 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Classifiers: Two-stage Classification for Robustness in Machine Learning
Jun 10, 2022
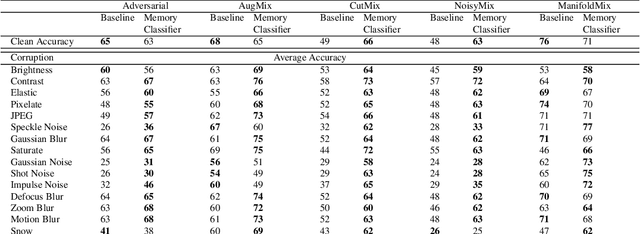
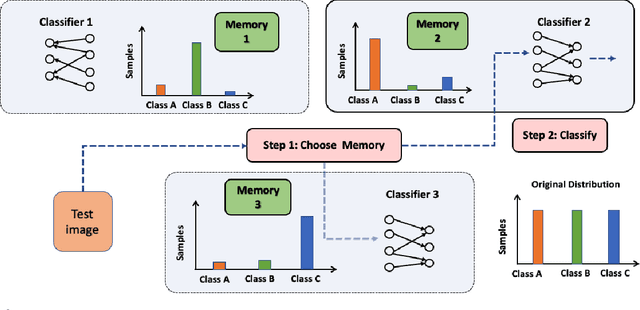
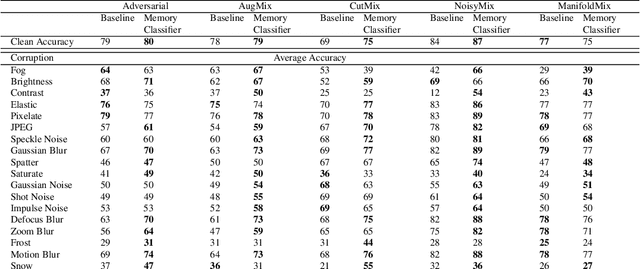
The performance of machine learning models can significantly degrade under distribution shifts of the data. We propose a new method for classification which can improve robustness to distribution shifts, by combining expert knowledge about the ``high-level" structure of the data with standard classifiers. Specifically, we introduce two-stage classifiers called \textit{memory classifiers}. First, these identify prototypical data points -- \textit{memories} -- to cluster the training data. This step is based on features designed with expert guidance; for instance, for image data they can be extracted using digital image processing algorithms. Then, within each cluster, we learn local classifiers based on finer discriminating features, via standard models like deep neural networks. We establish generalization bounds for memory classifiers. We illustrate in experiments that they can improve generalization and robustness to distribution shifts on image datasets. We show improvements which push beyond standard data augmentation techniques.
Collaborative Learning of Distributions under Heterogeneity and Communication Constraints
Jun 07, 2022
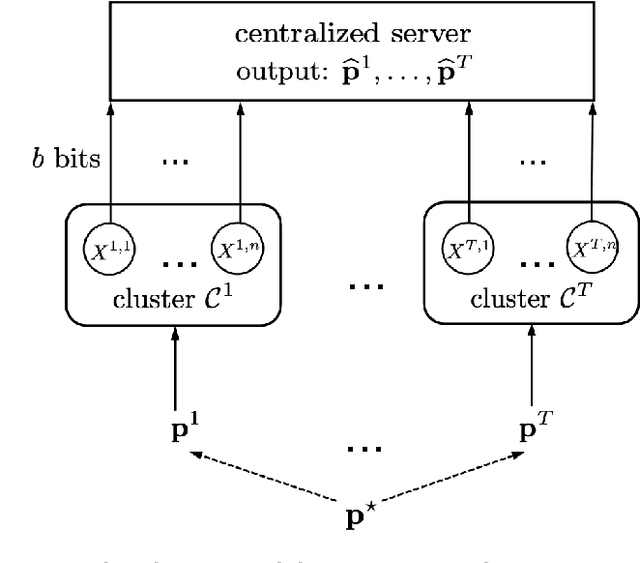
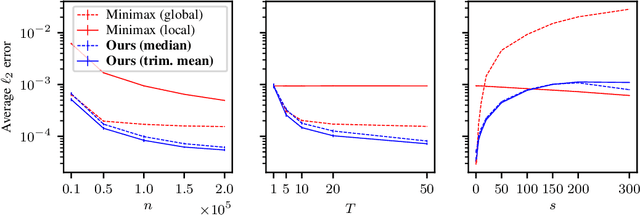
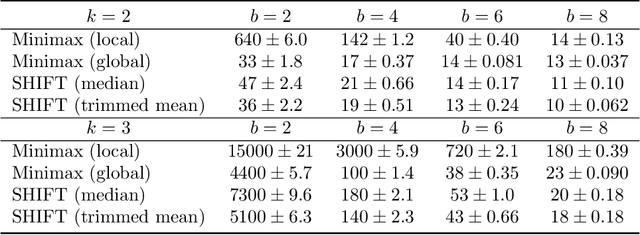
