicle control stack with the role of ensuring collision-free interaction with an externally controlled (e.g., human-driven) counterpart while respecting static obstacles such as a road boundary wall. We leverage reachability analysis to construct a real-time (100Hz) controller that serves the dual role of (i) tracking an input trajectory from a higher-level planning algorithm using model predictive control, and (ii) assuring safety by maintaining the availability of a collision-free escape maneuver as a persistent constraint regardless of whatever future actions the other car takes. A full-scale steer-by-wire platform is used to conduct traffic weaving experiments wherein two cars, initially side-by-side, must swap lanes in a limited amount of time and distance, emulating cars merging onto/off of a highway. We demonstrate that, with our control stack, the autonomous vehicle is able to avoid collision even when the other car defies the planner's expectations and takes dangerous actions, either carelessly or with the intent to collide, and otherwise deviates minimally from the planned trajectory to the extent required to maintain safety.
* arXiv admin note: text overlap with arXiv:1812.11315
Multimodal Deep Generative Models for Trajectory Prediction: A Conditional Variational Autoencoder Approach
Aug 10, 2020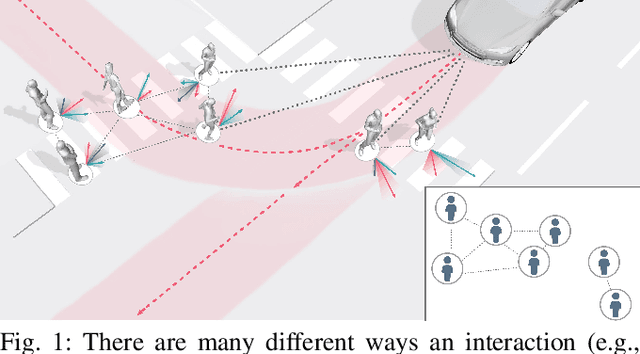
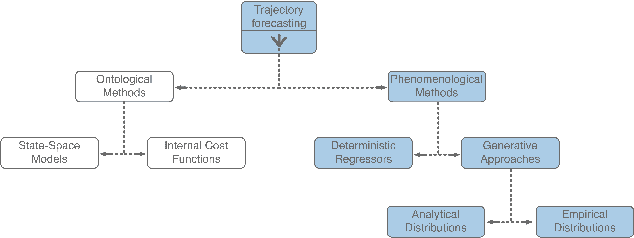

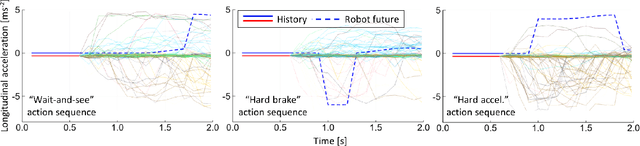
Human behavior prediction models enable robots to anticipate how humans may react to their actions, and hence are instrumental to devising safe and proactive robot planning algorithms. However, modeling complex interaction dynamics and capturing the possibility of many possible outcomes in such interactive settings is very challenging, which has recently prompted the study of several different approaches. In this work, we provide a self-contained tutorial on a conditional variational autoencoder (CVAE) approach to human behavior prediction which, at its core, can produce a multimodal probability distribution over future human trajectories conditioned on past interactions and candidate robot future actions. Specifically, the goals of this tutorial paper are to review and build a taxonomy of state-of-the-art methods in human behavior prediction, from physics-based to purely data-driven methods, provide a rigorous yet easily accessible description of a data-driven, CVAE-based approach, highlight important design characteristics that make this an attractive model to use in the context of model-based planning for human-robot interactions, and provide important design considerations when using this class of models.
Learned Critical Probabilistic Roadmaps for Robotic Motion Planning
Oct 08, 2019
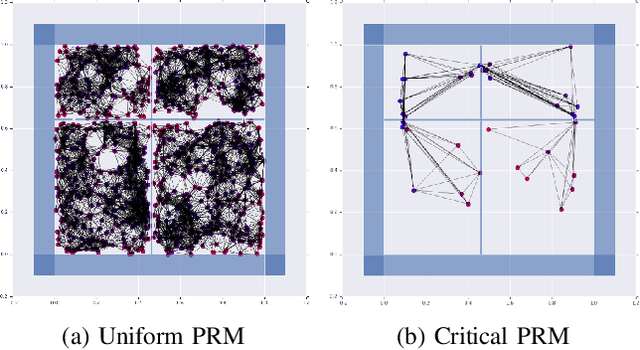
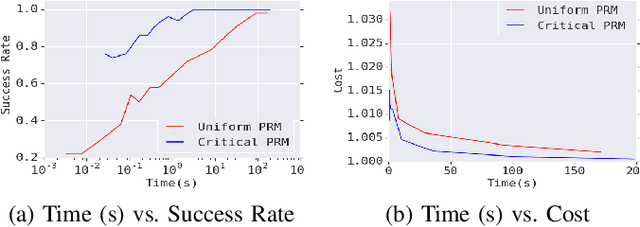
Sampling-based motion planning techniques have emerged as an efficient algorithmic paradigm for solving complex motion planning problems. These approaches use a set of probing samples to construct an implicit graph representation of the robot's state space, allowing arbitrarily accurate representations as the number of samples increases to infinity. In practice, however, solution trajectories only rely on a few critical states, often defined by structure in the state space (e.g., doorways). In this work we propose a general method to identify these critical states via graph-theoretic techniques (betweenness centrality) and learn to predict criticality from only local environment features. These states are then leveraged more heavily via global connections within a hierarchical graph, termed Critical Probabilistic Roadmaps. Critical PRMs are demonstrated to achieve up to three orders of magnitude improvement over uniform sampling, while preserving the guarantees and complexity of sampling-based motion planning. A video is available at https://youtu.be/AYoD-pGd9ms.
