 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation with Adequacy-Oriented Learning
Nov 21, 2018
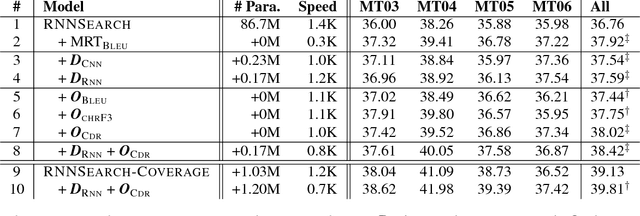
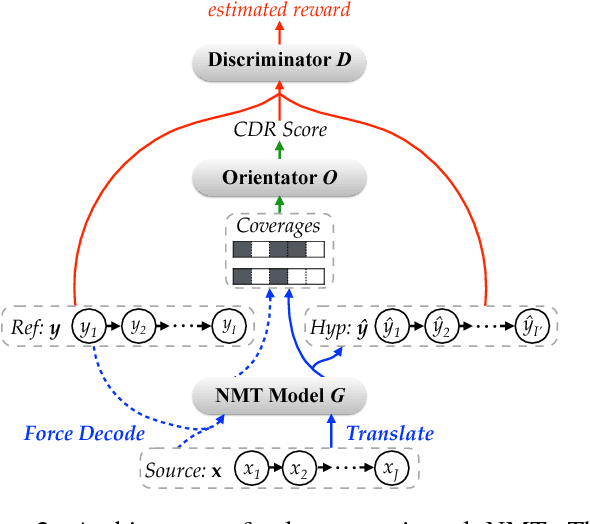

Although Neural Machine Translation (NMT) models have advanced state-of-the-art performance in machine translation, they face problems like the inadequate translation. We attribute this to that the standard Maximum Likelihood Estimation (MLE) cannot judge the real translation quality due to its several limitations. In this work, we propose an adequacy-oriented learning mechanism for NMT by casting translation as a stochastic policy in Reinforcement Learning (RL), where the reward is estimated by explicitly measuring translation adequacy. Benefiting from the sequence-level training of RL strategy and a more accurate reward designed specifically for translation, our model outperforms multiple strong baselines, including (1) standard and coverage-augmented attention models with MLE-based training, and (2) advanced reinforcement and adversarial training strategies with rewards based on both word-level BLEU and character-level chrF3. Quantitative and qualitative analyses on different language pairs and NMT architectures demonstrate the effectiveness and universality of the proposed approach.
Near or Far, Wide Range Zero-Shot Cross-Lingual Dependency Parsing
Nov 01, 2018
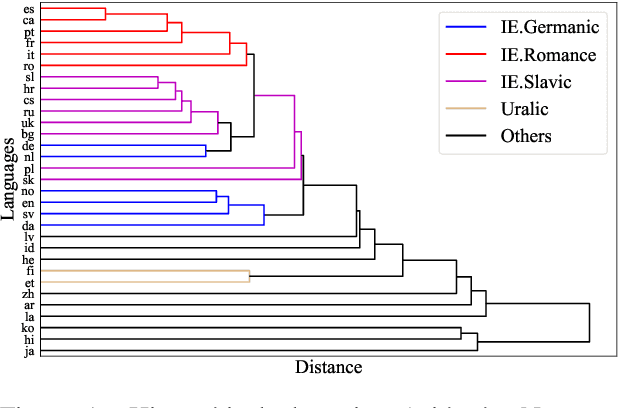
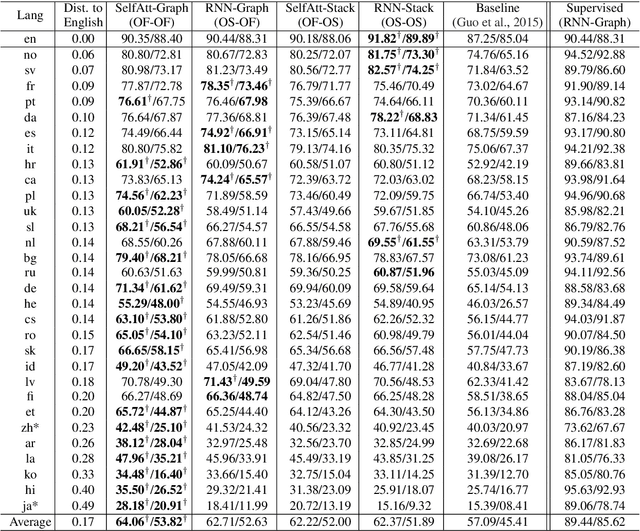
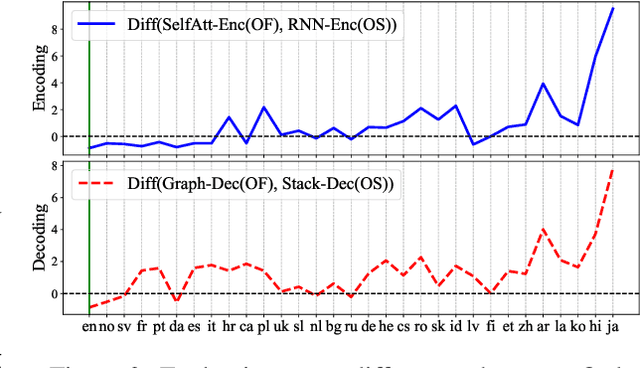
Cross-lingual transfer is the major means toleverage knowledge from high-resource lan-guages to help low-resource languages. In this paper, we investigate cross-lingual trans-fer across a broad spectrum of language dis-tances. We posit that Recurrent Neural Net-works (RNNs)-based