In modern machine learning, users often have to collaborate to learn the distribution of the data. Communication can be a significant bottleneck. Prior work has studied homogeneous users -- i.e., whose data follow the same discrete distribution -- and has provided optimal communication-efficient methods for estimating that distribution. However, these methods rely heavily on homogeneity, and are less applicable in the common case when users' discrete distributions are heterogeneous. Here we consider a natural and tractable model of heterogeneity, where users' discrete distributions only vary sparsely, on a small number of entries. We propose a novel two-stage method named SHIFT: First, the users collaborate by communicating with the server to learn a central distribution; relying on methods from robust statistics. Then, the learned central distribution is fine-tuned to estimate their respective individual distribution. We show that SHIFT is minimax optimal in our model of heterogeneity and under communication constraints. Further, we provide experimental results using both synthetic data and $n$-gram frequency estimation in the text domain, which corroborate its efficiency.
PAC-Wrap: Semi-Supervised PAC Anomaly Detection
May 22, 2022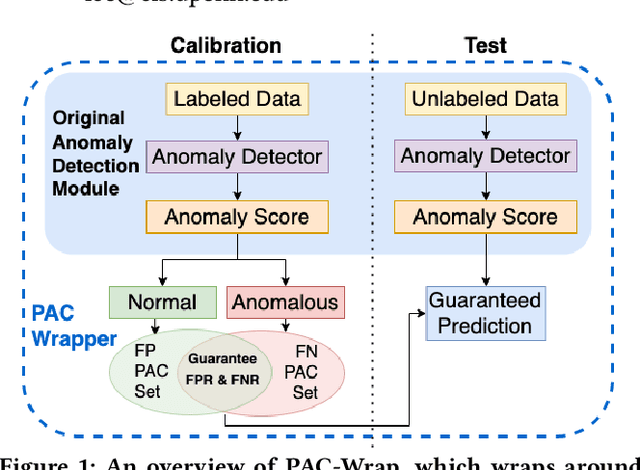
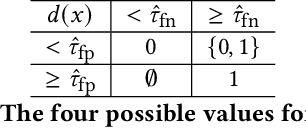
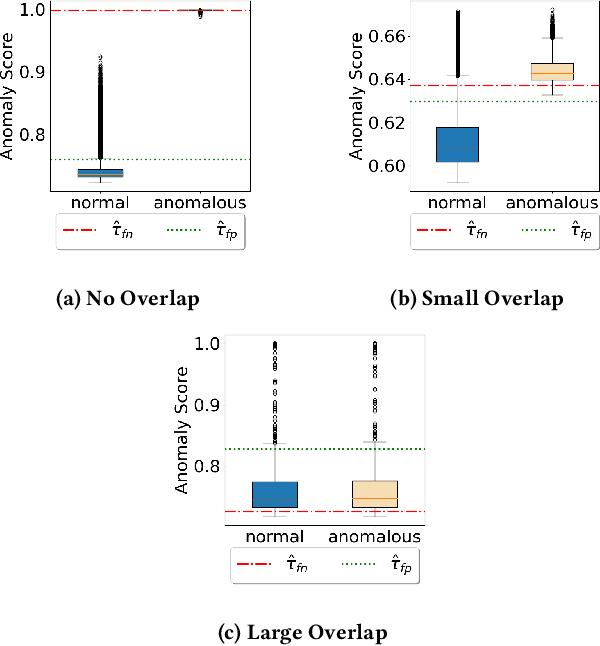
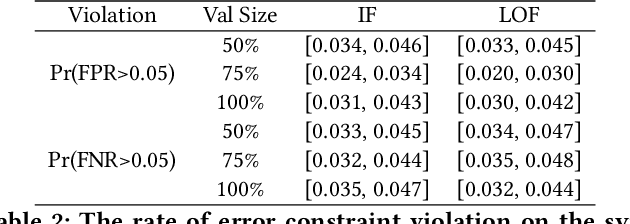
Anomaly detection is essential for preventing hazardous outcomes for safety-critical applications like autonomous driving. Given their safety-criticality, these applications benefit from provable bounds on various errors in anomaly detection. To achieve this goal in the semi-supervised setting, we propose to provide Probably Approximately Correct (PAC) guarantees on the false negative and false positive detection rates for anomaly detection