 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing guidance for missing data in diffusion-based sequential recommendation
Jan 22, 2026Contemporary sequential recommendation methods are becoming more complex, shifting from classification to a diffusion-guided generative paradigm. However, the quality of guidance in the form of user information is often compromised by missing data in the observed sequences, leading to suboptimal generation quality. Existing methods address this by removing locally similar items, but overlook ``critical turning points'' in user interest, which are crucial for accurately predicting subsequent user intent. To address this, we propose a novel Counterfactual Attention Regulation Diffusion model (CARD), which focuses on amplifying the signal from key interest-turning-point items while concurrently identifying and suppressing noise within the user sequence. CARD consists of (1) a Dual-side Thompson Sampling method to identify sequences undergoing significant interest shift, and (2) a counterfactual attention mechanism for these sequences to quantify the importance of each item. In this manner, CARD provides the diffusion model with a high-quality guidance signal composed of dynamically re-weighted interaction vectors to enable effective generation. Experiments show our method works well on real-world data without being computationally expensive. Our code is available at https://github.com/yanqilong3321/CARD.
Automated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025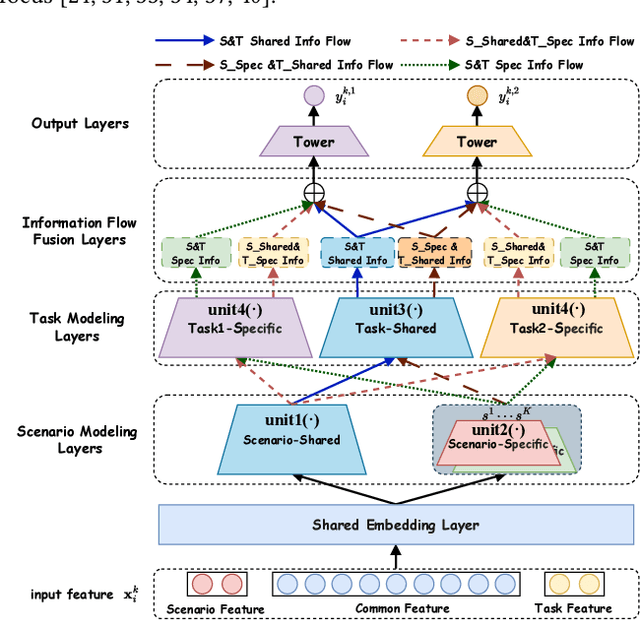
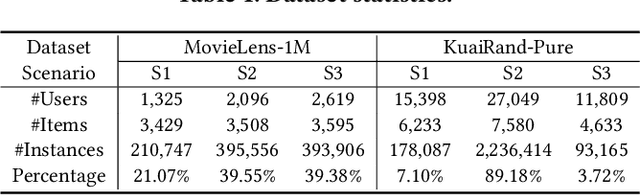
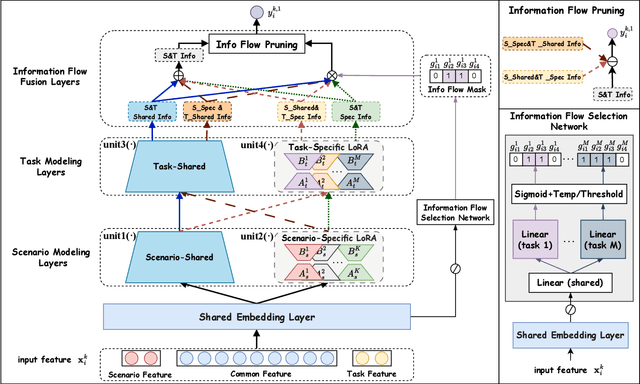
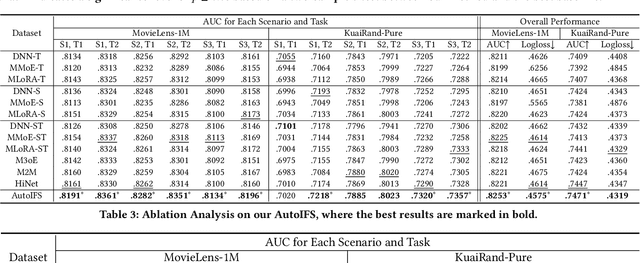
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
Beyond Higher Rank: Token-wise Input-Output Projections for Efficient Low-Rank Adaptation
Oct 27, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). LoRA essentially describes the projection of an input space into a low-dimensional output space, with the dimensionality determined by the LoRA rank. In standard LoRA, all input tokens share the same weights and undergo an identical input-output projection. This limits LoRA's ability to capture token-specific information due to the inherent semantic differences among tokens. To address this limitation, we propose Token-wise Projected Low-Rank Adaptation (TopLoRA), which dynamically adjusts LoRA weights according to the input token, thereby learning token-wise input-output projections in an end-to-end manner. Formally, the weights of TopLoRA can be expressed as $B\Sigma_X A$, where $A$ and $B$ are low-rank matrices (as in standard LoRA), and $\Sigma_X$ is a diagonal matrix generated from each input token $X$. Notably, TopLoRA does not increase the rank of LoRA weights but achieves more granular adaptation by learning token-wise LoRA weights (i.e., token-wise input-output projections). Extensive experiments across multiple models and datasets demonstrate that TopLoRA consistently outperforms LoRA and its variants. The code is available at https://github.com/Leopold1423/toplora-neurips25.