encoders, since explic-itly incorporating surface word order, are brit-tle for transferring across distant languages,while self-attentive models are more flexibleon modeling word order information; thusthey would be more robust in the cross-lingualtransfer setting. We test our hypothesis bytraining dependency parsers on only Englishcorpus and evaluating them on 31 other lan-guages. With detailed analysis, we find inter-esting patterns showing that RNNs-based ar-chitectures can transfer well for languages thatare close to English, while self-attentive mod-els are have better cross-lingual transferabilityacross a wide range of languages.
The Profiling Machine: Active Generalization over Knowledge
Oct 01, 2018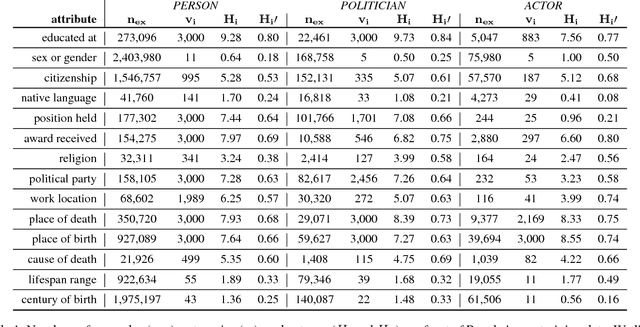
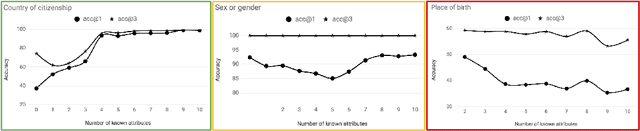
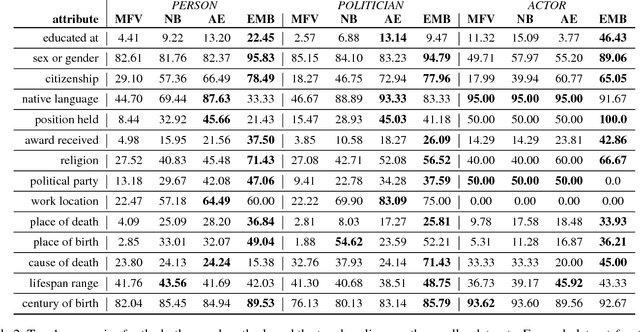
The human mind is a powerful multifunctional knowledge storage and management system that performs generalization, type inference, anomaly detection, stereotyping, and other tasks. A dynamic KR system that appropriately profiles over sparse inputs to provide complete expectations for unknown facets can help with all these tasks. In this paper, we introduce the task of profiling, inspired by theories and findings in social psychology about the potential of profiles for reasoning and information processing. We describe two generic state-of-the-art neural architectures that can be easily instantiated as profiling machines to generate expectations and applied to any kind of knowledge to fill gaps. We evaluate these methods against Wikidata and crowd expectations, and compare the results to gain insight in the nature of knowledge captured by various profiling methods. We make all code and data available to facilitate future research.