algorithms. Our method (PAC-Wrap) can wrap around virtually any existing semi-supervised and unsupervised anomaly detection method, endowing it with rigorous guarantees. Our experiments with various anomaly detectors and datasets indicate that PAC-Wrap is broadly effective.
Fair Bayes-Optimal Classifiers Under Predictive Parity
May 15, 2022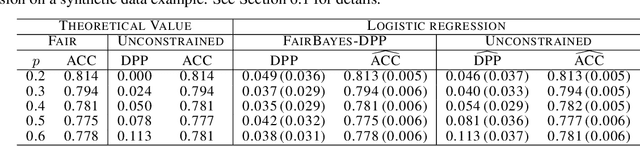
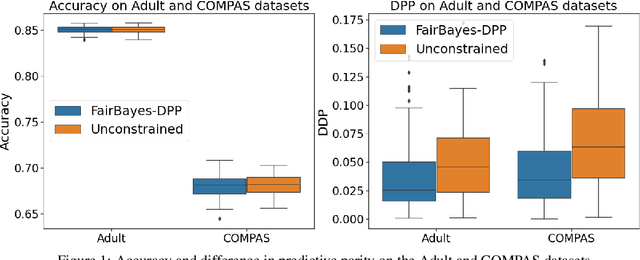
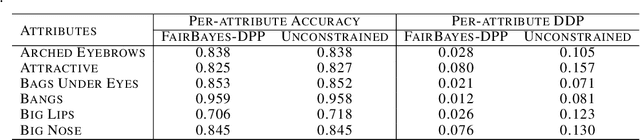
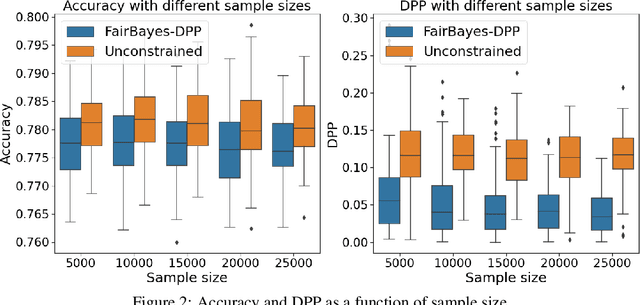
Increasing concerns about disparate effects of AI have motivated a great deal of work on fair machine learning. Existing works mainly focus on independence- and separation-based measures (e.g., demographic parity, equality of opportunity, equalized odds), while sufficiency-based measures such as predictive parity are much less studied. This paper considers predictive parity, which requires equalizing the probability of success given a positive prediction among different protected groups. We prove that, if the overall performances of different groups vary only moderately, all fair Bayes-optimal classifiers under predictive parity are group-wise thresholding rules. Perhaps surprisingly, this may not hold if group performance levels vary widely; in this case we find that predictive parity among protected groups may lead to within-group unfairness. We then propose an algorithm we call FairBayes-DPP, aiming to ensure predictive parity when our condition is satisfied. FairBayes-DPP is an adaptive thresholding algorithm that aims to achieve predictive parity, while also seeking to maximize test accuracy. We provide supporting experiments conducted on synthetic and empirical data.