Revisiting the Asymptotic Optimality of RRT*
Sep 20, 2019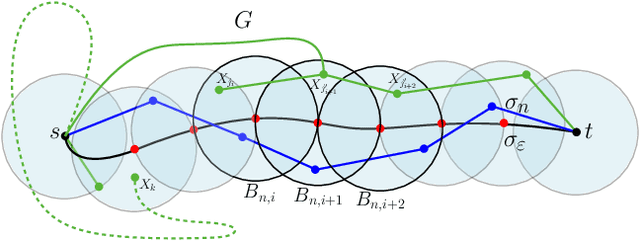
RRT* is one of the most widely used sampling-based algorithms for asymptotically-optimal motion planning. This algorithm laid the foundations for optimality in motion planning as a whole, and inspired the development of numerous new algorithms in the field, many of which build upon RRT* itself. In this paper, we first identify a logical gap in the optimality proof of RRT*, which was developed in Karaman and Frazzoli (2011). Then, we present an alternative and mathematically-rigorous proof for asymptotic optimality. Our proof suggests that the connection radius used by RRT* should be increased from $\gamma \left(\frac{\log n}{n}\right)^{1/d}$ to $\gamma' \left(\frac{\log n}{n}\right)^{1/(d+1)}$ in order to account for the additional dimension of time that dictates the samples' ordering. Here $\gamma$, $\gamma'$, are constants, and $n$, $d$, are the number of samples and the dimension of the problem, respectively.
On Infusing Reachability-Based Safety Assurance within Probabilistic Planning Frameworks for Human-Robot Vehicle Interactions
Dec 29, 2018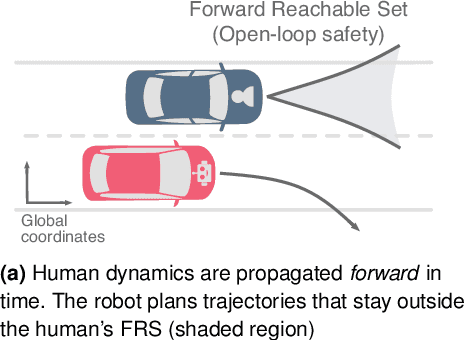

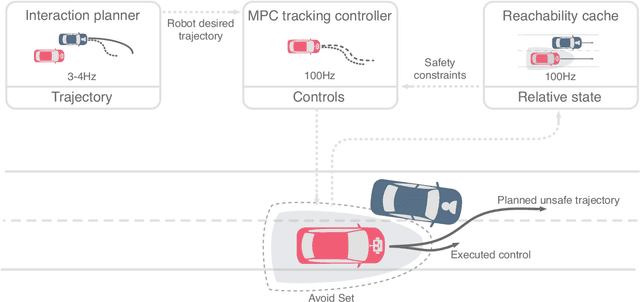
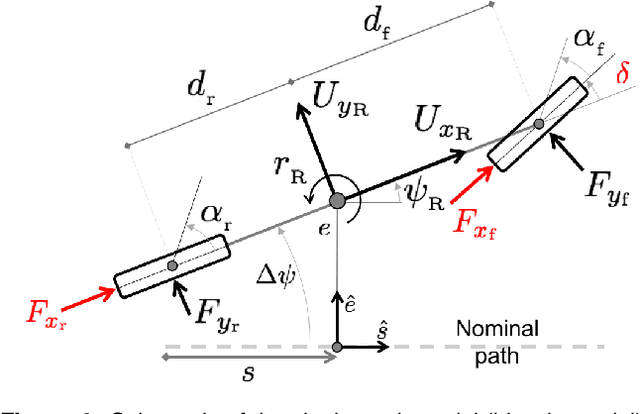
Action anticipation, intent prediction, and proactive behavior are all desirable characteristics for autonomous driving policies in interactive scenarios. Paramount, however, is ensuring safety on the road --- a key challenge in doing so is accounting for uncertainty in human driver actions without unduly impacting planner performance. This paper introduces a minimally-interventional safety controller operating within an autonomous vehicle control stack with the role of ensuring collision-free interaction with an externally controlled (e.g., human-driven) counterpart. We leverage reachability analysis to construct a real-time (100Hz) controller that serves the dual role of (1) tracking an input trajectory from a higher-level planning algorithm using model predictive control, and (2) assuring safety through maintaining the availability of a collision-free escape maneuver as a persistent constraint regardless of whatever future actions the other car takes. A full-scale steer-by-wire platform is used to conduct traffic weaving experiments wherein the two cars, initially side-by-side, must swap lanes in a limited amount of time and distance, emulating cars merging onto/off of a highway. We demonstrate that, with our control stack, the autonomous vehicle is able to avoid collision even when the other car defies the planner's expectations and takes dangerous actions, either carelessly or with the intent to collide, and otherwise deviates minimally from the planned trajectory to the extent required to maintain safety.