Fast and Simple Mixture of Softmaxes with BPE and Hybrid-LightRNN for Language Generation
Sep 25, 2018
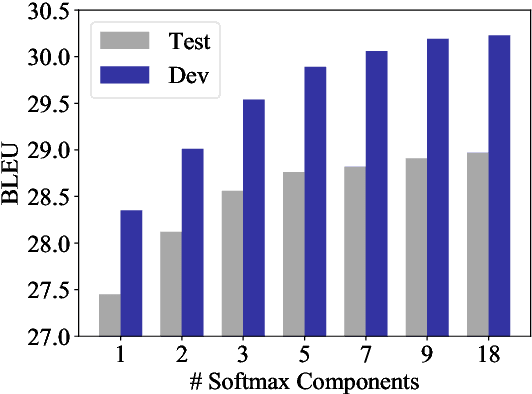
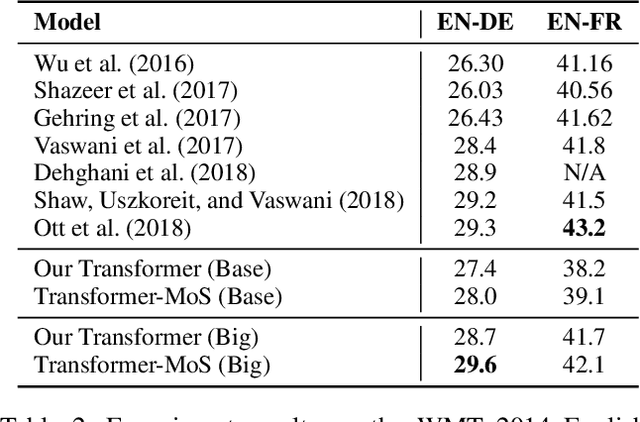
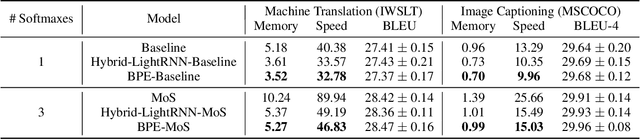
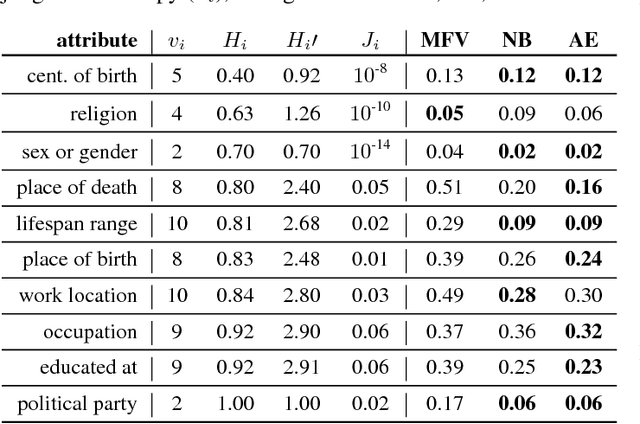
Mixture of Softmaxes (MoS) has been shown to be effective at addressing the expressiveness limitation of Softmax-based models. Despite the known advantage, MoS is practically sealed by its large consumption of memory and computational time due to the need of computing multiple Softmaxes. In this work, we set out to unleash the power of MoS in practical applications by investigating improved word coding schemes, which could effectively reduce the vocabulary size and hence relieve the memory and computation burden. We show both BPE and our proposed Hybrid-LightRNN lead to improved encoding mechanisms that can halve the time and memory consumption of MoS without performance losses. With MoS, we achieve an improvement of 1.5 BLEU scores on IWSLT 2014 German-to-English corpus and an improvement of 0.76 CIDEr score on image captioning. Moreover, on the larger WMT 2014 machine translation dataset, our MoS-boosted Transformer yields 29.5 BLEU score for English-to-German and 42.1 BLEU score for English-to-French, outperforming the single-Softmax Transformer by 0.8 and 0.4 BLEU scores respectively and achieving the state-of-the-art result on WMT 2014 English-to-German task.