SE(3)-Equivariant Attention Networks for Shape Reconstruction in Function Space
Apr 05, 2022
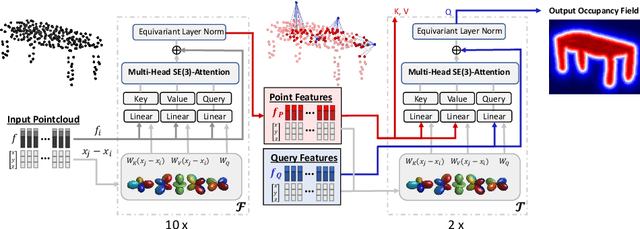
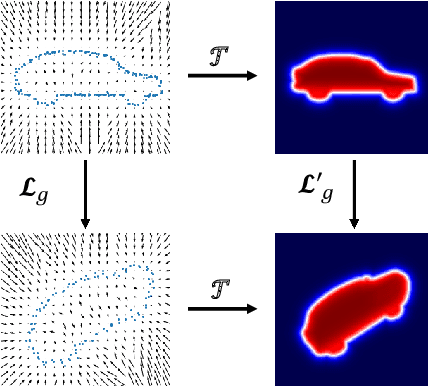
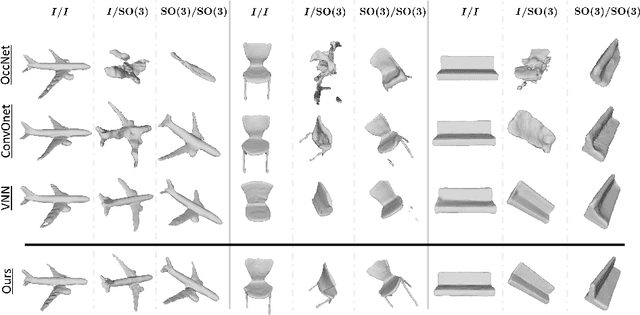
We propose the first SE(3)-equivariant coordinate-based network for learning occupancy fields from point clouds. In contrast to previous shape reconstruction methods that align the input to a regular grid, we operate directly on the irregular, unoriented point cloud. We leverage attention mechanisms in order to preserve the set structure (permutation equivariance and variable length) of the input. At the same time, attention layers enable local shape modelling, a crucial property for scalability to large scenes. In contrast to architectures that create a global signature for the shape, we operate on local tokens. Given an unoriented, sparse, noisy point cloud as input, we produce equivariant features for each point. These serve as keys and values for the subsequent equivariant cross-attention blocks that parametrize the occupancy field. By querying an arbitrary point in space, we predict its occupancy score. We show that our method outperforms previous SO(3)-equivariant methods, as well as non-equivariant methods trained on SO(3)-augmented datasets. More importantly, local modelling together with SE(3)-equivariance create an ideal setting for SE(3) scene reconstruction. We show that by training only on single objects and without any pre-segmentation, we can reconstruct a novel scene with single-object performance.