See&Trek: Training-Free Spatial Prompting for Multimodal Large Language Model
Sep 19, 2025We introduce SEE&TREK, the first training-free prompting framework tailored to enhance the spatial understanding of Multimodal Large Language Models (MLLMS) under vision-only constraints. While prior efforts have incorporated modalities like depth or point clouds to improve spatial reasoning, purely visualspatial understanding remains underexplored. SEE&TREK addresses this gap by focusing on two core principles: increasing visual diversity and motion reconstruction. For visual diversity, we conduct Maximum Semantic Richness Sampling, which employs an off-the-shell perception model to extract semantically rich keyframes that capture scene structure. For motion reconstruction, we simulate visual trajectories and encode relative spatial positions into keyframes to preserve both spatial relations and temporal coherence. Our method is training&GPU-free, requiring only a single forward pass, and can be seamlessly integrated into existing MLLM'S. Extensive experiments on the VSI-B ENCH and STI-B ENCH show that S EE &T REK consistently boosts various MLLM S performance across diverse spatial reasoning tasks with the most +3.5% improvement, offering a promising path toward stronger spatial intelligence.
BoRA: Towards More Expressive Low-Rank Adaptation with Block Diversity
Aug 09, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). It approximates the update of a pretrained weight matrix $W\in\mathbb{R}^{m\times n}$ by the product of two low-rank matrices, $BA$, where $A \in\mathbb{R}^{r\times n}$ and $B\in\mathbb{R}^{m\times r} (r\ll\min\{m,n\})$. Increasing the dimension $r$ can raise the rank of LoRA weights (i.e., $BA$), which typically improves fine-tuning performance but also significantly increases the number of trainable parameters. In this paper, we propose Block Diversified Low-Rank Adaptation (BoRA), which improves the rank of LoRA weights with a small number of additional parameters. Specifically, BoRA treats the product $BA$ as a block matrix multiplication, where $A$ and $B$ are partitioned into $b$ blocks along the columns and rows, respectively (i.e., $A=[A_1,\dots,A_b]$ and $B=[B_1,\dots,B_b]^\top$). Consequently, the product $BA$ becomes the concatenation of the block products $B_iA_j$ for $i,j\in[b]$. To enhance the diversity of different block products, BoRA introduces a unique diagonal matrix $\Sigma_{i,j} \in \mathbb{R}^{r\times r}$ for each block multiplication, resulting in $B_i \Sigma_{i,j} A_j$. By leveraging these block-wise diagonal matrices, BoRA increases the rank of LoRA weights by a factor of $b$ while only requiring $b^2r$ additional parameters. Extensive experiments across multiple datasets and models demonstrate the superiority of BoRA, and ablation studies further validate its scalability.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
Mar 06, 2025Sequential recommendation aims to model user preferences based on historical behavior sequences, which is crucial for various online platforms. Data sparsity remains a significant challenge in this area as most users have limited interactions and many items receive little attention. To mitigate this issue, contrastive learning has been widely adopted. By constructing positive sample pairs from the data itself and maximizing their agreement in the embedding space,it can leverage available data more effectively. Constructing reasonable positive sample pairs is crucial for the success of contrastive learning. However, current approaches struggle to generate reliable positive pairs as they either rely on representations learned from inherently sparse collaborative signals or use random perturbations which introduce significant uncertainty. To address these limitations, we propose a novel approach named Semantic Retrieval Augmented Contrastive Learning (SRA-CL), which leverages semantic information to improve the reliability of contrastive samples. SRA-CL comprises two main components: (1) Cross-Sequence Contrastive Learning via User Semantic Retrieval, which utilizes large language models (LLMs) to understand diverse user preferences and retrieve semantically similar users to form reliable positive samples through a learnable sample synthesis method; and (2) Intra-Sequence Contrastive Learning via Item Semantic Retrieval, which employs LLMs to comprehend items and retrieve similar items to perform semantic-based item substitution, thereby creating semantically consistent augmented views for contrastive learning. SRA-CL is plug-and-play and can be integrated into standard sequential recommendation models. Extensive experiments on four public datasets demonstrate the effectiveness and generalizability of the proposed approach.