Automatic Event Salience Identification
Sep 03, 2018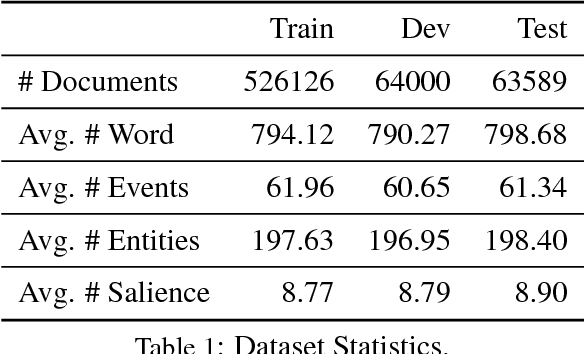

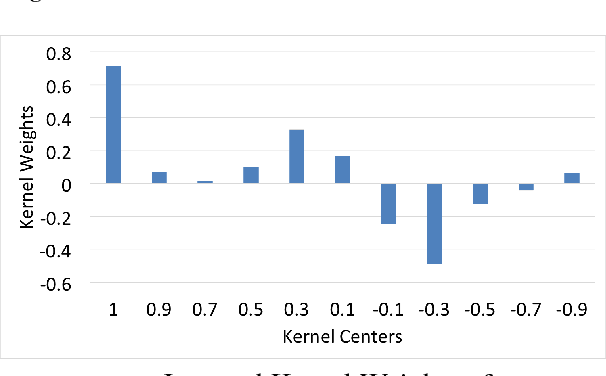
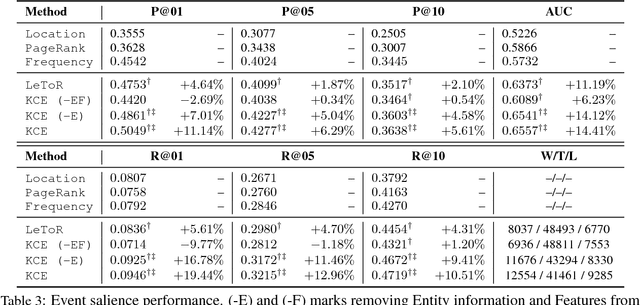
Identifying the salience (i.e. importance) of discourse units is an important task in language understanding. While events play important roles in text documents, little research exists on analyzing their saliency status. This paper empirically studies the Event Salience task and proposes two salience detection models based on content similarities and discourse relations. The first is a feature based salience model that incorporates similarities among discourse units. The second is a neural model that captures more complex relations between discourse units. Tested on our new large-scale event salience corpus, both methods significantly outperform the strong frequency baseline, while our neural model further improves the feature based one by a large margin. Our analyses demonstrate that our neural model captures interesting connections between salience and discourse unit relations (e.g., scripts and frame structures).