T-Cal: An optimal test for the calibration of predictive models
Mar 25, 2022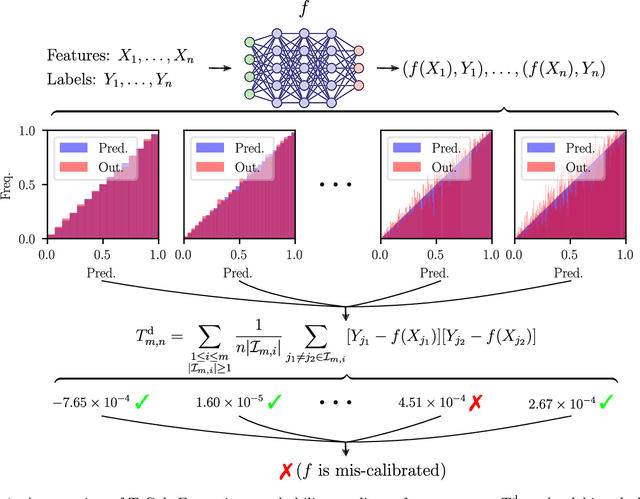
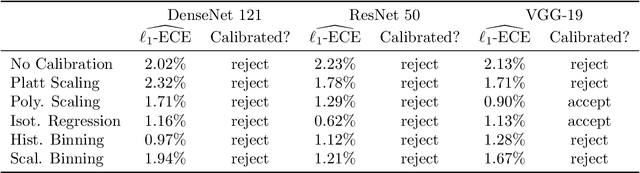
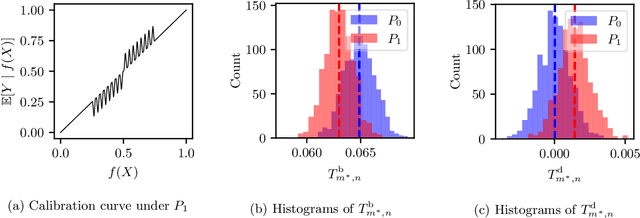
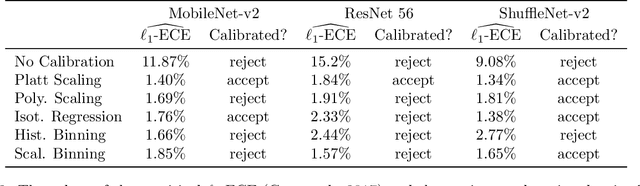
The prediction accuracy of machine learning methods is steadily increasing, but the calibration of their uncertainty predictions poses a significant challenge. Numerous works focus on obtaining well-calibrated predictive models, but less is known about reliably assessing model calibration. This limits our ability to know when algorithms for improving calibration have a real effect, and when their improvements are merely artifacts due to random noise in finite datasets. In this work, we consider detecting mis-calibration of predictive models using a finite validation dataset as a hypothesis testing problem. The null hypothesis is that the predictive model is calibrated, while the alternative hypothesis is that the deviation from calibration is sufficiently large. We find that detecting mis-calibration is only possible when the conditional probabilities of the classes are sufficiently smooth functions of the predictions. When the conditional class probabilities are H\"older continuous, we propose T-Cal, a minimax optimal test for calibration based on a debiased plug-in estimator of the $\ell_2$-Expected Calibration Error (ECE). We further propose Adaptive T-Cal, a version that is adaptive to unknown smoothness. We verify our theoretical findings with a broad range of experiments, including with several popular deep neural net architectures and several standard post-hoc calibration methods. T-Cal is a practical general-purpose tool, which -- combined with classical tests for discrete-valued predictors -- can be used to test the calibration of virtually any probabilistic classification method.