A Predict-Then-Optimize Customer Allocation Framework for Online Fund Recommendation
Mar 05, 2025With the rapid growth of online investment platforms, funds can be distributed to individual customers online. The central issue is to match funds with potential customers under constraints. Most mainstream platforms adopt the recommendation formulation to tackle the problem. However, the traditional recommendation regime has its inherent drawbacks when applying the fund-matching problem with multiple constraints. In this paper, we model the fund matching under the allocation formulation. We design PTOFA, a Predict-Then-Optimize Fund Allocation framework. This data-driven framework consists of two stages, i.e., prediction and optimization, which aim to predict expected revenue based on customer behavior and optimize the impression allocation to achieve the maximum revenue under the necessary constraints, respectively. Extensive experiments on real-world datasets from an industrial online investment platform validate the effectiveness and efficiency of our solution. Additionally, the online A/B tests demonstrate PTOFA's effectiveness in the real-world fund recommendation scenario.
Fusion Matters: Learning Fusion in Deep Click-through Rate Prediction Models
Nov 24, 2024



The evolution of previous Click-Through Rate (CTR) models has mainly been driven by proposing complex components, whether shallow or deep, that are adept at modeling feature interactions. However, there has been less focus on improving fusion design. Instead, two naive solutions, stacked and parallel fusion, are commonly used. Both solutions rely on pre-determined fusion connections and fixed fusion operations. It has been repetitively observed that changes in fusion design may result in different performances, highlighting the critical role that fusion plays in CTR models. While there have been attempts to refine these basic fusion strategies, these efforts have often been constrained to specific settings or dependent on specific components. Neural architecture search has also been introduced to partially deal with fusion design, but it comes with limitations. The complexity of the search space can lead to inefficient and ineffective results. To bridge this gap, we introduce OptFusion, a method that automates the learning of fusion, encompassing both the connection learning and the operation selection. We have proposed a one-shot learning algorithm tackling these tasks concurrently. Our experiments are conducted over three large-scale datasets. Extensive experiments prove both the effectiveness and efficiency of OptFusion in improving CTR model performance. Our code implementation is available here\url{https://github.com/kexin-kxzhang/OptFusion}.
Comprehending Knowledge Graphs with Large Language Models for Recommender Systems
Oct 16, 2024Recently, the introduction of knowledge graphs (KGs) has significantly advanced recommender systems by facilitating the discovery of potential associations between items. However, existing methods still face several limitations. First, most KGs suffer from missing facts or limited scopes. This can lead to biased knowledge representations, thereby constraining the model's performance. Second, existing methods typically convert textual information into IDs, resulting in the loss of natural semantic connections between different items. Third, existing methods struggle to capture high-order relationships in global KGs due to their inefficient layer-by-layer information propagation mechanisms, which are prone to introducing significant noise. To address these limitations, we propose a novel method called CoLaKG, which leverages large language models (LLMs) for knowledge-aware recommendation. The extensive world knowledge and remarkable reasoning capabilities of LLMs enable them to supplement KGs. Additionally, the strong text comprehension abilities of LLMs allow for a better understanding of semantic information. Based on this, we first extract subgraphs centered on each item from the KG and convert them into textual inputs for the LLM. The LLM then outputs its comprehension of these item-centered subgraphs, which are subsequently transformed into semantic embeddings. Furthermore, to utilize the global information of the KG, we construct an item-item graph using these semantic embeddings, which can directly capture higher-order associations between items. Both the semantic embeddings and the structural information from the item-item graph are effectively integrated into the recommendation model through our designed representation alignment and neighbor augmentation modules. Extensive experiments on four real-world datasets demonstrate the superiority of our method.
OptDist: Learning Optimal Distribution for Customer Lifetime Value Prediction
Aug 16, 2024



Customer Lifetime Value (CLTV) prediction is a critical task in business applications. Accurately predicting CLTV is challenging in real-world business scenarios, as the distribution of CLTV is complex and mutable. Firstly, there is a large number of users without any consumption consisting of a long-tailed part that is too complex to fit. Secondly, the small set of high-value users spent orders of magnitude more than a typical user leading to a wide range of the CLTV distribution which is hard to capture in a single distribution. Existing approaches for CLTV estimation either assume a prior probability distribution and fit a single group of distribution-related parameters for all samples, or directly learn from the posterior distribution with manually predefined buckets in a heuristic manner. However, all these methods fail to handle complex and mutable distributions. In this paper, we propose a novel optimal distribution selection model OptDist for CLTV prediction, which utilizes an adaptive optimal sub-distribution selection mechanism to improve the accuracy of complex distribution modeling. Specifically, OptDist trains several candidate sub-distribution networks in the distribution learning module (DLM) for modeling the probability distribution of CLTV. Then, a distribution selection module (DSM) is proposed to select the sub-distribution for each sample, thus making the selection automatically and adaptively. Besides, we design an alignment mechanism that connects both modules, which effectively guides the optimization. We conduct extensive experiments on both two public and one private dataset to verify that OptDist outperforms state-of-the-art baselines. Furthermore, OptDist has been deployed on a large-scale financial platform for customer acquisition marketing campaigns and the online experiments also demonstrate the effectiveness of OptDist.