Large-scale Cloze Test Dataset Created by Teachers
Aug 28, 2018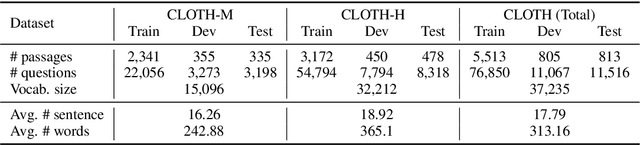

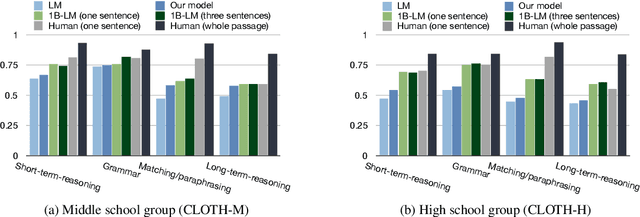
Cloze tests are widely adopted in language exams to evaluate students' language proficiency. In this paper, we propose the first large-scale human-created cloze test dataset CLOTH, containing questions used in middle-school and high-school language exams. With missing blanks carefully created by teachers and candidate choices purposely designed to be nuanced, CLOTH requires a deeper language understanding and a wider attention span than previously automatically-generated cloze datasets. We test the performance of dedicatedly designed baseline models including a language model trained on the One Billion Word Corpus and show humans outperform them by a significant margin. We investigate the source of the performance gap, trace model deficiencies to some distinct properties of CLOTH, and identify the limited ability of comprehending the long-term context to be the key bottleneck.
Graph-Based Decoding for Event Sequencing and Coreference Resolution
Jun 13, 2018

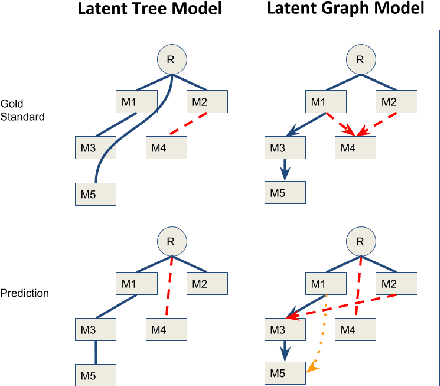
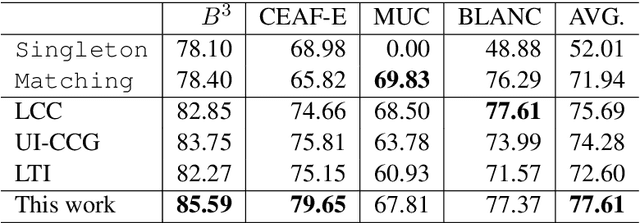
Events in text documents are interrelated in complex ways. In this paper, we study two types of relation: Event Coreference and Event Sequencing. We show that the popular tree-like decoding structure for automated Event Coreference is not suitable for Event Sequencing. To this end, we propose a graph-based decoding algorithm that is applicable to both tasks. The new decoding algorithm supports flexible feature sets for both tasks. Empirically, our event coreference system has achieved state-of-the-art performance on the TAC-KBP 2015 event coreference task and our event sequencing system beats a strong temporal-based, oracle-informed baseline. We discuss the challenges of studying these event relations.