Distribution-free Prediction Sets Adaptive to Unknown Covariate Shift
Mar 11, 2022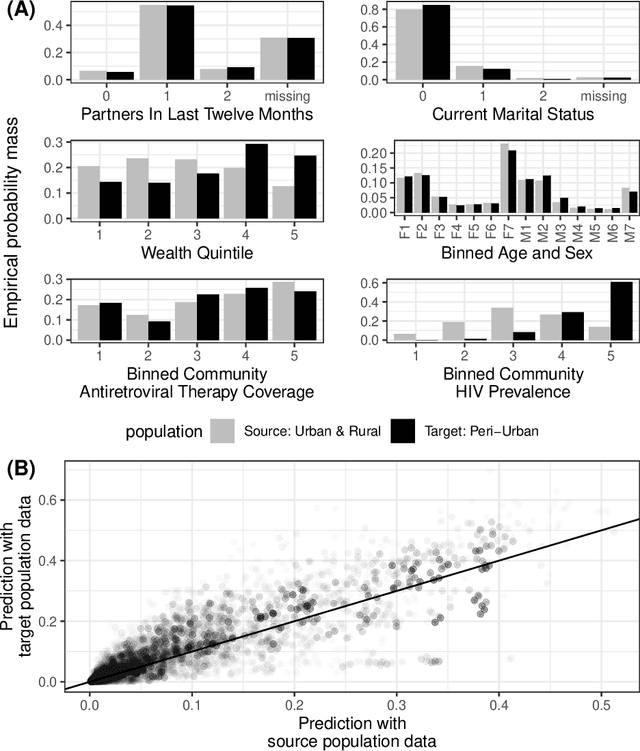
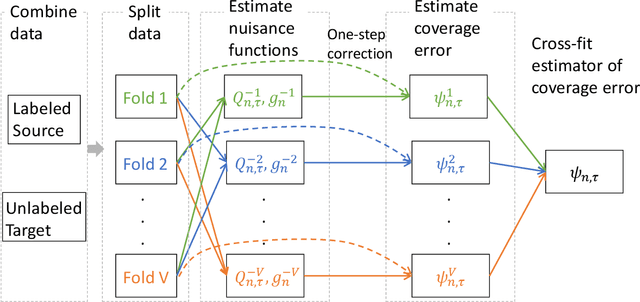

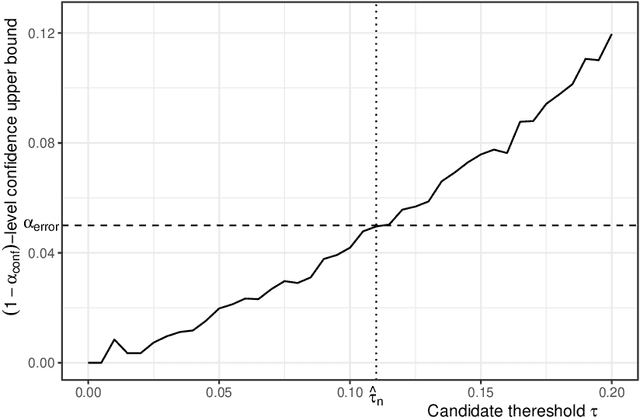
Predicting sets of outcomes -- instead of unique outcomes -- is a promising solution to uncertainty quantification in statistical learning. Despite a rich literature on constructing prediction sets with statistical guarantees, adapting to unknown covariate shift -- a prevalent issue in practice -- poses a serious challenge and has yet to be solved. In the framework of semiparametric statistics, we can view the covariate shift as a nuisance parameter. In this paper, we propose a novel flexible distribution-free method, PredSet-1Step, to construct prediction sets that can efficiently adapt to unknown covariate shift. PredSet-1Step relies on a one-step correction of the plug-in estimator of coverage error. We theoretically show that our methods are asymptotically probably approximately correct (PAC), having low coverage error with high confidence for large samples. PredSet-1Step may also be used to construct asymptotically risk-controlling prediction sets. We illustrate that our method has good coverage in a number of experiments and by analyzing a data set concerning HIV risk prediction in a South African cohort study. In experiments without covariate shift, PredSet-1Step performs similarly to inductive conformal prediction, which has finite-sample PAC properties. Thus, PredSet-1Step may be used in the common scenario if the user suspects -- but may not be certain -- that covariate shift is present, and does not know the form of the shift. Our theory hinges on a new bound for the convergence rate of Wald confidence interval coverage for general asymptotically linear estimators. This is a technical tool of independent interest.