Generative Modeling of Multimodal Multi-Human Behavior
Jul 26, 2018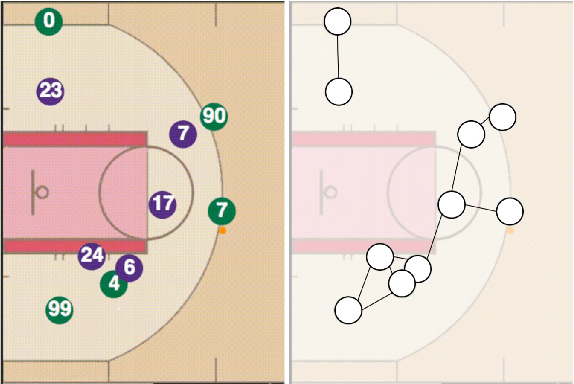
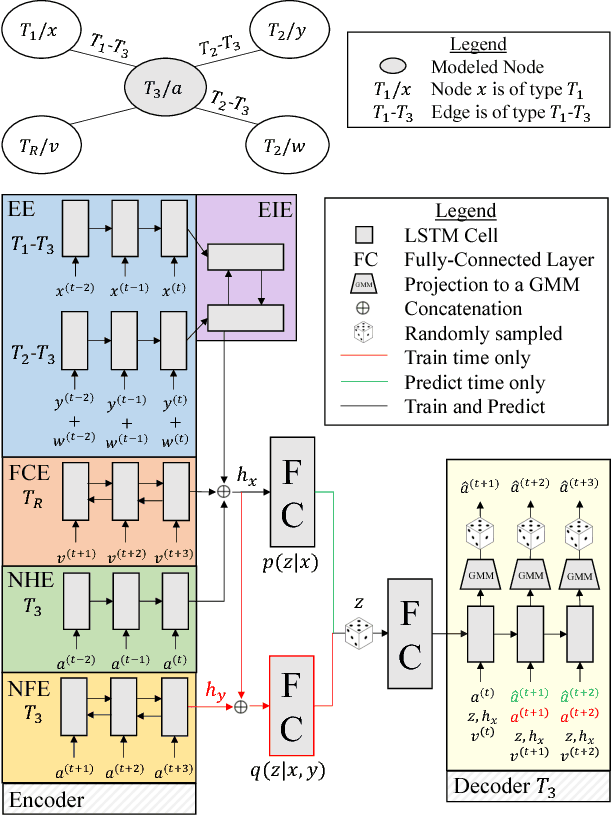
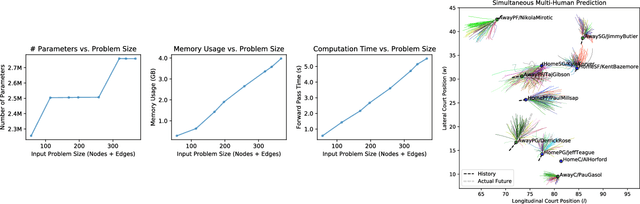
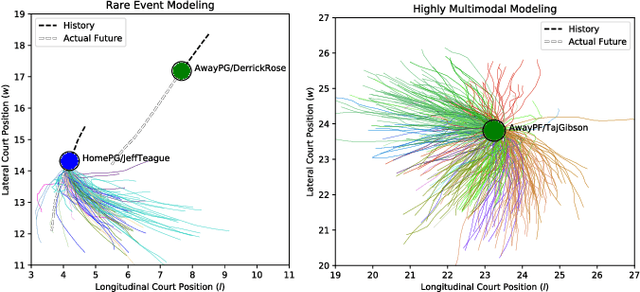
This work presents a methodology for modeling and predicting human behavior in settings with N humans interacting in highly multimodal scenarios (i.e. where there are many possible highly-distinct futures). A motivating example includes robots interacting with humans in crowded environments, such as self-driving cars operating alongside human-driven vehicles or human-robot collaborative bin packing in a warehouse. Our approach to model human behavior in such uncertain environments is to model humans in the scene as nodes in a graphical model, with edges encoding relationships between them. For each human, we learn a multimodal probability distribution over future actions from a dataset of multi-human interactions. Learning such distributions is made possible by recent advances in the theory of conditional variational autoencoders and deep learning approximations of probabilistic graphical models. Specifically, we learn action distributions conditioned on interaction history, neighboring human behavior, and candidate future agent behavior in order to take into account response dynamics. We demonstrate the performance of such a modeling approach in modeling basketball player trajectories, a highly multimodal, multi-human scenario which serves as a proxy for many robotic applications.