AdvEntuRe: Adversarial Training for Textual Entailment with Knowledge-Guided Examples
May 12, 2018
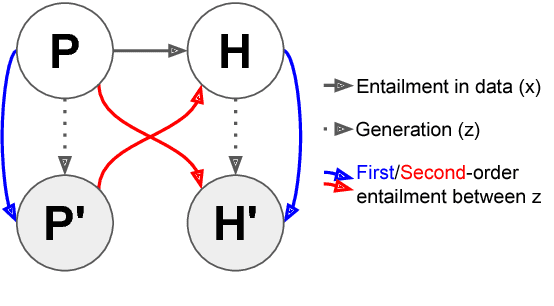
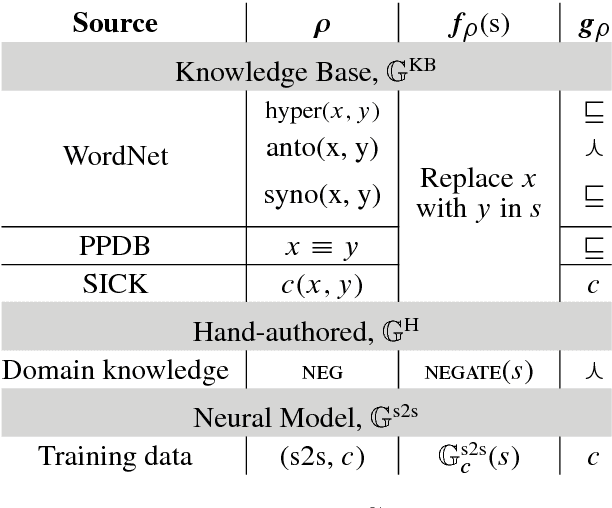
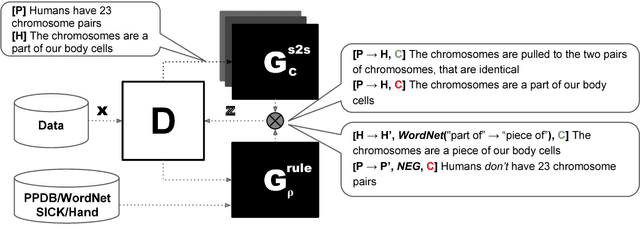
We consider the problem of learning textual entailment models with limited supervision (5K-10K training examples), and present two complementary approaches for it. First, we propose knowledge-guided adversarial example generators for incorporating large lexical resources in entailment models via only a handful of rule templates. Second, to make the entailment model - a discriminator - more robust, we propose the first GAN-style approach for training it using a natural language example generator that iteratively adjusts based on the discriminator's performance. We demonstrate effectiveness using two entailment datasets, where the proposed methods increase accuracy by 4.7% on SciTail and by 2.8% on a 1% training sub-sample of SNLI. Notably, even a single hand-written rule, negate, improves the accuracy on the negation examples in SNLI by 6.1%.
Stack-Pointer Networks for Dependency Parsing
May 03, 2018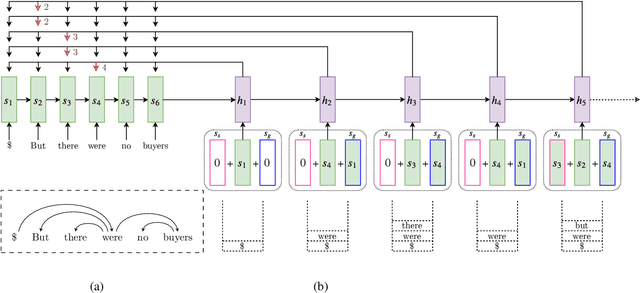
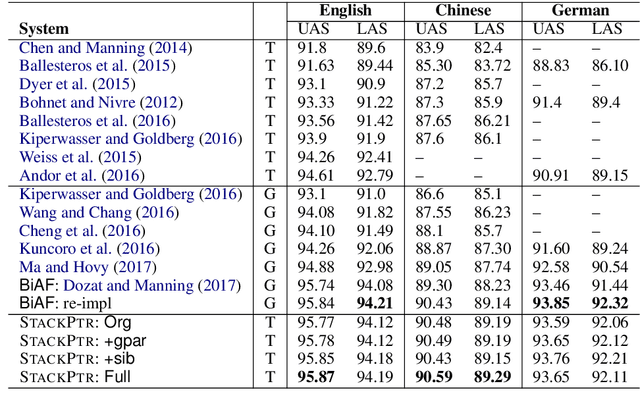
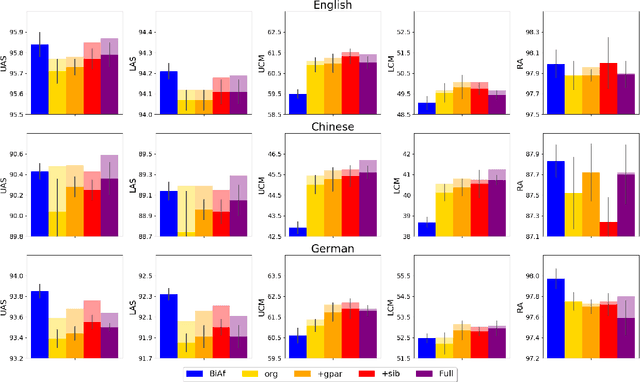

We introduce a novel architecture for dependency parsing: \emph{stack-pointer networks} (\textbf{\textsc{StackPtr}}). Combining pointer networks~\citep{vinyals2015pointer} with an internal stack, the proposed model first reads and encodes the whole sentence, then builds the dependency tree top-down (from root-to-leaf) in a depth-first