Bayes-Optimal Classifiers under Group Fairness
Mar 11, 2022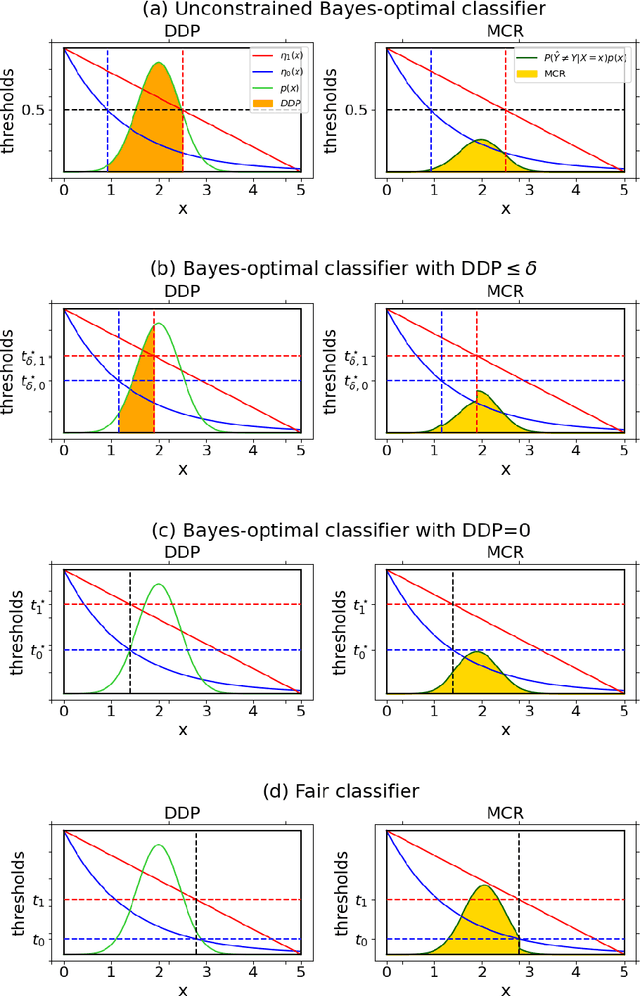
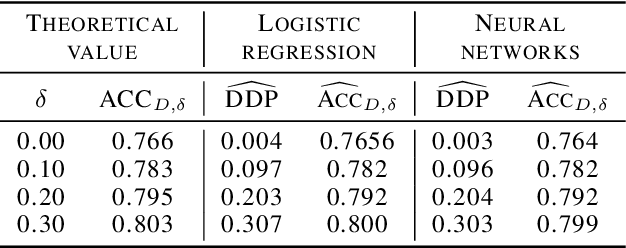
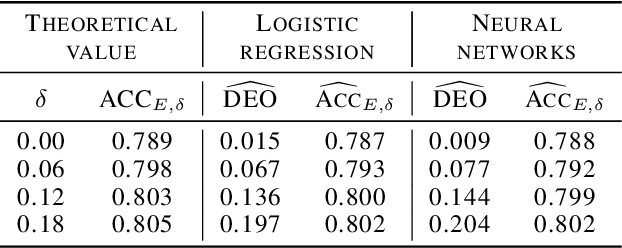
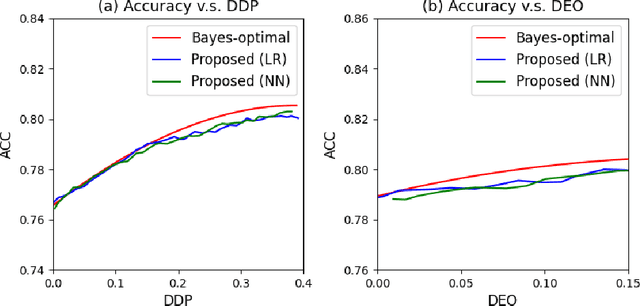
Machine learning algorithms are becoming integrated into more and more high-stakes decision-making processes, such as in social welfare issues. Due to the need of mitigating the potentially disparate impacts from algorithmic predictions, many approaches have been proposed in the emerging area of fair machine learning. However, the fundamental problem of characterizing Bayes-optimal classifiers under various group fairness constraints has only been investigated in some special cases. Based on the classical Neyman-Pearson argument (Neyman and Pearson, 1933; Shao, 2003) for optimal hypothesis testing, this paper provides a unified framework for deriving Bayes-optimal classifiers under group fairness. This enables us to propose a group-based thresholding method that can directly control disparity, and more importantly, achieve an optimal fairness-accuracy tradeoff. These advantages are supported by experiments.