fashion. The stack tracks the status of the depth-first search and the pointer networks select one child for the word at the top of the stack at each step. The \textsc{StackPtr} parser benefits from the information of the whole sentence and all previously derived subtree structures, and removes the left-to-right restriction in classical transition-based parsers. Yet, the number of steps for building any (including non-projective) parse tree is linear in the length of the sentence just as other transition-based parsers, yielding an efficient decoding algorithm with $O(n^2)$ time complexity. We evaluate our model on 29 treebanks spanning 20 languages and different dependency annotation schemas, and achieve state-of-the-art performance on 21 of them.
From Credit Assignment to Entropy Regularization: Two New Algorithms for Neural Sequence Prediction
Apr 29, 2018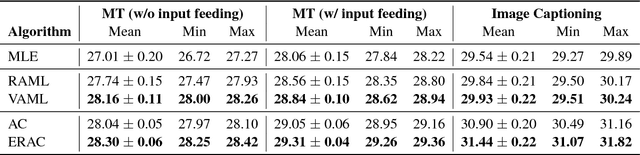
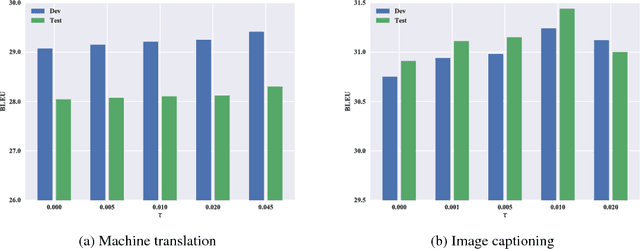
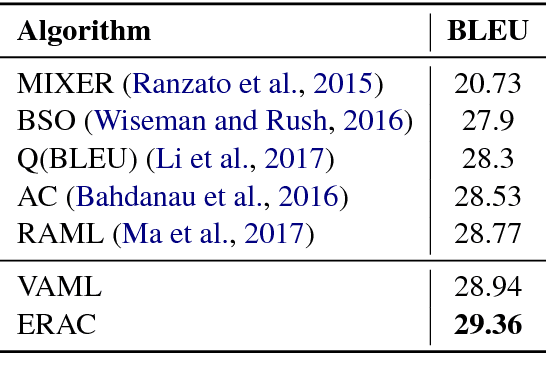

In this work, we study the credit assignment problem in reward augmented maximum likelihood (RAML) learning, and establish a theoretical equivalence between the token-level counterpart of RAML and the entropy regularized reinforcement learning. Inspired by the connection, we propose two sequence prediction algorithms, one extending RAML with fine-grained credit assignment and the other improving Actor-Critic with a systematic entropy regularization. On two benchmark datasets, we show the proposed algorithms outperform RAML and Actor-Critic respectively, providing new alternatives to sequence prediction.