Exploring with Sticky Mittens: Reinforcement Learning with Expert Interventions via Option Templates
Feb 25, 2022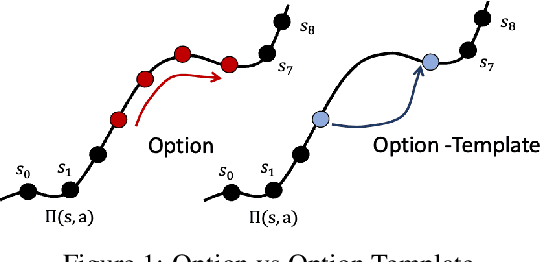
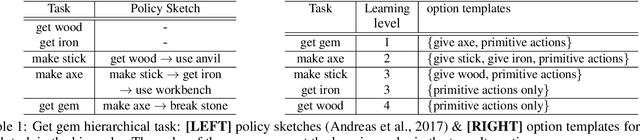
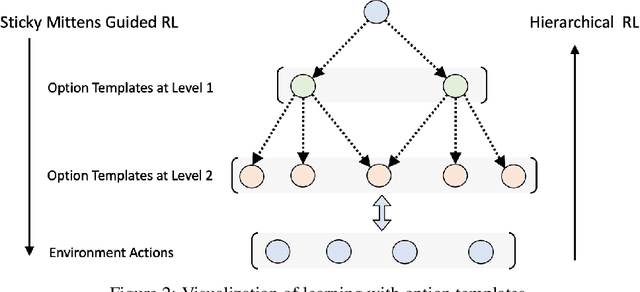
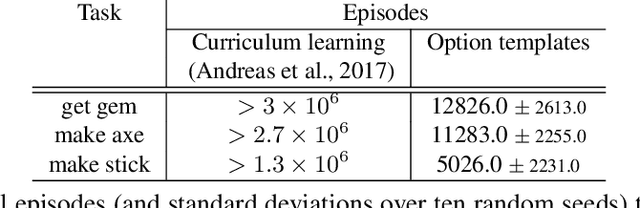
Environments with sparse rewards and long horizons pose a significant challenge for current reinforcement learning algorithms. A key feature enabling humans to learn challenging control tasks is that they often receive expert intervention that enables them to understand the high-level structure of the task before mastering low-level control actions. We propose a framework for leveraging expert intervention to solve long-horizon reinforcement learning tasks. We consider option templates, which are specifications encoding a potential option that can be trained using reinforcement learning. We formulate expert intervention as allowing the agent to execute option templates before learning an implementation. This enables them to use an option, before committing costly resources to learning it. We evaluate our approach on three challenging reinforcement learning problems, showing that it outperforms state of-the-art approaches by an order of magnitude. Project website at https://sites.google.com/view/stickymittens
iDECODe: In-distribution Equivariance for Conformal Out-of-distribution Detection
Jan 07, 2022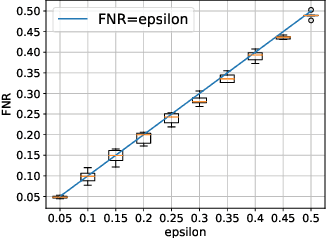
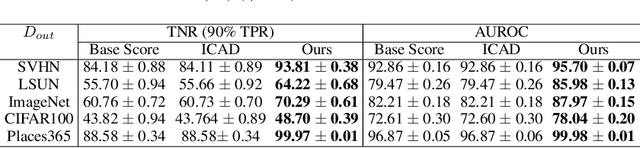

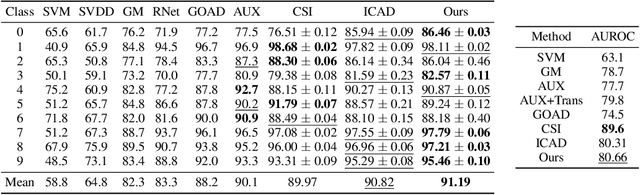
Machine learning methods such as deep neural networks (DNNs), despite their success across different domains, are known to often generate incorrect predictions with high confidence on inputs outside their training distribution. The deployment of DNNs in safety-critical domains requires detection of out-of-distribution (OOD) data so that DNNs can abstain from making predictions on those. A number of methods have been recently developed for OOD detection, but there is still room for improvement. We propose the new method iDECODe, leveraging in-distribution equivariance for conformal OOD detection. It relies on a novel base non-conformity measure and a new aggregation method, used in the inductive conformal anomaly detection framework, thereby guaranteeing a bounded false detection rate. We demonstrate the efficacy of iDECODe by experiments on image and audio datasets, obtaining state-of-the-art results. We also show that iDECODe can detect adversarial examples.